AWS Big Data Blog
Tag: Amazon EMR

Dynamically Create Friendly URLs for Your Amazon EMR Web Interfaces
This solution provides a serverless approach to automatically assigning a friendly name for your EMR cluster for easy access to popular notebooks and other web interfaces.

Use Kerberos Authentication to Integrate Amazon EMR with Microsoft Active Directory
This post walks you through the process of using AWS CloudFormation to set up a cross-realm trust and extend authentication from an Active Directory network into an Amazon EMR cluster with Kerberos enabled. By establishing a cross-realm trust, Active Directory users can use their Active Directory credentials to access an Amazon EMR cluster and run jobs as themselves.

Custom Log Presto Query Events on Amazon EMR for Auditing and Performance Insights
In this blog post, we will demonstrate how to implement and install a Presto event listener for purposes of custom logging, debugging and performance analysis for queries executed on an EMR cluster.

Genomic Analysis with Hail on Amazon EMR and Amazon Athena
For this task, we use Hail, an open source framework for exploring and analyzing genomic data that uses the Apache Spark framework. In this post, we use Amazon EMR to run Hail. We walk through the setup, configuration, and data processing. Finally, we generate an Apache Parquet–formatted variant dataset and explore it using Amazon Athena.

Create Custom AMIs and Push Updates to a Running Amazon EMR Cluster Using Amazon EC2 Systems Manager
In this post, I show how Systems Manager Automation can be used to automate the creation and patching of custom Amazon Linux AMIs for EMR. I also show how you can use Run Command to send commands to all nodes of a running EMR cluster.

Turbocharge your Apache Hive Queries on Amazon EMR using LLAP
NOTE: Starting from emr-6.0.0 release, Hive LLAP is officially supported as a YARN service. So setting up LLAP using the instructions from this blog post (using a bootstrap action script) is not needed for releases emr-6.0.0 and onward. ——————————- Apache Hive is one of the most popular tools for analyzing large datasets stored in a Hadoop […]
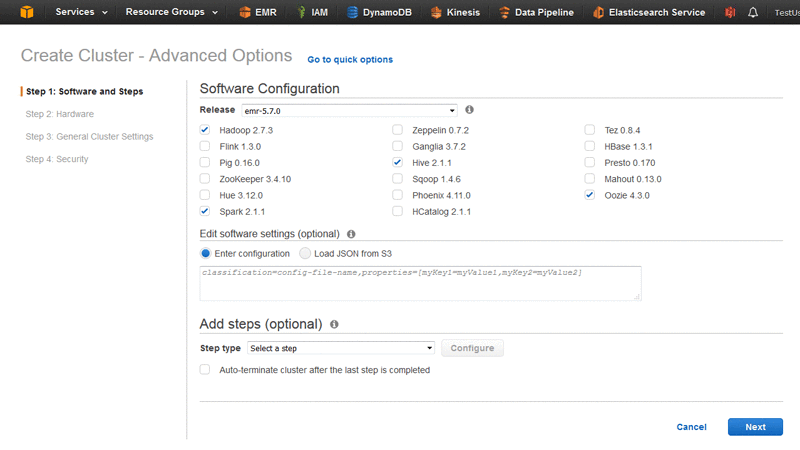
Run Common Data Science Packages on Anaconda and Oozie with Amazon EMR
In the world of data science, users must often sacrifice cluster set-up time to allow for complex usability scenarios. Amazon EMR allows data scientists to spin up complex cluster configurations easily, and to be up and running with complex queries in a matter of minutes. Data scientists often use scheduling applications such as Oozie to […]

Setting up Read Replica Clusters with HBase on Amazon S3
Many customers have taken advantage of the numerous benefits of running Apache HBase on Amazon S3 for data storage, including lower costs, data durability, and easier scalability. Customers such as FINRA have lowered their costs by 60% by moving to an HBase on S3 architecture along with the numerous operational benefits that come with decoupling […]

Seven Tips for Using S3DistCp on Amazon EMR to Move Data Efficiently Between HDFS and Amazon S3
Although it’s common for Amazon EMR customers to process data directly in Amazon S3, there are occasions where you might want to copy data from S3 to the Hadoop Distributed File System (HDFS) on your Amazon EMR cluster. Additionally, you might have a use case that requires moving large amounts of data between buckets or regions. In these use cases, large datasets are too big for a simple copy operation.
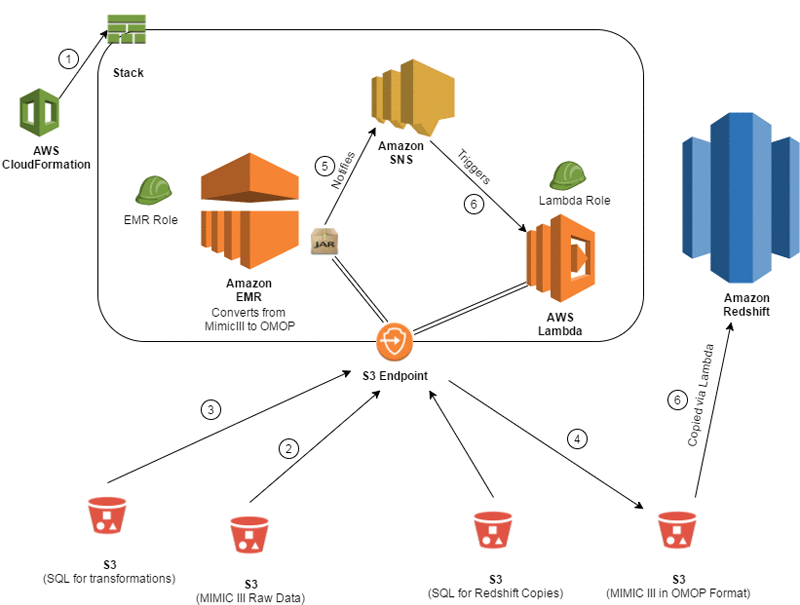
Build a Healthcare Data Warehouse Using Amazon EMR, Amazon Redshift, AWS Lambda, and OMOP
In the healthcare field, data comes in all shapes and sizes. Despite efforts to standardize terminology, some concepts (e.g., blood glucose) are still often depicted in different ways. This post demonstrates how to convert an openly available dataset called MIMIC-III, which consists of de-identified medical data for about 40,000 patients, into an open source data […]