AWS Big Data Blog

Tips for Migrating to Apache HBase on Amazon S3 from HDFS
Starting with Amazon EMR 5.2.0, you have the option to run Apache HBase on Amazon S3. Running HBase on S3 gives you several added benefits, including lower costs, data durability, and easier scalability. HBase provides several options that you can use to migrate and back up HBase tables. The steps to migrate to HBase on […]
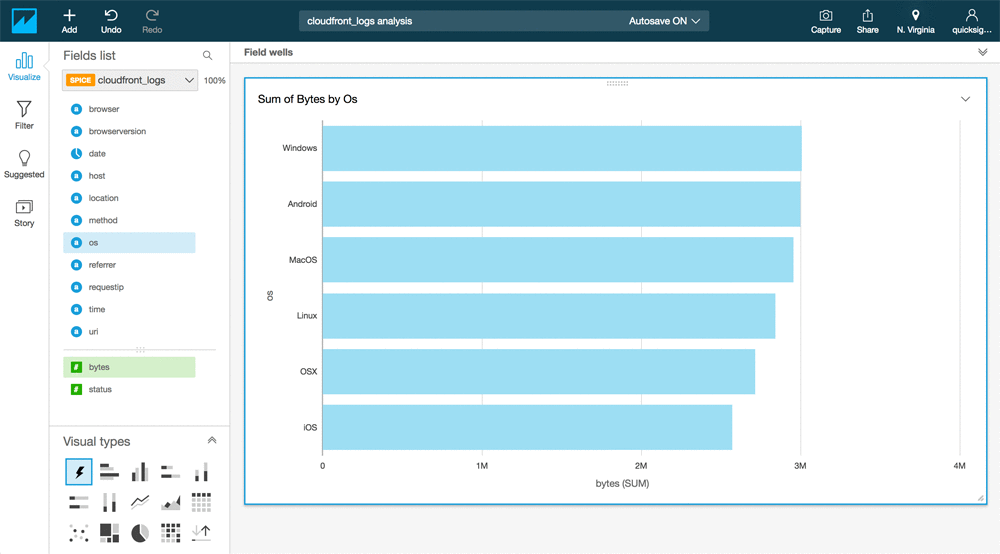
Visualize Big Data with Amazon QuickSight, Presto, and Apache Spark on Amazon EMR
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Last December, we introduced the Amazon Athena connector in Amazon QuickSight, in the Derive Insights from IoT in Minutes using AWS IoT, Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight post. The […]

Near Zero Downtime Migration from MySQL to DynamoDB
Many companies consider migrating from relational databases like MySQL to Amazon DynamoDB, a fully managed, fast, highly scalable, and flexible NoSQL database service. For example, DynamoDB can increase or decrease capacity based on traffic, in accordance with business needs. The total cost of servicing can be optimized more easily than for the typical media-based RDBMS. […]
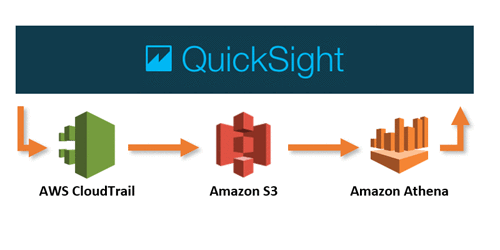
Amazon QuickSight Now Supports Audit Logging with AWS CloudTrail
We launched Amazon QuickSight to democratize BI. Our goal is to make it easier and cheaper to roll out advanced business analytics capabilities to everyone in an organization. Overall, this enables better understanding of business, and allows faster data-driven decisions in an organization. In the past, the ability to share data presented an administrative challenge […]
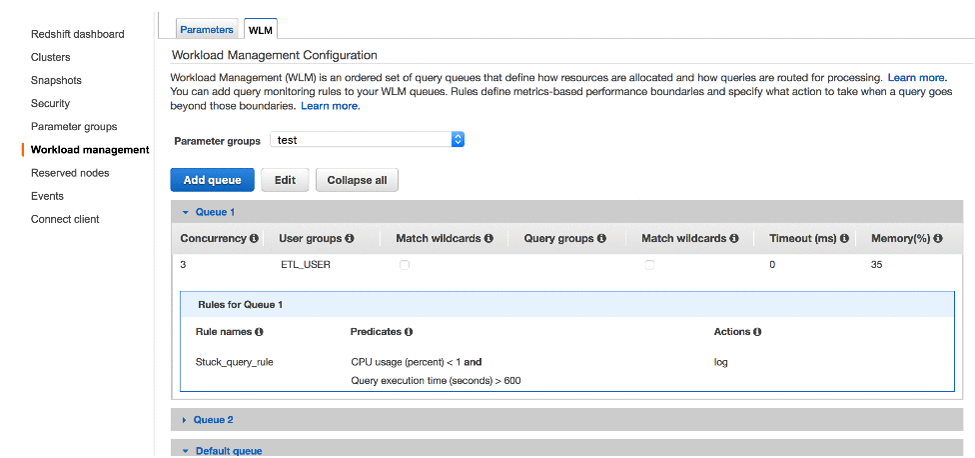
Manage Query Workloads with Query Monitoring Rules in Amazon Redshift
This blog post has been translated into Japanese and Chinese. Data warehousing workloads are known for high variability due to seasonality, potentially expensive exploratory queries, and the varying skill levels of SQL developers. To obtain high performance in the face of highly variable workloads, Amazon Redshift workload management (WLM) enables you to flexibly manage priorities and resource […]

Build a Real-time Stream Processing Pipeline with Apache Flink on AWS
NOTE: As of November 2018, you can run Apache Flink programs with Amazon Kinesis Analytics for Java Applications in a fully managed environment. You can find further details in a new blog post on the AWS Big Data Blog and in this Github repository. ————————– September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. […]
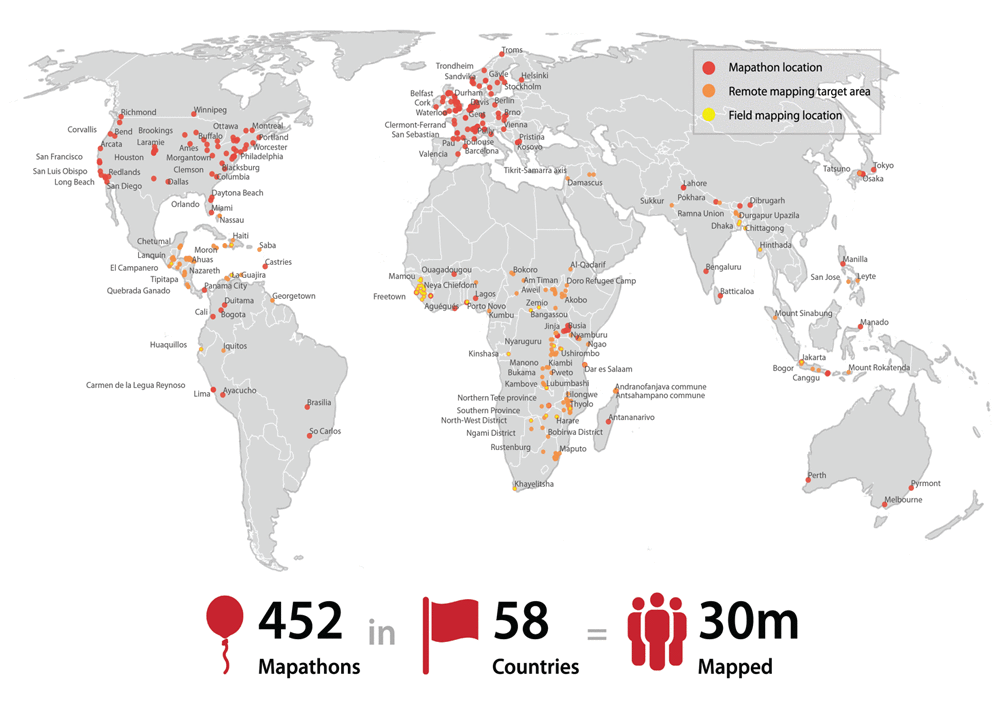
Querying OpenStreetMap with Amazon Athena
This is a guest post by Seth Fitzsimmons, member of the 2017 OpenStreetMap US board of directors. Seth works with clients including the Humanitarian OpenStreetMap Team, Mapzen, the American Red Cross, and World Bank to craft innovative geospatial solutions. OpenStreetMap (OSM) is a free, editable map of the world, created and maintained by volunteers and […]

Securely Analyze Data from Another AWS Account with EMRFS
Sometimes, data to be analyzed is spread across buckets owned by different accounts. In order to ensure data security, appropriate credentials management needs to be in place. This is especially true for large enterprises storing data in different Amazon S3 buckets for different departments. For example, a customer service department may need access to data […]

AWS Big Data Blog Month in Review: March 2017
Another month of big data solutions on the Big Data Blog. Please take a look at our summaries below and learn, comment, and share. Thank you for reading! Analyze Security, Compliance, and Operational Activity Using AWS CloudTrail and Amazon Athena In this blog post, walk through how to set up and use the recently released […]

Amazon QuickSight Spring Announcement: KPI Charts, Export to CSV, AD Connector, and More!
Today I’m excited to share with you a number of exciting new features and enhancements in Amazon QuickSight. You can now create key performance indicator (KPI) charts, define custom ranges when importing Microsoft Excel spreadsheets, export data to comma separated value (CSV) format, and create aggregate filters for SPICE data sets. In the Enterprise Edition, […]