AWS Big Data Blog
Turbocharge your Apache Hive Queries on Amazon EMR using LLAP
NOTE: Starting from emr-6.0.0 release, Hive LLAP is officially supported as a YARN service. So setting up LLAP using the instructions from this blog post (using a bootstrap action script) is not needed for releases emr-6.0.0 and onward.
——————————-
Apache Hive is one of the most popular tools for analyzing large datasets stored in a Hadoop cluster using SQL. Data analysts and scientists use Hive to query, summarize, explore, and analyze big data.
With the introduction of Hive LLAP (Low Latency Analytical Processing), the notion of Hive being just a batch processing tool has changed. LLAP uses long-lived daemons with intelligent in-memory caching to circumvent batch-oriented latency and provide sub-second query response times.
This post provides an overview of Hive LLAP, including its architecture and common use cases for boosting query performance. You will learn how to install and configure Hive LLAP on an Amazon EMR cluster and run queries on LLAP daemons.
What is Hive LLAP?
Hive LLAP was introduced in Apache Hive 2.0, which provides very fast processing of queries. It uses persistent daemons that are deployed on a Hadoop YARN cluster using Apache Slider. These daemons are long-running and provide functionality such as I/O with DataNode, in-memory caching, query processing, and fine-grained access control. And since the daemons are always running in the cluster, it saves substantial overhead of launching new YARN containers for every new Hive session, thereby avoiding long startup times.
When Hive is configured in hybrid execution mode, small and short queries execute directly on LLAP daemons. Heavy lifting (like large shuffles in the reduce stage) is performed in YARN containers that belong to the application. Resources (CPU, memory, etc.) are obtained in a traditional fashion using YARN. After the resources are obtained, the execution engine can decide which resources are to be allocated to LLAP, or it can launch Apache Tez processors in separate YARN containers. You can also configure Hive to run all the processing workloads on LLAP daemons for querying small datasets at lightning fast speeds.
LLAP daemons are launched under YARN management to ensure that the nodes don’t get overloaded with the compute resources of these daemons. You can use scheduling queues to make sure that there is enough compute capacity for other YARN applications to run.
Why use Hive LLAP?
With many options available in the market (Presto, Spark SQL, etc.) for doing interactive SQL over data that is stored in Amazon S3 and HDFS, there are several reasons why using Hive and LLAP might be a good choice:
- For those who are heavily invested in the Hive ecosystem and have external BI tools that connect to Hive over JDBC/ODBC connections, LLAP plugs in to their existing architecture without a steep learning curve.
- It’s compatible with existing Hive SQL and other Hive tools, like HiveServer2, and JDBC drivers for Hive.
- It has native support for security features with authentication and authorization (SQL standards-based authorization) using HiveServer2.
- LLAP daemons are aware about of the columns and records that are being processed which enables you to enforce fine-grained access control.
- It can use Hive’s vectorization capabilities to speed up queries, and Hive has better support for ORC file format when vectorization is enabled.
- It can take advantage of a number of Hive optimizations like merging multiple small files for query results, automatically determining the number of reducers for joins and groupbys, etc.
- It’s optional and modular so it can be turned on or off depending on the compute and resource requirements of the cluster. This lets you to run other YARN applications concurrently without reserving a cluster specifically for LLAP.
How do you install Hive LLAP in Amazon EMR?
To install and configure LLAP on an EMR cluster, use the following bootstrap action (BA):
This BA downloads and installs Apache Slider on the cluster and configures LLAP so that it works with EMR Hive. For LLAP to work, the EMR cluster must have Hive, Tez, and Apache Zookeeper installed.
You can pass the following arguments to the BA.
| Argument | Definition | Default value |
| --instances | Number of instances of LLAP daemon | Number of core/task nodes of the cluster |
| --cache | Cache size per instance | 20% of physical memory of the node |
| --executors | Number of executors per instance | Number of CPU cores of the node |
| --iothreads | Number of IO threads per instance | Number of CPU cores of the node |
| --size | Container size per instance | 50% of physical memory of the node |
| --xmx | Working memory size | 50% of container size |
| --log-level | Log levels for the LLAP instance | INFO |
LLAP example
This section describes how you can try the faster Hive queries with LLAP using the TPC-DS testbench for Hive on Amazon EMR.
Use the following AWS command line interface (AWS CLI) command to launch a 1+3 nodes m4.xlarge EMR 5.6.0 cluster with the bootstrap action to install LLAP:
After the cluster is launched, log in to the master node using SSH, and do the following:
- Open the hive-tpcds folder:
cd /home/hadoop/hive-tpcds/ - Start Hive CLI using the testbench configuration, create the required tables, and run the sample query:
hive –i testbench.settings
hive> source create_tables.sql;
hive> source query55.sql;
This sample query runs on a 40 GB dataset that is stored on Amazon S3. The dataset is generated using the data generation tool in the TPC-DS testbench for Hive.It results in output like the following:

- This screenshot shows that the query finished in about 47 seconds for LLAP mode. Now, to compare this to the execution time without LLAP, you can run the same workload using only Tez containers:
hive> set hive.llap.execution.mode=none;
hive> source query55.sql;
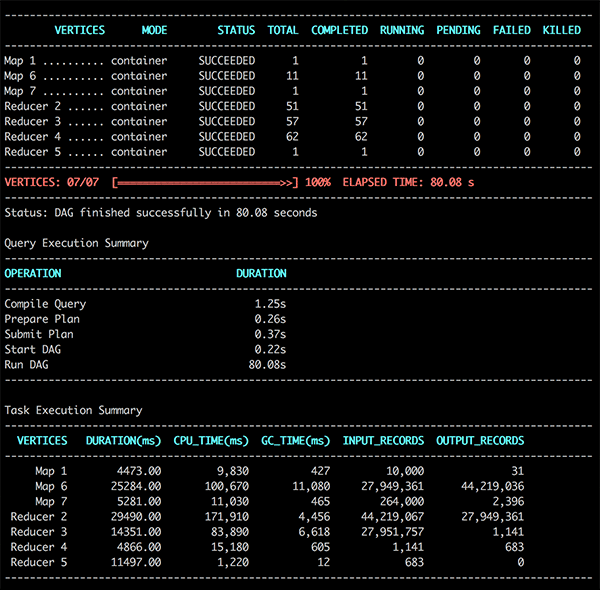
This query finished in about 80 seconds.
The difference in query execution time is almost 1.7 times when using just YARN containers in contrast to running the query on LLAP daemons. And with every rerun of the query, you notice that the execution time substantially decreases by the virtue of in-memory caching by LLAP daemons.
Conclusion
In this post, I introduced Hive LLAP as a way to boost Hive query performance. I discussed its architecture and described several use cases for the component. I showed how you can install and configure Hive LLAP on an Amazon EMR cluster and how you can run queries on LLAP daemons.
If you have questions about using Hive LLAP on Amazon EMR or would like to share your use cases, please leave a comment below.
Additional Reading
Learn how to to automatically partition Hive external tables with AWS.
About the Author
 Jigar Mistry is a Hadoop Systems Engineer with Amazon Web Services. He works with customers to provide them architectural guidance and technical support for processing large datasets in the cloud using open-source applications. In his spare time, he enjoys going for camping and exploring different restaurants in the Seattle area.
Jigar Mistry is a Hadoop Systems Engineer with Amazon Web Services. He works with customers to provide them architectural guidance and technical support for processing large datasets in the cloud using open-source applications. In his spare time, he enjoys going for camping and exploring different restaurants in the Seattle area.