AWS Compute Blog
Best practices for organizing larger serverless applications
Well-designed serverless applications are decoupled, stateless, and use minimal code. As projects grow, a goal for development managers is to maintain the simplicity of design and low-code implementation. This blog post provides recommendations for designing and managing code repositories in larger serverless projects, and best practices for deploying releases of production systems.
Organizing your code repositories
Many serverless applications begin as monolithic applications. This can occur either because a simple application has grown more complex over time, or because developers are following existing development practices. A monolithic application is represented by a single AWS Lambda function performing multiple tasks, and a mono-repo is a single repository containing the entire application logic.
Monoliths work well for the simplest serverless applications that perform single-purpose functions. These are small applications such as cron jobs, data processing tasks, and some asynchronous processes. As those applications evolve into workflows or develop new features, it becomes important to refactor the code into smaller services.
Using frameworks such as the AWS Serverless Application Model (SAM) or the Serverless Framework can make it easier to group common pieces of functionality into smaller services. Each of these can have a separate code repository. For SAM, the template.yaml file contains all the resources and function definitions needed for an application. Consequently, breaking an application into microservices with separate templates is a simple way to split repos and resource groups.

In the smallest unit of a serverless application, it’s also possible to create one repository per function. If these functions are independent and do not share other AWS resources, this may be appropriate. Helper functions and simple event processing code are examples of candidates for this kind of repo structure.
In most cases, it makes sense to create repos around groups of functions and resources that define a microservice. In an ecommerce example, “Payment processing” is a microservice with multiple smaller related functions that share common resources.
As with any software, the repo design depends upon the use-case and structure of development teams. One large repo makes it harder for developer teams to work on different features, and test and deploy. Having too many repos can create duplicate code, and difficulty in sharing resources across repos. Finding the balance for your project is an important step in designing your application architecture.
Using AWS services instead of code libraries
AWS services are important building blocks for your serverless applications. These can frequently provide greater scale, performance, and reliability than bundled code packages with similar functionality.
For example, many web applications that are migrated to Lambda use web frameworks like Flask (for Python) or Express (for Node.js). Both packages support routing and separate user contexts that are well suited if the application is running on a web server. Using these packages in Lambda functions results in architectures like this:

In this case, Amazon API Gateway proxies all requests to the Lambda function to handle routing. As the application develops more routes, the Lambda function grows in size and deployments of new versions replace the entire function. It becomes harder for multiple developers to work on the same project in this context.
This approach is generally unnecessary, and it’s often better to take advantage of the native routing functionality available in API Gateway. In many cases, there is no need for the web framework in the Lambda function, which increases the size of the deployment package. API Gateway is also capable of validating parameters, reducing the need for checking parameters with custom code. It can also provide protection against unauthorized access, and a range of other features more suited to be handled at the service level. When using API Gateway this way, the new architecture looks like this:
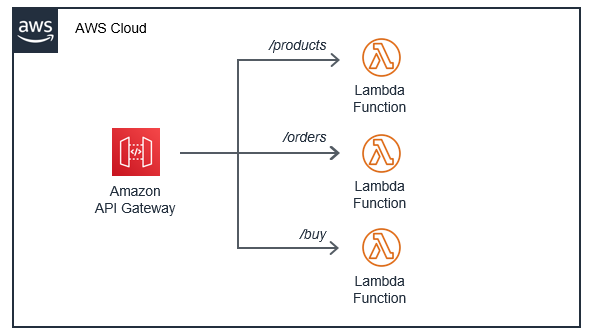
Additionally, the Lambda functions consist of less code and fewer package dependencies. This makes testing easier and reduces the need to maintain code library versions. Different developers in a team can work on separate routing functions independently, and it becomes simpler to reuse code in future projects. You can configure routes in API Gateway in the application’s SAM template:
Resources:
GetProducts:
Type: AWS::Serverless::Function
Properties:
CodeUri: getProducts/
Handler: app.handler
Runtime: nodejs12.x
Events:
GetProductsAPI:
Type: Api
Properties:
Path: /getProducts
Method: getSimilarly, you should usually avoid performing workflow orchestrations within Lambda functions. These are sections of code that call out to other services and functions, and perform subsequent actions based on successful execution or failure.

These workflows quickly become fragile and difficult to modify for new requirements. They can cause idling in the Lambda function, meaning that the function is waiting for return values from external sources, increasingly the cost of execution.
Often, a better approach is to use AWS Step Functions, which can represent complex workflows as JSON definitions in the application’s SAM template. This service reduces the amount of custom code required, and enables long-lived workflows that minimize idling in Lambda functions. It also manages in-flight executions as workflows are upgraded. The example above, rearchitected with a Step Functions workflow, looks like this:
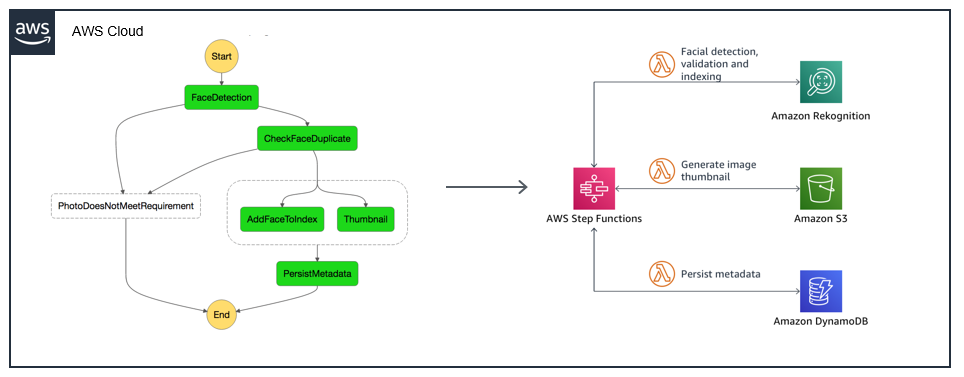
Using multiple AWS accounts for development teams
There are many ways to deploy serverless applications to production. As applications grow and become more important to your business, development managers generally want to improve the robustness of the deployment process. You have a number of options within AWS for managing the development and deployment of serverless applications.
First, it is highly recommended to use more than one AWS account. Using AWS Organizations, you can centrally manage the billing, compliance, and security of these accounts. You can attach policies to groups of accounts to avoid custom scripts and manual processes. One simple approach is to provide each developer with an AWS account, and then use separate accounts for a beta deployment stage and production:

The developer accounts can contain copies of production resources and provide the developer with admin-level permissions to these resources. Each developer has their own set of limits for the account, so their usage does not impact your production environment. Individual developers can deploy CloudFormation stacks and SAM templates into these accounts with minimal risk to production assets.
This approach allows developers to test Lambda functions locally on their development machines against live cloud resources in their individual accounts. It can help create a robust unit testing process, and developers can then push code to a repository like AWS CodeCommit when ready.
By integrating with AWS Secrets Manager, you can store different sets of secrets in each environment and eliminate any need for credentials stored in code. As code is promoted from developer account through to the beta and production accounts, the correct set of credentials is automatically used. You do not need to share environment-level credentials with individual developers.
It’s also possible to implement a CI/CD process to start build pipelines when code is deployed. To deploy a sample application using a multi-account deployment flow, follow this serverless CI/CD tutorial.
Managing feature releases in serverless applications
As you implement CI/CD pipelines for your production serverless applications, it is best practice to favor safe deployments over entire application upgrades. Unlike traditional software deployments, serverless applications are a combination of custom code in Lambda functions and AWS service configurations.
A feature release may consist of a version change in a Lambda function. It may have a different endpoint in API Gateway, or use a new resource such as a DynamoDB table. Access to the deployed feature may be controlled via user configuration and feature toggles, depending upon the application. AWS SAM has AWS CodeDeploy built-in, which allows you to configure canary deployments in the YAML configuration:
Resources:
GetProducts:
Type: AWS::Serverless::Function
Properties:
CodeUri: getProducts/
Handler: app.handler
Runtime: nodejs12.x
AutoPublishAlias: live
DeploymentPreference:
Type: Canary10Percent10Minutes
Alarms:
# A list of alarms that you want to monitor
- !Ref AliasErrorMetricGreaterThanZeroAlarm
- !Ref LatestVersionErrorMetricGreaterThanZeroAlarm
Hooks:
# Validation Lambda functions run before/after traffic shifting
PreTraffic: !Ref PreTrafficLambdaFunction
PostTraffic: !Ref PostTrafficLambdaFunction
CodeDeploy automatically creates aliases pointing to the old and versions of a function. The canary deployment enables you to gradually shift traffic from the old to the new alias, as you become confident that the new version is working as expected. Or you can rollback the update if needed. You can also set PreTraffic and PostTraffic hooks to invoke Lambda functions before and after traffic shifting.
Conclusion
As any software application grows in size, it’s important for development managers to organize code repositories and manage releases. There are established patterns in serverless to help manage larger applications. Generally, it’s best to avoid monolithic functions and mono-repos, and you should scope repositories to either the microservice or function level.
Well-designed serverless applications use custom code in Lambda functions to connect with managed services. It’s important to identify libraries and packages that can be replaced with services to minimize the deployment size and simplify the code base. This is especially true in applications that have been migrated from server-based environments.
Using AWS Organizations, you manage groups of accounts to enable your developers to have their own AWS accounts for development. This enables engineers to clone production assets and test against the AWS Cloud when writing and debugging code. You can use a CI/CD pipeline to push code through a beta environment to production, while safeguarding secrets using Secrets Manager. You can also use CodeDeploy to manage canary deployments easily.
To learn more about deploying Lambda functions with SAM and CodeDeploy, follow the steps in this tutorial.