AWS Big Data Blog
Tag: Amazon EMR

Tips for Migrating to Apache HBase on Amazon S3 from HDFS
Starting with Amazon EMR 5.2.0, you have the option to run Apache HBase on Amazon S3. Running HBase on S3 gives you several added benefits, including lower costs, data durability, and easier scalability. HBase provides several options that you can use to migrate and back up HBase tables. The steps to migrate to HBase on […]
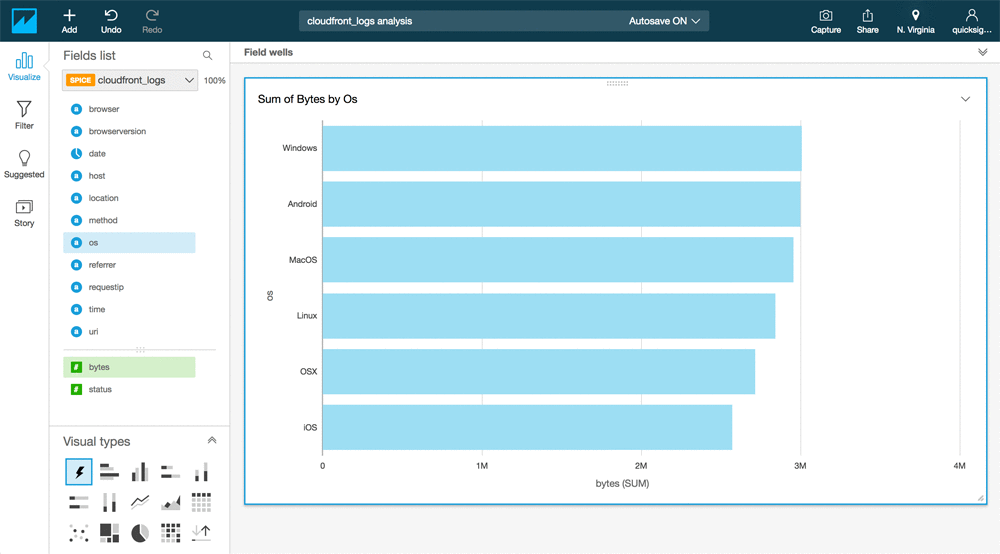
Visualize Big Data with Amazon QuickSight, Presto, and Apache Spark on Amazon EMR
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Last December, we introduced the Amazon Athena connector in Amazon QuickSight, in the Derive Insights from IoT in Minutes using AWS IoT, Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight post. The […]

Build a Real-time Stream Processing Pipeline with Apache Flink on AWS
NOTE: As of November 2018, you can run Apache Flink programs with Amazon Kinesis Analytics for Java Applications in a fully managed environment. You can find further details in a new blog post on the AWS Big Data Blog and in this Github repository. ————————– September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. […]

Securely Analyze Data from Another AWS Account with EMRFS
Sometimes, data to be analyzed is spread across buckets owned by different accounts. In order to ensure data security, appropriate credentials management needs to be in place. This is especially true for large enterprises storing data in different Amazon S3 buckets for different departments. For example, a customer service department may need access to data […]

Meet the Amazon EMR Team this Friday at a Tech Talk & Networking Event in Mountain View
Want to change the world with Big Data and Analytics? Come join us on the Amazon EMR team in Amazon Web Services! Meet the Amazon EMR team this Friday April 7th from 5:00 – 7:30 PM at Michael’s at Shoreline in Mountain View. We’ll feature short tech talks by EMR leadership who will talk about the past, […]
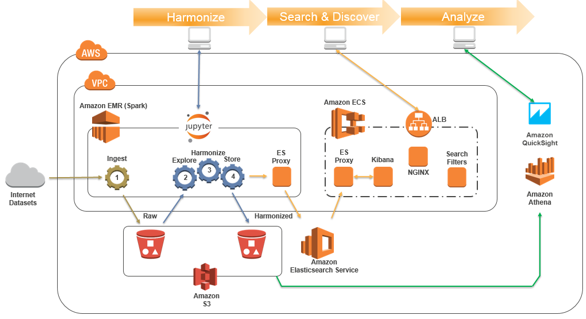
Harmonize, Search, and Analyze Loosely Coupled Datasets on AWS
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. You have come up with an exciting hypothesis, and now you are keen to find and analyze as much data as possible to prove (or refute) it. There are many datasets that might be applicable, but they have been created […]

Secure Amazon EMR with Encryption
In the last few years, there has been a rapid rise in enterprises adopting the Apache Hadoop ecosystem for critical workloads that process sensitive or highly confidential data. Due to the highly critical nature of the workloads, the enterprises implement certain organization/industry wide policies and certain regulatory or compliance policies. Such policy requirements are designed […]

Create a Healthcare Data Hub with AWS and Mirth Connect
As anyone visiting their doctor may have noticed, gone are the days of physicians recording their notes on paper. Physicians are more likely to enter the exam room with a laptop than with paper and pen. This change is the byproduct of efforts to improve patient outcomes, increase efficiency, and drive population health. Pushing for […]

Serving Real-Time Machine Learning Predictions on Amazon EMR
The typical progression for creating and using a trained model for recommendations falls into two general areas: training the model and hosting the model. Model training has become a well-known standard practice. We want to highlight one of many ways to host those recommendations (for example, see the Analyzing Genomics Data at Scale using R, […]
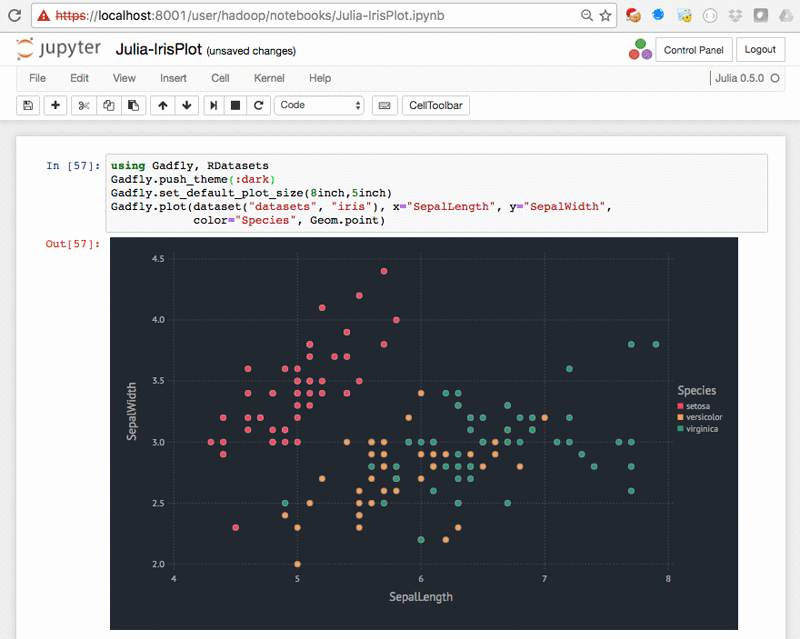
Run Jupyter Notebook and JupyterHub on Amazon EMR
NOTE: Please note that as of EMR 5.14.0, JupyterHub is an officially supported application. We recommend you use the most recent version of EMR if you would like to run JupyterHub on EMR. In addition, EMR Notebooks allow you to create and open Jupyter notebooks with the Amazon EMR console. We will not provide any […]