AWS Big Data Blog

Extract, Transform and Load data into S3 data lake using CTAS and INSERT INTO statements in Amazon Athena
April 2024: This post was reviewed for accuracy. Amazon Athena is an interactive query service that makes it easy to analyze the data stored in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. You can reduce your per-query […]

Connect Amazon Athena to your Apache Hive Metastore and use user-defined functions
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. This post details the two new preview features that you can start using today: connecting […]
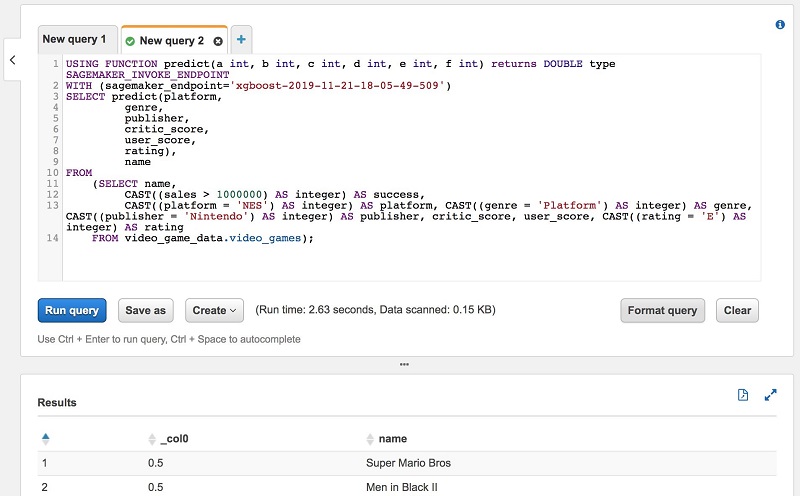
Prepare data for model-training and invoke machine learning models with Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Amazon Athena has announced a public preview of a new feature that provides an easy […]

Query any data source with Amazon Athena’s new federated query
April 2024: This post was reviewed for accuracy. Organizations today use data stores that are the best fit for the applications they build. For example, for an organization building a social network, a graph database such as Amazon Neptune is likely the best fit when compared to a relational database. Similarly, for workloads that require […]
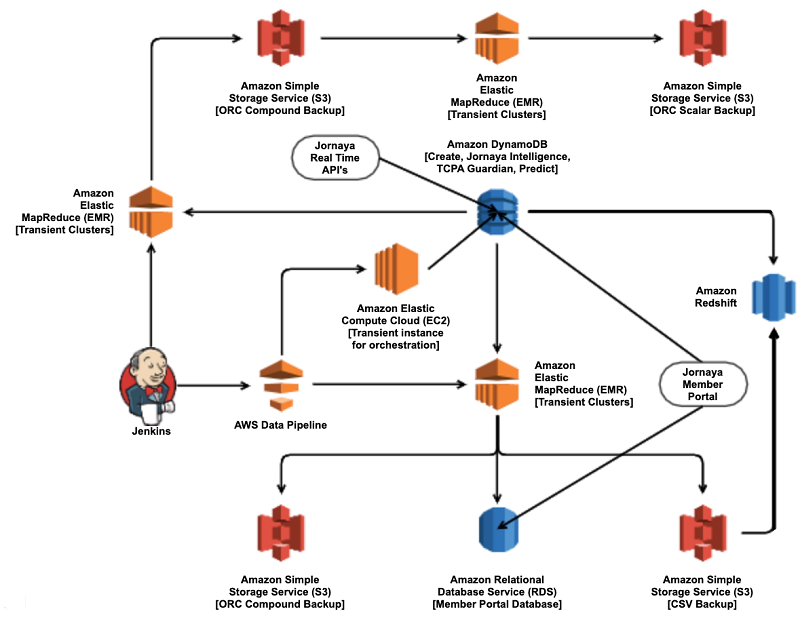
Simplify ETL data pipelines using Amazon Athena’s federated queries and user-defined functions
Amazon Athena recently added support for federated queries and user-defined functions (UDFs), both in Preview. See Query any data source with Amazon Athena’s new federated query for more details. Jornaya helps marketers intelligently connect consumers who are in the market for major life purchases such as homes, mortgages, cars, insurance, and education. Jornaya collects data […]

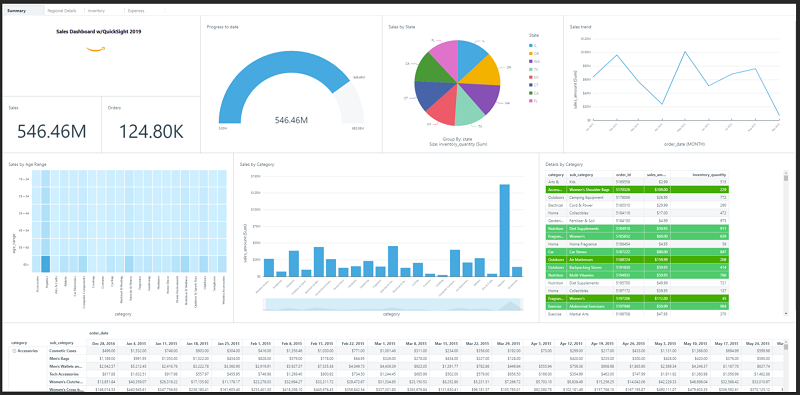
Highlight Critical Insights with Conditional Formatting in Amazon QuickSight
Amazon QuickSight now makes it easier for you to spot the highlights or low-lights in data through conditional formatting. With conditional formatting, you can specify customized text or background colors based on field values in the dataset, using solid or gradient colors. You can also display data values with the supported icons. Using color coding and […]
Evolve your analytics with Amazon QuickSight’s new APIs and theming capabilities
The Amazon QuickSight team is excited to announce the availability of Themes and more APIs! Themes for dashboards let you align the look and feel of Amazon QuickSight dashboards with your application’s branding or corporate themes. The new APIs added allow you to manage your Amazon QuickSight deployments programmatically, with support for dashboards, datasets, data sources, SPICE ingestion, and fine-grained access control over AWS resources. Together, they allow you to creatively tailor Amazon QuickSight to your audiences, whether you are using Amazon QuickSight to provide your users with an embedded analytics experience or for your corporate Business Intelligence (BI) needs. This post provides an overview of these new capabilities and details on getting started.
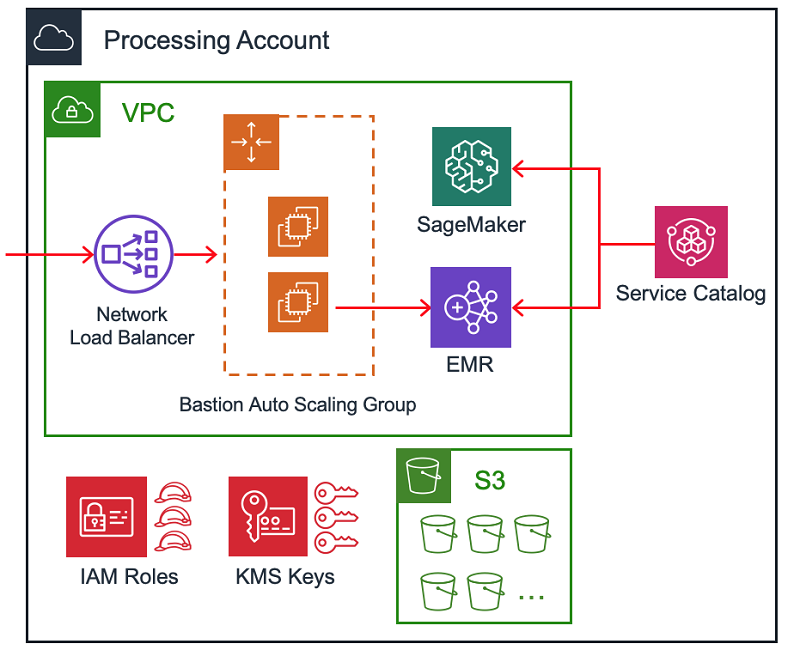
Provisioning the Intuit Data Lake with Amazon EMR, Amazon SageMaker, and AWS Service Catalog
This post outlines the approach taken by Intuit, though it is important to remember that there are many ways to build a data lake (for example, AWS Lake Formation). We’ll cover the technologies and processes involved in creating the Intuit Data Lake at a high level, including the overall structure and the automation used in provisioning accounts and resources. Watch this space in the future for more detailed blog posts on specific aspects of the system, from the other teams and engineers who worked together to build the Intuit Data Lake.

Amazon EMR introduces EMR runtime for Apache Spark
Amazon EMR is happy to announce Amazon EMR runtime for Apache Spark, a performance-optimized runtime environment for Apache Spark that is active by default on Amazon EMR clusters. EMR runtime for Spark is up to 32 times faster than EMR 5.16, with 100% API compatibility with open-source Spark. This means that your workloads run faster, […]
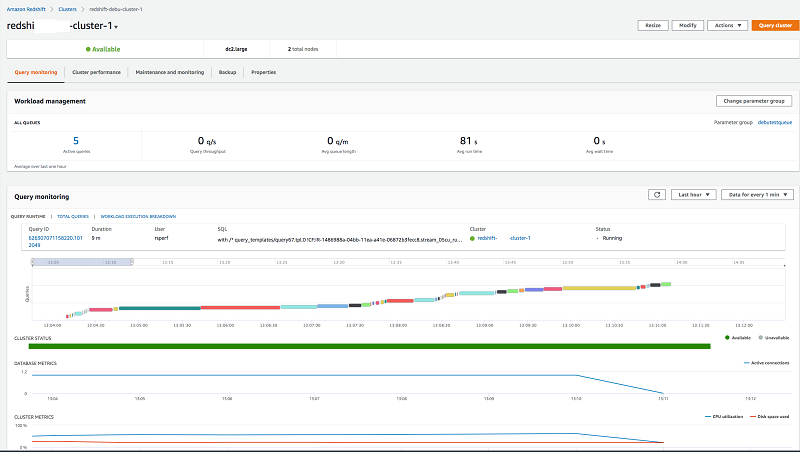
Simplify management of Amazon Redshift clusters with the Redshift console
Amazon Redshift is the most popular and the fastest cloud data warehouse. It includes a console for administrators to create, configure, and manage Amazon Redshift clusters. The new Amazon Redshift console modernizes the user interface and adds several features to improve managing your clusters and workloads running on clusters. The new Amazon Redshift console provides visibility to the health and performance of clusters from a unified dashboard, simplified management of clusters by streamlining several screens and flows, improved mean-time-to-diagnose query performance issues by adding capabilities to monitor user queries and correlate with cluster performance metrics, as well as the ability for non-admin users to use Query Editor.