AWS Compute Blog
Building a serverless multi-player game that scales: Part 3
This post is written by Tim Bruce, Sr. Solutions Architect, DevAx, Chelsie Delecki, Solutions Architect, DNB, and Brian Krygsman, Solutions Architect, Enterprise.
This blog series discusses building a serverless game that scales, using Simple Trivia Service:
- Part 1 describes the overall architecture, how to deploy to your AWS account, and the different communication methods.
- Part 2 describes adding automation to the game to help your teams scale.
This post discusses how the game scales to support concurrent users (CCU) under a load test. While this post focuses on Simple Trivia Service, you can apply the concepts to any serverless workload.
To set up the example, see the instructions in the Simple Trivia Service GitHub repo and the README.md file. This example uses services beyond AWS Free Tier and incurs charges. To remove the example from your account, see the README.md file.
Overview
Simple Trivia Service is launching at a new trivia conference. There are 200,000 registered attendees who are invited to play the game during the conference. The developers are following AWS Well-Architected best practice and load test before the launch.
Load testing is the practice of simulating user load to validate the system’s ability to scale. The focus of the load test is the game’s microservices, built using AWS Serverless services, including:
- Amazon API Gateway and AWS IoT, which provide serverless endpoints, allowing users to interact with the Simple Trivia Service microservices.
- AWS Lambda, which provides serverless compute services for the microservices.
- Amazon DynamoDB, which provides a serverless NoSQL database for storing game data.
Preparing for load testing
Defining success criteria is one of the first steps in preparing for a load test. You use success criteria to determine how well the game meets the requirements and includes concurrent users, error rates, and response time. These three criteria help to ensure that your users have a good experience when playing your game.
Excluding one can lead to invalid assumptions about the scale of users that the game can support. If you exclude error rate goals, for example, users may encounter more errors, impacting their experience.
The success criteria used for Simple Trivia Service are:
- 200,000 concurrent users split across game types.
- Error rates below 0.05%.
- 95th percentile synchronous responses under 1 second.
With these identified, you can develop dashboards to report on the targets. Dashboards allow you to monitor system metrics over the course of load tests. You can develop dashboards using Amazon CloudWatch dashboards, using custom widgets that organize and display metrics.
Common metrics to monitor include:
- Error rates – total errors / total invocations.
- Throttles – invocations resulting in 429 errors.
- Percentage of quota usage – usage against your game’s Service Quotas.
- Concurrent execution counts – maximum concurrent Lambda invocations.
- Provisioned concurrency invocation rate – provisioned concurrency spillover invocation count / provisioned concurrency invocation count.
- Latency – percentile-based response time, such as 90th and 95th percentiles.
Documentation and other services are also helpful during load testing. Centralized logging via Amazon CloudWatch Logs and AWS CloudTrail provide your team with operational data for the game. This data can help triage issues during testing.
System architecture documents provide key details to help your team focus their work during triage. Amazon DevOps Guru can also provide your team with potential solutions for issues. This uses machine learning to identify operational deviations and deployments and provides recommendations for resolving issues.
A load testing tool simplifies your testing, allowing you to model users playing the game. Popular load testing tools include Apache JMeter, Artillery.io Artillery, and Locust.io Locust. The load testing tool you select can act as your application client and access your endpoints directly.
This example uses Locust to load test Simple Trivia Service based on language and technical requirements. It allows you to accurately model usage and not only generate transactions. In production applications, select a tool that aligns to your team’s skills and meets your technical requirements.
You can place automation around load testing tool to reduce manual effort of running tests. Automation can include allocating environments, deploying and running test scripts, and collecting results. You can include this as part of your continuous integration/continuous delivery (CI/CD) pipeline. You can use the Distributed Load Testing on AWS solution to support Taurus-compatible load testing.
Also, document a plan, working backwards from your goals to help measure your progress. Plans typically use incremental growth of CCU, which can help you to identify constraints in your game. Use your plan while you are in development once portions of your game feature complete.
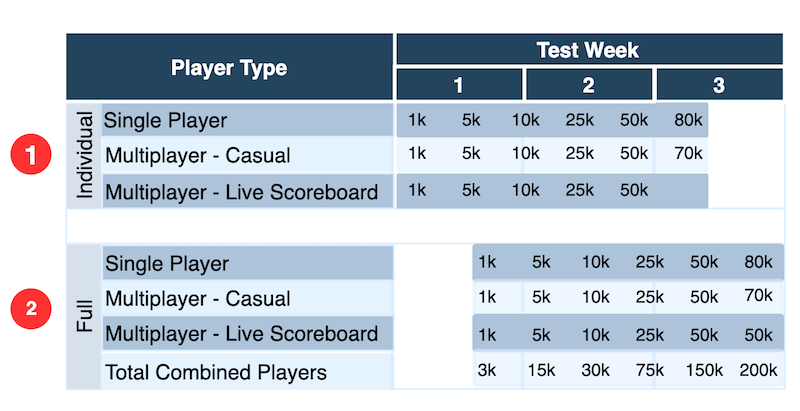
This shows an example plan for load testing Simple Trivia Service:
- Start with individual game testing to validate tests and game modes separately.
- Add in testing of the three game modes together, mirroring expected real world activity.
Finally, evaluate your load test and architecture against your AWS Customer Agreement, AWS Acceptable Use Policy, Amazon EC2 Testing Policy, and the AWS Customer Support Policy for Penetration Testing. These policies are put in place to help you to be successful in your load testing efforts. AWS Support requires you to notify them at least two weeks prior to your load test using the Simulated Events Submission Form with the AWS Management Console. This form can also be used if you have questions before your load test.
Additional help for your load test may be available on the AWS Forums, AWS re:Post, or via your account team.
Testing
After triggering a test, automation scales up your infrastructure and initializes the test users. Depending on the number of users you need and their startup behavior, this ramp-up phase can take several minutes. Similarly, when the test run is complete, your test users should ramp down. Unless you have modeled the ramp-up and ramp-down phases to match real-world behavior, exclude these phases from your measurements. If you include them, you may optimize for unrealistic user behavior.
While tests are running, let metrics normalize before drawing conclusions. Services may report data at different rates. Investigate when you find metrics that cross your acceptable thresholds. You may need to make adjustments like adding Lambda Provisioned Concurrency or changing application code to resolve constraints. You may even need to re-evaluate your requirements based on how the system performs. When you make changes, re-test to verify any changes had the impact you expected before continuing with your plan.
Finally, keep an organized record of the inputs and outputs of tests, including dashboard exports and your own observations. This record is valuable when sharing test outcomes and comparing test runs. Mark your progress against the plan to stay on track.
Analyzing and improving Simple Trivia Service performance
Running the test plan, using observability tools to measure performance, finds opportunities to tune performance bottlenecks.
In this example, during single player individual tests, the dashboards show acceptable latency values. As the test size grows, increasing read capacity for retrieving leaderboards indicates a tuning opportunity:
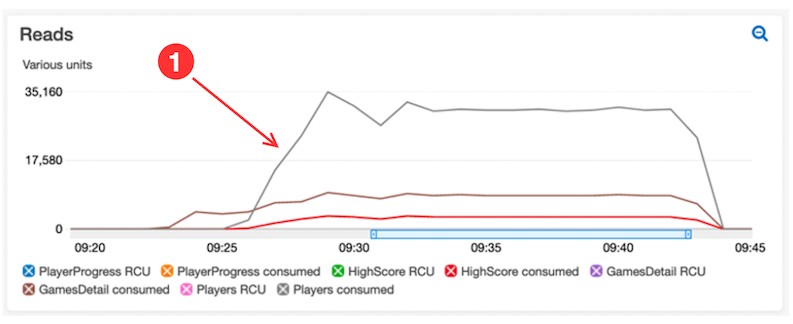
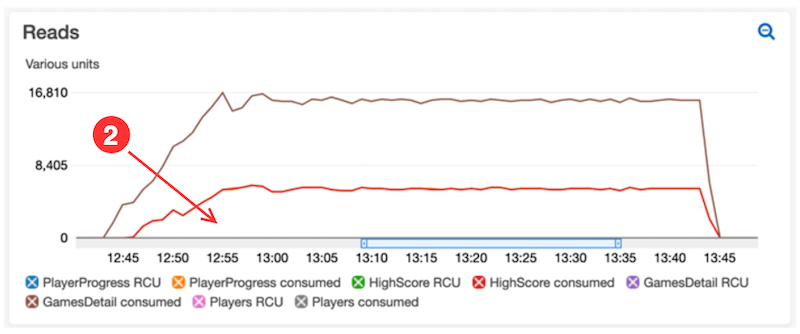
- The CloudWatch dashboard reveals that the LeaderboardGet function is leading to high consumed read capacity for the Players DynamoDB table. A process within the function is querying scores and player records with every call to load avatar URLs
- Standardizing the player avatar URL process within the code reduces reads from the table. The update improves DynamoDB reads.
Moving into the full test phase of the plan with combined game types identified additional areas for performance optimization. In one case, dashboards highlight unexpected error rates for a Lambda function. Consulting function logs and DevOps Guru to triage the behavior, these show a downstream issue with an Amazon Kinesis Data Stream:
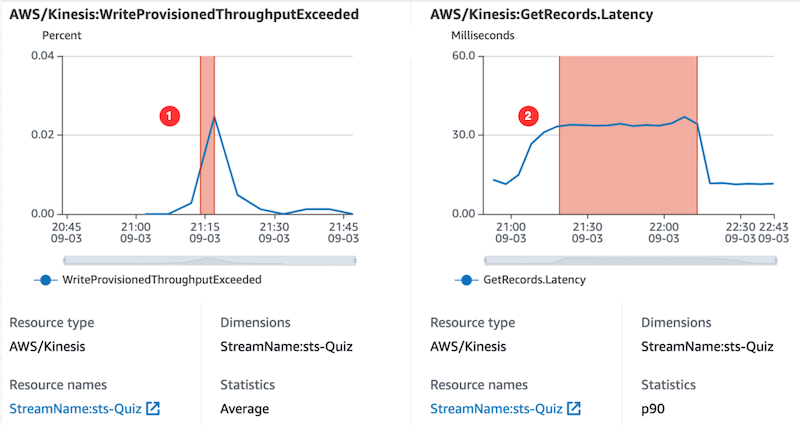
- DevOps Guru, within an insight, highlights the problem of the Kinesis:WriteProvisionedThroughputExceeded metric during our test window
- DevOps Guru also correlates that metric with the Kinesis:GetRecords.Latency metric.
DevOps Guru also links to a recommendation for Kinesis Data Streams to troubleshoot and resolve the incident with the data stream. Following this advice helps to resolve the Lambda error rates during the next test.
Load testing results
By following the plan, making incremental changes as optimizations became apparent, you can reach the goals.

The preceding table is a summary of data from Amazon CloudWatch Lambda Insights and statistics captured from Locust:
- The test exceeded the goal of 200k CCU with a combined total of 236,820 CCU.
- Less than 0.05% error rate with a combined average of 0.010%.
- Performance goals are achieved without needing Provisioned Concurrency in Lambda.
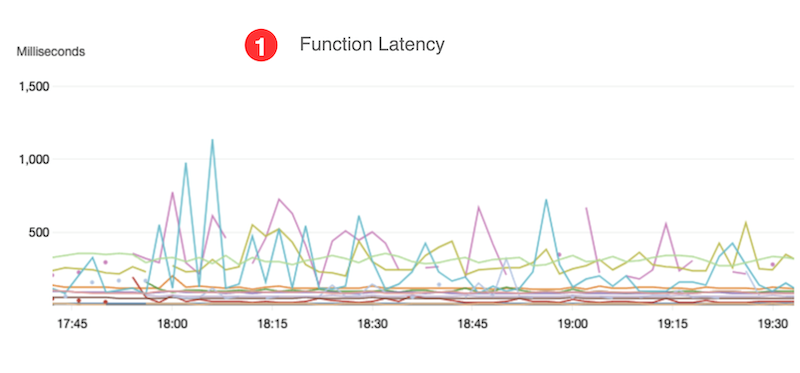
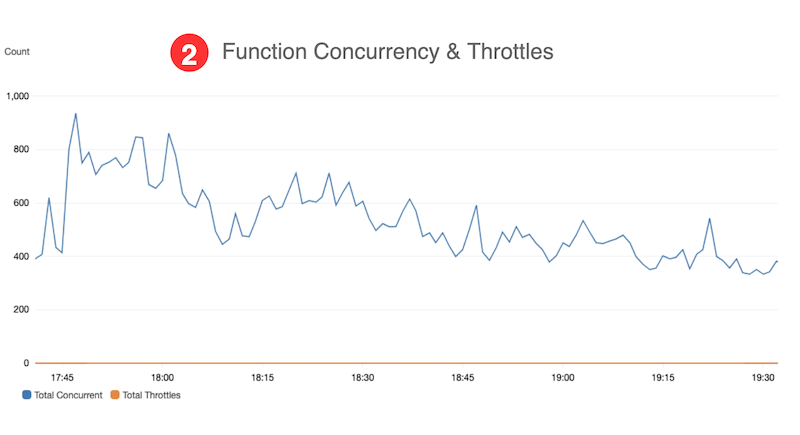
- The function latency goal of < 1 second is met, based on data from CloudWatch Lambda Insights.
- Function concurrency is below Service Quotas for Lambda during the test, based on data from our custom CloudWatch dashboard.
Conclusion
This post discusses how to perform a load test on a serverless workload. The process was used to validate a scale of Simple Trivia Service, a single- and multi-player game built using a serverless-first architecture on AWS. The results show a scale of over 220,000 CCUs while maintaining less than 1-second response time and an error rate under 0.05%.
For more serverless learning resources, visit Serverless Land.