AWS Big Data Blog
How Fannie Mae built a data mesh architecture to enable self-service using Amazon Redshift data sharing
This post is co-written by Kiran Ramineni and Basava Hubli, from Fannie Mae.
Amazon Redshift data sharing enables instant, granular, and fast data access across Amazon Redshift clusters without the need to copy or move data around. Data sharing provides live access to data so that users always see the most up-to-date and transactionally consistent views of data across all consumers as data is updated in the producer. You can share live data securely with Amazon Redshift clusters in the same or different AWS accounts, and across Regions. Data sharing enables secure and governed collaboration within and across organizations as well as external parties.
In this post, we see how Fannie Mae implemented a data mesh architecture using Amazon Redshift cross-account data sharing to break down the silos in data warehouses across business units.
About Fannie Mae
Chartered by U.S. Congress in 1938, Fannie Mae advances equitable and sustainable access to homeownership and quality, affordable rental housing for millions of people across America. Fannie Mae enables the 30-year fixed-rate mortgage and drives responsible innovation to make homebuying and renting easier, fairer, and more accessible. We are focused on increasing operational agility and efficiency, accelerating the digital transformation of the company to deliver more value and reliable, modern platforms in support of the broader housing finance system.
Background
To fulfill the mission of facilitating equitable and sustainable access to homeownership and quality, affordable rental housing across America, Fannie Mae embraced a modern cloud-based architecture which leverages data to drive actionable insights and business decisions. As part of the modernization strategy, we embarked on a journey to migrate our legacy on-premises workloads to AWS cloud including managed services such as Amazon Redshift and Amazon S3. The modern data platform on AWS cloud serves as the central data store for analytics, research, and data science. In addition, this platform also serves for governance, regulatory and financial reports.
To address capacity, scalability and elasticity needs of a large data footprint of over 4PB, we decentralized and delegated ownership of the data stores and associated management functions to their respective business units. To enable decentralization, and efficient data access and management, we adopted a data mesh architecture.
Data mesh solution architecture
To enable a seamless access to data across accounts and business units, we looked at various options to build an architecture that is sustainable and scalable. The data mesh architecture allowed us to keep data of the respective business units in their own accounts, but yet enable a seamless access across the business unit accounts in a secure manner. We reorganized the AWS account structure to have separate accounts for each of the business units wherein, business data and dependent applications were collocated in their respective AWS Accounts.
With this decentralized model, the business units independently manage the responsibility of hydration, curation and security of their data. However, there is a critical need to enable seamless and efficient access to data across business units and an ability to govern the data usage. Amazon Redshift cross-account data sharing meets this need and enables us with business continuity.
To facilitate the self-serve capability on the data mesh, we built a web portal that allows for data discovery and ability to subscribe to data in the Amazon Redshift data warehouse and Amazon Simple Storage Service (Amazon S3) data lake (lake house). Once a consumer initiates a request on the web portal, an approval workflow is triggered with notification to the governance and business data owner. Upon successful completion of the request workflow, an automation process is triggered to grant access to the consumer, and a notification is sent to the consumer. Subsequently, the consumer is able to access the requested datasets. The workflow process of request, approval, and subsequent provisioning of access was automated using APIs and AWS Command Line Interface (AWS CLI) commands, and entire process is designed to complete within a few minutes.
With this new architecture using Amazon Redshift cross-account data sharing, we were able implement and benefit from the following key principles of a data mesh architecture that fit very well for our use case:
- A data as a product approach
- A federated model of data ownership
- The ability for consumers to subscribe using self-service data access
- Federated data governance with the ability to grant and revoke access
The following architecture diagram shows the high-level data mesh architecture we implemented at Fannie Mae. Data from each of the operational systems is collected and stored in individual lake houses and subscriptions are managed through a data mesh catalog in a centralized control plane account.
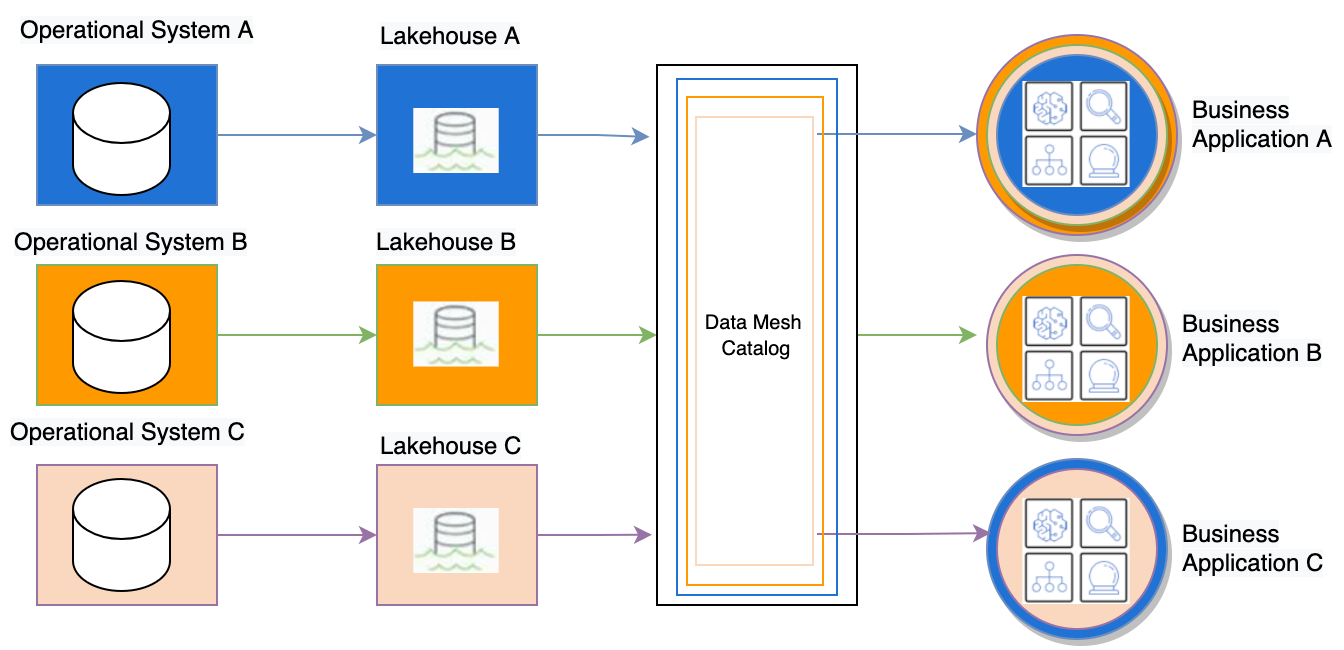
Fig 1. High level Data Mesh catalog architecture
Control plane for data mesh
With a redesigned account structure, data are spread out across separate accounts for each business application area in S3 data lake or in Amazon Redshift cluster. We designed a hub and spoke point-to-point data distribution scheme with a centralized semantic search to enhance the data relevance. We use a centralized control plane account to store the catalog information, contract detail, approval workflow policies, and access management details for the data mesh. With a policy driven access paradigm, we enable fine-grained access management to the data, where we automated Data as a Service enablement with an optimized approach. It has three modules to store and manage catalog, contracts, and access management.
Data catalog
The data catalog provides the data glossary and catalog information, and helps fully satisfy governance and security standards. With AWS Glue crawlers, we create the catalog for the lake house in a centralized control plane account, and then we automate the sharing process in a secure manner. This enables a query-based framework to pinpoint the exact location of the data. The data catalog collects the runtime information about the datasets for indexing purposes, and provides runtime metrics for analytics on dataset usage and access patterns. The catalog also provides a mechanism to update the catalog through automation as new datasets become available.
Contract registry
The contract registry hosts the policy engine, and uses Amazon DynamoDB to store the registry policies. This has the details on entitlements to physical mapping of data, and workflows for the access management process. We also use this to store and maintain the registry of existing data contracts and enable audit capability to determine and monitor the access patterns. In addition, the contract registry serves as the store for state management functionality.
Access management automation
Controlling and managing access to the dataset is done through access management. This provides a just-in-time data access through IAM session policies using a persona-driven approach. The access management module also hosts event notification for data, such as frequency of access or number of reads, and we then harness this information for data access lifecycle management. This module plays a critical role in the state management and provides extensive logging and monitoring capabilities on the state of the data.
Process flow of data mesh using Amazon Redshift cross-account data sharing
The process flow starts with creating a catalog of all datasets available in the control plane account. Consumers can request access to the data through a web front-end catalog, and the approval process is triggered through the central control plane account. The following architecture diagram represents the high-level implementation of Amazon Redshift data sharing via the data mesh architecture. The steps of the process flow are as follows:
- All the data products, Amazon Redshift tables, and S3 buckets are registered in a centralized AWS Glue Data Catalog.
- Data scientists and LOB users can browse the Data Catalog to find the data products available across all lake houses in Fannie Mae.
- Business applications can consume the data in other lake houses by registering a consumer contract. For example, LOB1-Lakehouse can register the contract to utilize data from LOB3-Lakehouse.
- The contract is reviewed and approved by the data producer, which subsequently triggers a technical event via Amazon Simple Service Notification (Amazon SNS).
- The subscribing AWS Lambda function runs AWS CLI commands, ACLs, and IAM policies to set up Amazon Redshift data sharing and make data available for consumers.
- Consumers can access the subscribed Amazon Redshift cluster data using their own cluster.

Fig 2. Data Mesh architecture using Amazon Redshift data sharing
The intention of this post is not to provide detailed steps for every aspect of creating the data mesh, but to provide a high-level overview of the architecture implemented, and how you can use various analytics services and third-party tools to create a scalable data mesh with Amazon Redshift and Amazon S3. If you want to try out creating this architecture, you can use these steps and automate the process using your tool of choice for the front-end user interface to enable users to subscribe to the dataset.
The steps we describe here are a simplified version of the actual implementation, so it doesn’t involve all the tools and accounts. To set up this scaled-down data mesh architecture, we demonstrate using cross-account data sharing using one control plane account and two consumer accounts. For this, you should have the following prerequisites:
- Three AWS accounts, one for the producer <ProducerAWSAccount1>, and two consumer accounts: <ConsumerAWSAccount1> and <ConsumerAWSAccount2>
- AWS permissions to provision Amazon Redshift and create an IAM role and policy
- The required Amazon Redshift clusters: one for the producer in the producer AWS account, a cluster in
ConsumerCluster1, and optionally a cluster inConsumerCluster2 - Two users in the producer account, and two users in consumer account 1:
- ProducerClusterAdmin – The Amazon Redshift user with admin access on the producer cluster
- ProducerCloudAdmin – The IAM user or role with rights to run
authorize-data-shareanddeauthorize-data-shareAWS CLI commands in the producer account - Consumer1ClusterAdmin – The Amazon Redshift user with admin access on the consumer cluster
- Consumer1CloudAdmin – The IAM user or role with rights to run
associate-data-share-consumeranddisassociate-data-share-consumerAWS CLI commands in the consumer account
Implement the solution
On the Amazon Redshift console, log in to the producer cluster and run the following statements using the query editor:
For sharing data across AWS accounts, you can use the following GRANT USAGE command. For authorizing the data share, typically it will be done by a manager or approver. In this case, we show how you can automate this process using the AWS CLI command authorize-data-share.
For the consumer to access the shared data from producer, an administrator on the consumer account needs to associate the data share with one or more clusters. This can be done using the Amazon Redshift console or AWS CLI commands. We provide the following AWS CLI command because this is how you can automate the process from the central control plane account:
To enable Amazon Redshift Spectrum cross-account access to AWS Glue and Amazon S3, and the IAM roles required, refer to How can I create Amazon Redshift Spectrum cross-account access to AWS Glue and Amazon S3.
Conclusion
Amazon Redshift data sharing provides a simple, seamless, and secure platform for sharing data in a domain-oriented distributed data mesh architecture. Fannie Mae deployed the Amazon Redshift data sharing capability across the data lake and data mesh platforms, which currently hosts over 4 petabytes worth of business data. The capability has been seamlessly integrated with their Just-In-Time (JIT) data provisioning framework enabling a single-click, persona-driven access to data. Further, Amazon Redshift data sharing coupled with Fannie Mae’s centralized, policy-driven data governance framework greatly simplified access to data in the lake ecosystem while fully conforming to the stringent data governance policies and standards. This demonstrates that Amazon Redshift users can create data share as product to distribute across many data domains.
In summary, Fannie Mae was able to successfully integrate the data sharing capability in their data ecosystem to bring efficiencies in data democratization and introduce a higher velocity, near real-time access to data across various business units. We encourage you to explore the data sharing feature of Amazon Redshift to build your own data mesh architecture and improve access to data for your business users.
About the authors
 Kiran Ramineni is Fannie Mae’s Vice President Head of Single Family, Cloud, Data, ML/AI & Infrastructure Architecture, reporting to the CTO and Chief Architect. Kiran and team spear headed cloud scalable Enterprise Data Mesh (Data Lake) with support for Just-In-Time (JIT), and Zero Trust as it applies to Citizen Data Scientist and Citizen Data Engineers. In the past Kiran built/lead several internet scalable always-on platforms.
Kiran Ramineni is Fannie Mae’s Vice President Head of Single Family, Cloud, Data, ML/AI & Infrastructure Architecture, reporting to the CTO and Chief Architect. Kiran and team spear headed cloud scalable Enterprise Data Mesh (Data Lake) with support for Just-In-Time (JIT), and Zero Trust as it applies to Citizen Data Scientist and Citizen Data Engineers. In the past Kiran built/lead several internet scalable always-on platforms.
 Basava Hubli is a Director & Lead Data/ML Architect at Enterprise Architecture. He oversees the Strategy and Architecture of Enterprise Data, Analytics and Data Science platforms at Fannie Mae. His primary focus is on Architecture Oversight and Delivery of Innovative technical capabilities that solve for critical Enterprise business needs. He leads a passionate and motivated team of architects who are driving the modernization and adoption of the Data, Analytics and ML platforms on Cloud. Under his leadership, Enterprise Architecture has successfully deployed several scalable, innovative platforms & capabilities that includes, a fully-governed Data Mesh which hosts peta-byte scale business data and a persona-driven, zero-trust based data access management framework which solves for the organization’s data democratization needs.
Basava Hubli is a Director & Lead Data/ML Architect at Enterprise Architecture. He oversees the Strategy and Architecture of Enterprise Data, Analytics and Data Science platforms at Fannie Mae. His primary focus is on Architecture Oversight and Delivery of Innovative technical capabilities that solve for critical Enterprise business needs. He leads a passionate and motivated team of architects who are driving the modernization and adoption of the Data, Analytics and ML platforms on Cloud. Under his leadership, Enterprise Architecture has successfully deployed several scalable, innovative platforms & capabilities that includes, a fully-governed Data Mesh which hosts peta-byte scale business data and a persona-driven, zero-trust based data access management framework which solves for the organization’s data democratization needs.
 Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide the direction of our product offerings.
Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide the direction of our product offerings.
 Kiran Sharma is a Senior Data Architect in AWS Professional Services. Kiran helps customers architecting, implementing and optimizing peta-byte scale Big Data Solutions on AWS.
Kiran Sharma is a Senior Data Architect in AWS Professional Services. Kiran helps customers architecting, implementing and optimizing peta-byte scale Big Data Solutions on AWS.