AWS Compute Blog
Building resilient multi-Region Serverless applications on AWS
Mission-critical applications demand high availability and resilience against potential disruptions. In online gaming, millions of players connect simultaneously, making availability challenges evident. When gaming platforms experience outages, players lose progress, tournaments get disrupted, and brand reputation suffers. Traditional environments often overprovision compute to address these challenges, resulting in complex setups and high infrastructure and operation costs. Modern Amazon Web Services (AWS) serverless infrastructure offers a more efficient approach. This post presents architectural best practices for building resilient serverless applications, demonstrated through a multi-Region serverless authorizer implementation.
Overview
It’s too late if you are recognizing the importance of availability only after experiencing a disaster event. Applications fail for a variety of reasons, such as infrastructure issues, code defects, configuration errors, unexpected traffic spikes, or service disruptions at a regional level. Critical business services such as authentication systems, payment processors, and real-time gaming features necessitate high availability. To minimize impact on user experience and business revenue, establish bounded recovery times for critical services during outages.
AWS serverless architectures inherently provide high availability through multi-Availability Zone (AZ) deployments and built-in scalability. These services minimize infrastructure management while operating on a pay-for-value pricing model at a Regional level. The AWS serverless pay-for-value model enables cost-effective multi-Region deployments, making it ideal for building resilient architectures.
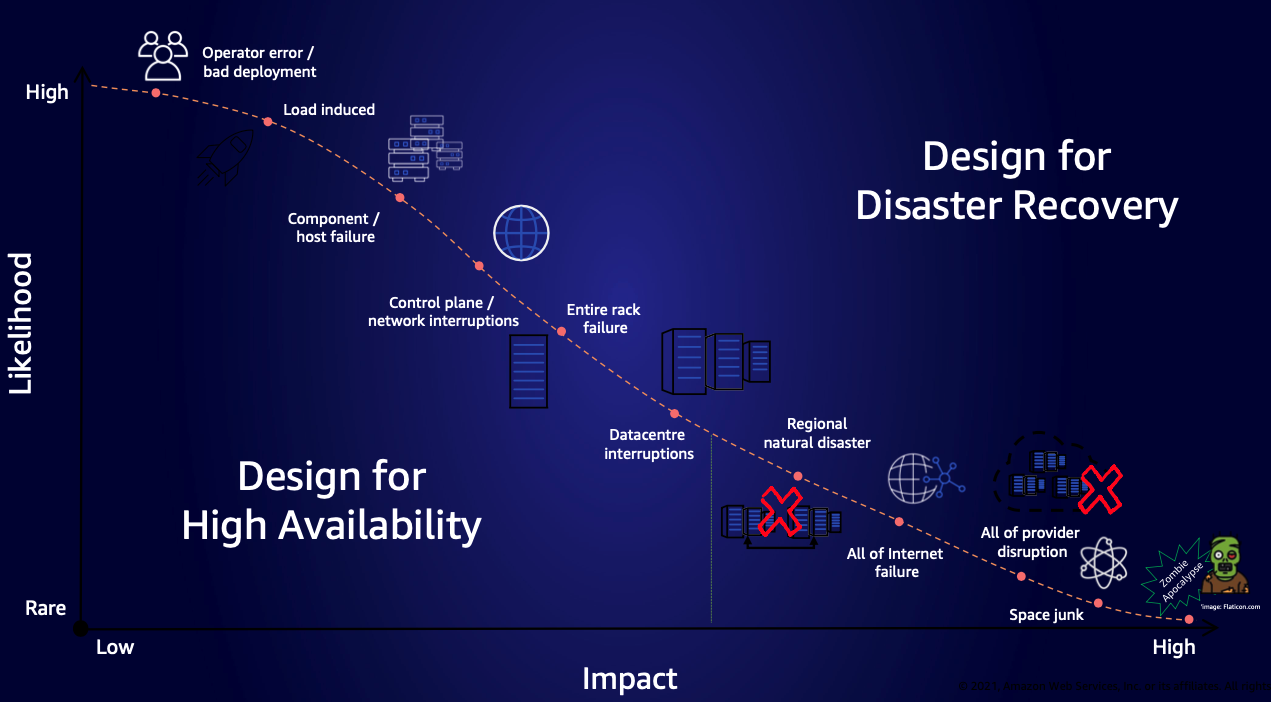
Figure 1. Chart showing various causes of failure, their impact, and how often they happen
The preceding chart maps failures—from common operational errors to rare catastrophic events. It guides organizations in prioritizing multi-Region recovery strategies based on the likelihood and the potential impact to the business.
Regional decisions
To determine the appropriate multi-Region approach, carefully evaluate the following factors:
- Evaluate if your Recovery Time Objective (RTO) and Recovery Point Objective (RPO) requirements can be met within a single Region, or if a multi-Region architecture is necessary to achieve your recovery objectives.
- Do the business benefits of multi-Region redundancy outweigh the operational costs of data replication, synchronization, and increased implementation cost and complexity?
- Evaluate if data sovereignty laws, compliance requirements, or geographic restrictions prevent data replication across specific AWS Regions.
- Make sure that the chosen Regions in a multi-Region solution have service compatibility, quota limits, and pricing to match your needs.
After evaluating these requirements, if organizations determine the need for multi-Region workloads, then they must choose between two architectural patterns: Active-Passive or Active-Active deployments. Each pattern offers distinct advantages and trade-offs for resilience, costs, and operational complexity.
Multi-Region deployment patterns
The following sections outline the different multi-Region deployment patterns: Active-Passive, and Active-Active.
Active-Passive
In this pattern, one AWS Region serves as the “Active” Region, handling all production traffic, while other Region(s) remain “Passive”, as shown in the following figure. Passive Region(s) replicate data and configurations from the Active Region without serving requests and are prepared to handle requests during service disruptions in the “Active” Region. Depending on application criticality, passive Regions implement varying levels of infrastructure readiness: fully deployed infrastructure (Hot Standby), partially deployed infrastructure (Warm Standby), or minimal core infrastructure (Pilot Light).
Traditional Active-Passive architectures need significant investment in idle infrastructure: load balancers, auto-scaling groups, running compute resources, and monitoring systems. Organizations can use AWS serverless applications, with their pay-for-value pricing, to pay primarily for data replication, not idle compute resources. AWS manages the underlying infrastructure, eliminating most operational overhead.
Service quotas, API limits, and concurrency settings must match between AWS Regions to provide seamless failover. AWS Lambda offers provisioned concurrency to keep functions warm and responsive, which is particularly useful for secondary Regions during failover. It helps reduce cold starts by maintaining warm execution environments, thus the system can handle sudden traffic spikes with fewer cold starts. Note that provisioned concurrency incurs compute costs regardless of usage. Consider implementing auto-scaling for provisioned concurrency based on traffic patterns to optimize costs during idle periods.
This pattern suits organizations seeking a cost-effective disaster recovery (DR) solution, because AWS serverless charges apply only when resources are actively used in the secondary Region. Managed services such as Amazon DynamoDB Global Tables and Amazon Aurora Global Database handle data replication, further streamlining the implementation. The serverless authorizer discussed later in this article demonstrates this pattern in practice.
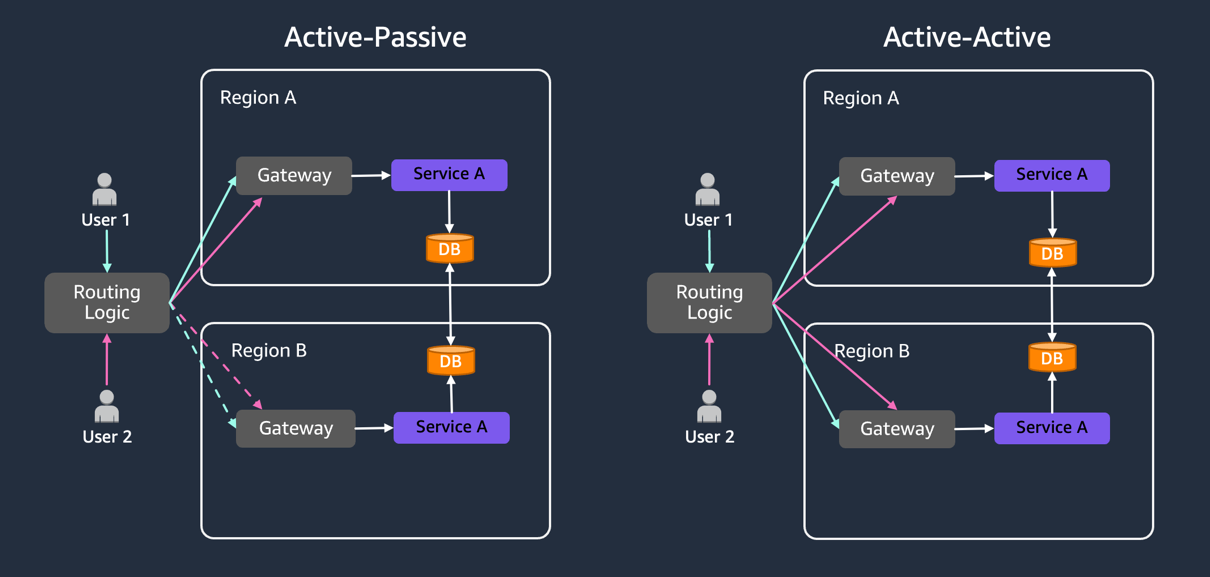
Figure 2: Active-Passive pattern with dotted lines shows standby Regions, while Active-Active patterns serve concurrent traffic
Active-Active
In this pattern, multiple Regions actively serve traffic concurrently, distributing the load and providing rapid failover capabilities. Active-Active architectures are expensive and designed for highest availability. However, they do not inherently provide DR for all potential failure modes. This approach suits applications needing geolocation-based routing, or highest availability requirements.
Active-Active deployments need rigorous engineering to handle data synchronization and conflict resolution. Each Region must be sized to handle full application load if another Region experiences service impairments. Active users are distributed across AWS Regions, thus a disruption in the service in one Region redirects all of the traffic to the remaining Regions, which necessitates them handling the combined load. To improve application resiliency, implement retry mechanisms, circuit breakers, and fallback strategies. Plan for static stability by pre-provisioning capacity and implementing client-side caching. Services such as Amazon Route 53 with latency-based routing and Amazon DynamoDB Global Tables with strong consistency provide the foundation but need thorough testing under various failure scenarios. This blog will not cover Active-Active deployments.
Multi-Region serverless authorizer
To demonstrate the Active-Passive scenario, we build a sample application that demonstrates how to build a multi-Region serverless authorizer using Amazon API Gateway, Lambda functions, and Amazon Route53. Modern gaming and entertainment platforms host critical services such as player matchmaking, live streaming, and real-time sports analytics. These services depend on robust authorization systems—when authorization fails, players cannot join matches, viewers lose access to streams, and live events becomes inaccessible. This post demonstrates how to build a fault-tolerant, multi-Region serverless authorizer while maintaining lower costs as compared to traditional environments.
Serverless multi-Region architectures typically comprise Routing, Compute, and Data layers. When implementing multi-Region deployments, data replication across AWS Regions is essential, regardless of the compute services used. The compute layer should prioritize idempotency to make sure of safe event processing across AWS Regions. Use Powertools for Lambda for efficient idempotency handling, or implement custom solutions using unique event IDs with DynamoDB as an idempotency store. Although this post focuses on the authorizer service implementation, this pattern can be applied to build multi-Region microservices handling various critical functions, such as game session management, content delivery orchestration, user preference management, and profile services.
Demo overview
To demonstrate the multi-Region serverless authorizer operation, we can examine the workflow:
- The frontend application authenticates with the Identity Provider to obtain an authentication token.
- The authentication token is sent to a resilient multi-Region DNS endpoint, which is hosted on Route 53 in this demo.
- Route 53 routes the request with the token to API Gateway in the primary Region.
- Route 53 monitors application health using a mock Lambda function in this demo. In production environments, implement deep health checks to monitor the complete service stack.
- Upon successful authorization, the application receives a response. If Route 53 detects primary Region impairment, then it triggers Amazon CloudWatch alarms, which application owners can use to evaluate and approve traffic redirection to the secondary Region.
- New traffic routes to the API Gateway in the secondary Region after manual failover approval.
- Route 53 health checks continue monitoring the primary Region’s health and restores request traffic when the Region recovers.
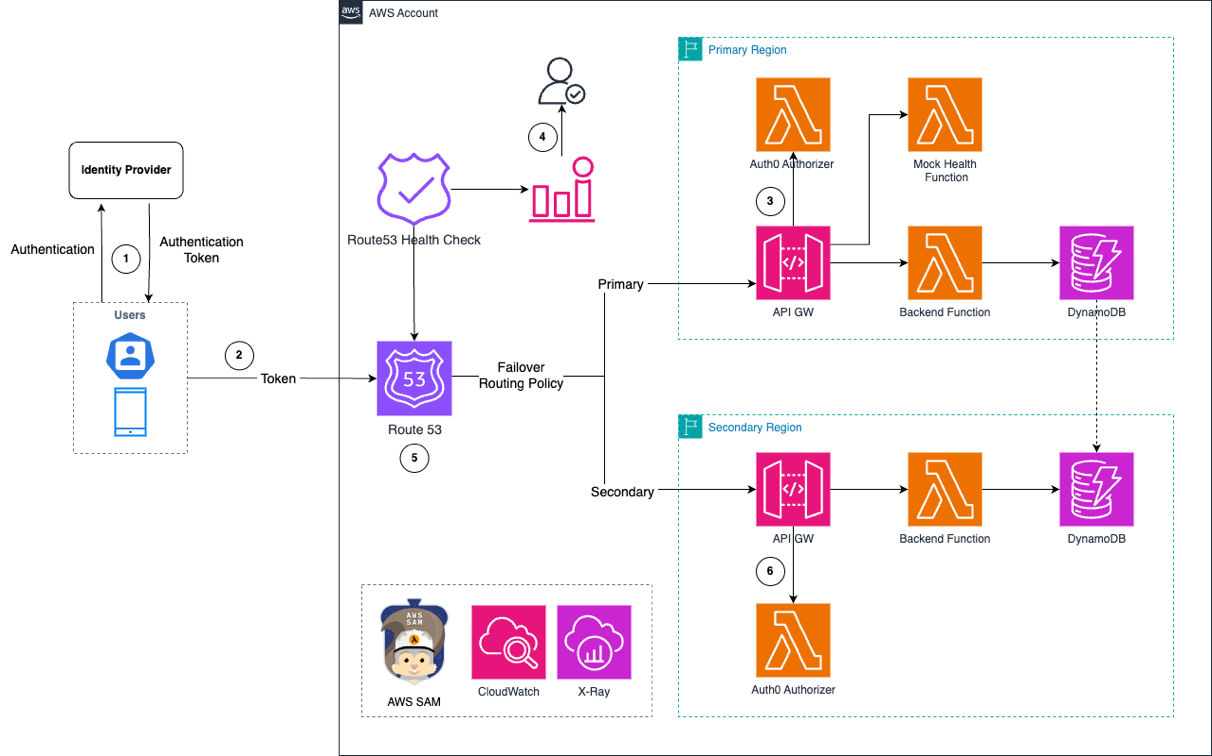
Figure 3: Multi-Region serverless authorizer workflow with Route 53 failover between primary and secondary Regions
The preceding figure shows the architecture, which demonstrates both failover and fallback capabilities through CloudWatch alarms and a manual approval process. This approach aligns with best practices for critical applications, where automated failover is not recommended despite being technically possible. Teams can use this approach to assess technical readiness, evaluate business impact, and make informed business decisions about timing and potential revenue implications. The demo implements a multi-Region serverless authorizer that serves as a reference architecture. Real-world implementations should carefully evaluate the failover strategies based on business criticality and operational requirements.
Testing multi-Region scenarios
The demo application hosts its frontend on Amazon Elastic Container Service (Amazon ECS). The Route 53 health check configuration in this GitHub defines key failover parameters:
- FailureThreshold: Specifies the number of consecutive health check failures before Route 53 marks an endpoint as unhealthy
- RequestInterval:
- Standard: 30-second interval ($0.50 per health check/month)
- Fast: 10-second intervals ($1.00 per health check/month)
The faster interval enables quicker failure detection. However, it increases health check costs through more logging, request handling, and backend compute resources. Temporary issues such as network glitches, transient errors, or third-party dependency delays may resolve within minutes. Implementing effective retry handling introduces unnecessary complexities and potential data inconsistencies. Choose the appropriate interval based on your business SLAs and cost considerations.
For testing failover scenarios, the architecture uses a mock Lambda function as the health check endpoint. We trigger CloudWatch alarms by simulating a response status code of 500 from this function, which prompts the manual failover decision process, as shown in the following figure.

Figure 4. Console screenshot showing multi-authorizer-health-check with status “Unhealthy”
DNS caching occurs at multiple levels (browser, operating system, ISP, and VPN). To observe failover behavior immediately, clear DNS resolver caches at each level
For more comprehensive resilience testing, consider implementing chaos engineering practices. You can use the chaos-lambda-extension to introduce latency or modify the function responses in a controlled manner. AWS Fault Injection Service (AWS FIS), a fully managed service, enables fault inject experiments to improve application resilience, performance, and observability. Combining these tools helps validate your multi-Region architectures under various controlled failure conditions.
Observability in multi-Region deployments
Implementing a multi-Region architecture is only the first step. Cross-Region observability necessitates monitoring Region A’s resource from Region B and the other way around. CloudWatch enables this through cross-account and cross-Region monitoring, providing consolidated logs and metrics in a single dashboard. Implement deep health checks to verify critical application functionality across AWS Regions.
Although AWS serverless services are distributed, identifying exact failures necessitates combining multiple data points. CloudWatch composite alarms help aggregate these insights, thus facilitating informed decisions. Consider implementing custom monitoring solutions for end-to-end request tracing across AWS Regions. This comprehensive view helps manage the complexity of multi-Region complexity and provides rapid responses to potential issues.
Conclusion
Building resilient multi-Region applications necessitate careful considerations of architecture patterns, costs, and operational complexities. AWS Serverless services, with their pay-for-value model, significantly reduce the challenges to implementing multi-Region architectures. The authorizer pattern demonstrated in this post shows how organizations can achieve high availability without the traditional overhead of idle infrastructure. Teams can follow these architectural patterns and best practices to build robust, cost-effective solutions that maintain service availability during service disruptions.
To learn the concepts of resilience, visit the AWS Developer Center. The complete source code for the demo used in this post is available in our GitHub repository. To expand your serverless knowledge, visit Serverless Land.