AWS Big Data Blog

How Fannie Mae built a data mesh architecture to enable self-service using Amazon Redshift data sharing
This post is co-written by Kiran Ramineni and Basava Hubli, from Fannie Mae. Amazon Redshift data sharing enables instant, granular, and fast data access across Amazon Redshift clusters without the need to copy or move data around. Data sharing provides live access to data so that users always see the most up-to-date and transactionally consistent […]

Set up federated access to Amazon Athena for Microsoft AD FS users using AWS Lake Formation and a JDBC client
Tens of thousands of AWS customers choose Amazon Simple Storage Service (Amazon S3) as their data lake to run big data analytics, interactive queries, high-performance computing, and artificial intelligence (AI) and machine learning (ML) applications to gain business insights from their data. On top of these data lakes, you can use AWS Lake Formation to […]

Amazon Redshift data sharing best practices and considerations
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift data sharing allows for a secure and easy way to share live data for reading across Amazon Redshift clusters. It allows an […]

New row and column interactivity options for tables and pivot tables in Amazon QuickSight – Part 1
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to create and deliver insights to everyone in your organization. You can make your data come to life with rich interactive charts and create beautiful dashboards to share with thousands of users, either directly within a QuickSight application, or embedded in […]

Introducing AWS Glue interactive sessions for Jupyter
Interactive Sessions for Jupyter is a new notebook interface in the AWS Glue serverless Spark environment. Starting in seconds and automatically stopping compute when idle, interactive sessions provide an on-demand, highly-scalable, serverless Spark backend to Jupyter notebooks and Jupyter-based IDEs such as Jupyter Lab, Microsoft Visual Studio Code, JetBrains PyCharm, and more. Interactive sessions replace […]
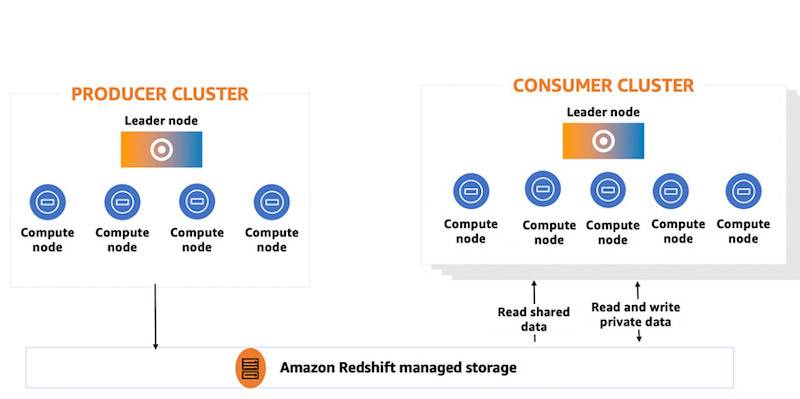
From centralized architecture to decentralized architecture: How data sharing fine-tunes Amazon Redshift workloads
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. With the significant growth of data for big […]

Configure Hadoop YARN CapacityScheduler on Amazon EMR on Amazon EC2 for multi-tenant heterogeneous workloads
Apache Hadoop YARN (Yet Another Resource Negotiator) is a cluster resource manager responsible for assigning computational resources (CPU, memory, I/O), and scheduling and monitoring jobs submitted to a Hadoop cluster. This generic framework allows for effective management of cluster resources for distributed data processing frameworks, such as Apache Spark, Apache MapReduce, and Apache Hive. When […]

Build a resilient Amazon Redshift architecture with automatic recovery enabled
Amazon Redshift provides resiliency in the event of a single point of failure in a cluster, including automatically detecting and recovering from drive and node failures. The Amazon Redshift relocation feature adds an additional level of availability, and this post is focused on explaining this automatic recovery feature. When the cluster relocation feature is enabled […]
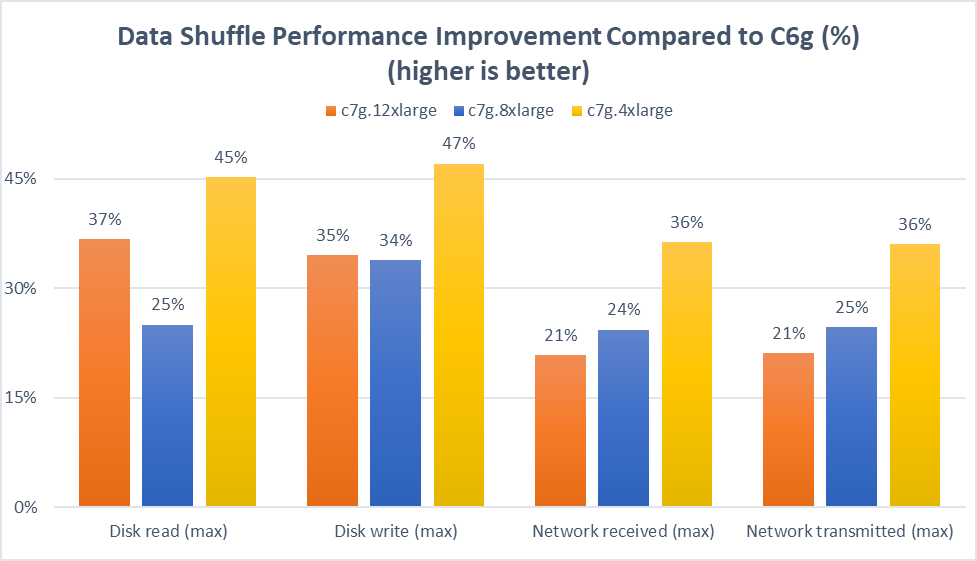
Amazon EMR on EKS gets up to 19% performance boost running on AWS Graviton3 Processors vs. Graviton2
Amazon EMR on EKS is a deployment option that enables you to run Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) easily. It allows you to innovate faster with the latest Apache Spark on Kubernetes architecture while benefiting from the performance-optimized Spark runtime powered by Amazon EMR. This deployment option elects Amazon EKS as […]

AWS Glue Python shell now supports Python 3.9 with a flexible pre-loaded environment and support to install additional libraries
AWS Glue is the central service of an AWS modern data architecture. It is a serverless data integration service that allows you to discover, prepare, and combine data for analytics and machine learning. AWS Glue offers you a comprehensive range of tools to perform ETL (extract, transform, and load) at the right scale. AWS Glue […]