AWS Database Blog
Announcing vector search for Amazon ElastiCache
Vector search for Amazon ElastiCache is now generally available. You can now use ElastiCache to index, search, and update billions of high-dimensional vector embeddings from popular providers like Amazon Bedrock, Amazon SageMaker, Anthropic, and OpenAI-with latency as low as microseconds and up to 99% recall. Vector search for ElastiCache delivers high query throughput, real-time inline index updates, and supports using hierarchical navigable small worlds (HNSW) and flat search (FLAT) algorithms with Euclidean, cosine, and inner product distance metrics. To optimize the relevance of results, you can perform hybrid search with a mix of vector, tag and numeric filters. ElastiCache for Valkey delivers the lowest latency vector search with the highest throughput and best price-performance at 95%+ recall rate among popular vector databases on AWS.
Enhancing generative AI applications and agents
We have heard from customers that pilots of generative AI applications have struggled to scale into production workloads due to three main challenges. First, the cost associated with inference calls to large language models (LLMs) limit their use in large-scale workflows. Second, the latency introduced due to inference calls leads to a poor customer experience. Third, poor responses and hallucinations undermine the reliability of generative AI applications.
With vector search, ElastiCache now enables semantic caching for generative AI applications, allowing you to reduce the cost and latency of LLMs by serving cached responses for semantically similar prompts. You can use ElastiCache to deliver more personalized, context-aware responses by implementing memory mechanisms that surface cross-session conversation history to the LLMs. Vector search for ElastiCache can be used to power retrieval-augmented generation (RAG) on vast amounts of data to improve response relevance and reduce hallucinations by grounding outputs with real-world data.
Semantic caching
With semantic caching, you can reuse previous generative AI responses by using vector-based matching to find similarities between current and prior prompts. If a user’s prompt is semantically similar to a prior prompt, a cached response will be returned instead of making a new LLM inference call. Therefore, a semantic cache reduces the cost of generative AI applications and provides faster responses that improve the user experience. You can control which queries are routed to the cache by configuring similarity thresholds for prompts and applying tag or numeric metadata filters.
The inline real-time index updates provided by vector search for ElastiCache help ensure that the cache updates continuously as user prompts and LLM responses flow in. This real-time indexing is crucial to maintain freshness of cached results and cache hit rates, particularly for spiky traffic. In addition, ElastiCache simplifies operations for semantic caching through mature cache primitives such as per-key TTLs, configurable eviction strategies, atomic operations, and rich data structure and scripting support.
The following table shows the cost savings from a semantic cache. Consider a generative AI assistant that receives 100,000 questions per day with each question requiring 1,900 input tokens and 250 output tokens. The application uses Anthropic Claude Sonnet 4 as the foundational model and a semantic cache consisting of a cache.r7g.xlarge instance with two replicas. For simplicity, the cost of ancillary components such as EC2 instances and embedding generation are excluded since they are lower. The table shows that even with a modest cache hit ratio of 25%, a semantic cache provides up to 23% cost reduction for generative AI applications.
| Cache hit ratio | Total input tokens (M) | Total output tokens (M) | Answer generation cost per day | ElastiCache cost per day | Total cost per day | Potential savings |
| No cache | 190 | 25 | $945 | $0 | $945 | – |
| 10% | 171 | 23 | $851 | $23 | $874 | 8% |
| 25% | 143 | 19 | $709 | $23 | $732 | 23% |
| 50% | 95 | 13 | $473 | $23 | $496 | 48% |
| 75% | 48 | 6 | $236 | $23 | $260 | 73% |
| 90% | 19 | 3 | $95 | $23 | $118 | 88% |
Table 1: Ownership Cost of Generative AI Application with Semantic Cache
Conversational memory
Memory layers allow generative AI assistants and agents to retain and use past interactions to personalize responses and improve relevancy. However, simply aggregating all prior interactions into the prompt is ineffective since irrelevant extra tokens increase cost, degrade response quality, and risk exceeding the LLMs context window. Instead, you can use vector search to retrieve and provide only the most relevant data in the context for each LLM invocation.
ElastiCache for Valkey integrates with LangGraph and mem0, open-source memory layers for LLM applications and agents. These frameworks provide connectors to store and retrieve memories in Valkey, including both short-lived session context and longer-term memories reliant on vectors. Using mem0 or LangGraph, you can configure ElastiCache for Valkey as the memory store for agents that you host on Amazon Bedrock AgentCore Runtime. You can also use the same mem0 or LangGraph integration when you build agents with Strands Agents. Vector search for ElastiCache provides fast index updates, keeping memory up to date and making new memories immediately searchable. Low latency vector search makes memory lookups fast, enabling them to be implemented in the online path of every request, not just background tasks. Beyond vector search, ElastiCache for Valkey also provides caching primitives for session state, user preferences, and feature flags, providing a single service to store short-lived session state and long-term “memories” in one datastore.
ElastiCache for Valkey is a good fit when you want to build a self-managed memory layer with these open-source frameworks or when you need a low latency, customizable in-memory store. If you prefer a fully managed approach, you can use AgentCore Memory to have Bedrock handle memory storage for you.
Retrieval augmented generation (RAG)
RAG is the process of providing LLMs with up-to-date information in the prompt to improve the relevance of responses. RAG reduces hallucinations and improves factual accuracy by grounding outputs with real-world data sources. RAG applications use vector search to retrieve semantically relevant content from a knowledge base. Low latency vector search provided by ElastiCache makes it suitable for implementing RAG in workloads that have large datasets with millions of vectors and above. Further, support for online vector index updates makes ElastiCache suitable for AI assistants that need to ensure any user uploaded data is immediately searchable. ElastiCache is well suited for RAG in latency-sensitive applications that run small or customized models, such as real-time voice and streaming agents, where vector retrieval constitutes a significant share of overall latency.
The following diagram illustrates an example architecture using ElastiCache to implement a semantic cache, conversational memory, and RAG to enhance a generative AI application built on Bedrock AgentCore.
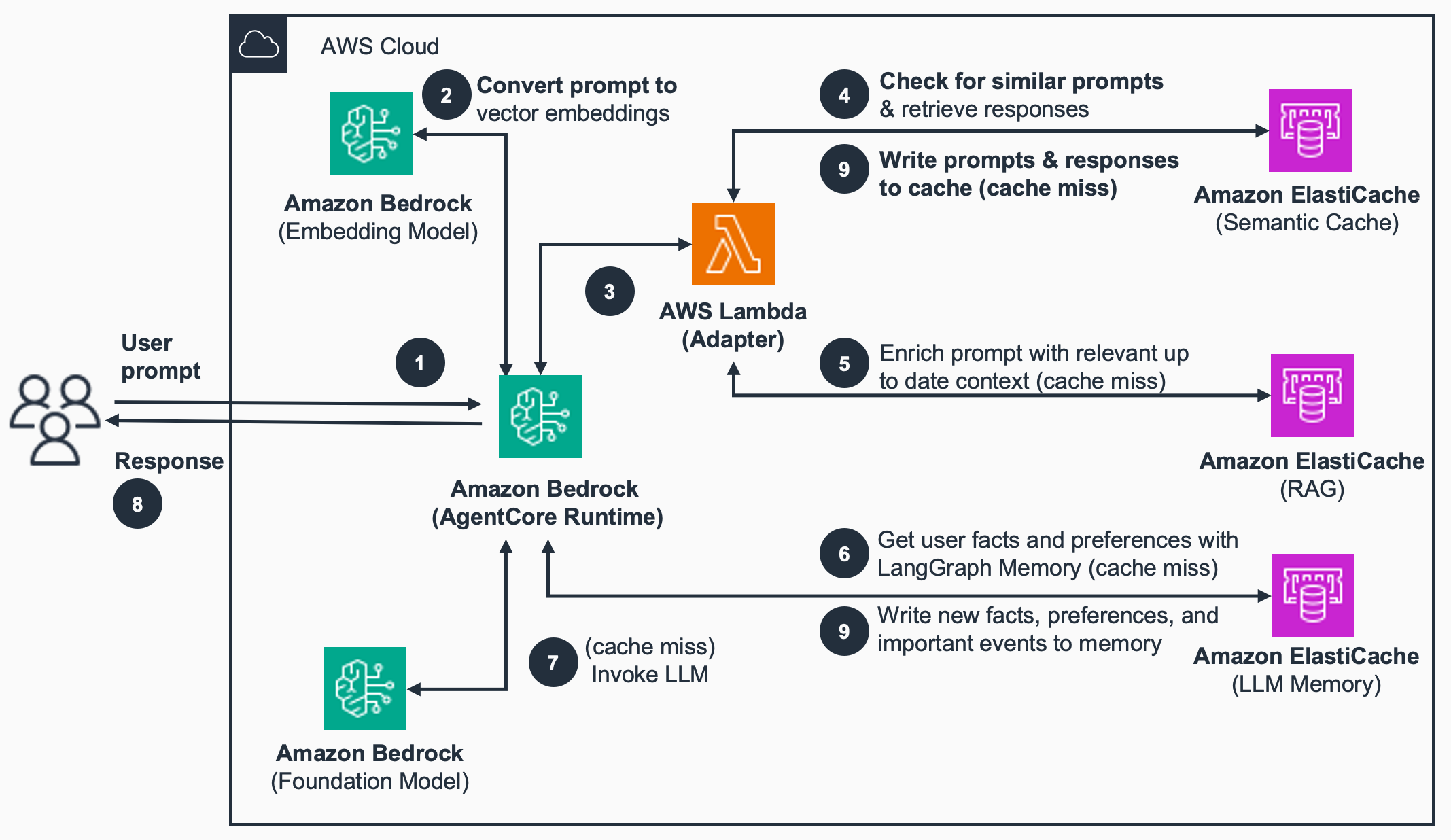
The three sample use cases above show how you can use vector search for ElastiCache to build production-ready generative AI applications that are cost-effective, faster, and provide higher quality responses. We have heard from customers that the implementation of semantic caching, memory, or RAG solutions at scale is constrained by the performance of the underlying vector search. Vector search for ElastiCache addresses this challenge through in-memory storage of vectors with linear horizontal scaling (adding shards) and multi-threading for performance that provides near-linear vertical scaling (using instances with more cpus). This enables you to store and search billions of vectors in-memory with low query latency and real-time index updates. Further, support for approximate nearest neighbour (ANN) algorithms, such as HNSW, that provide (O(log N)) time complexity, enables the best performance at the high levels of recall and scale demanded by real-time applications.
Getting started with vector search for ElastiCache
In the following sections, we create a simple application using ElastiCache for Valkey as a vector store. For simplicity, we use vector search to enable semantic search capability on a corpus of web pages. The code builds a pipeline to generate embeddings, store them within ElastiCache, create a vector index, and query semantically similar content.
Prerequisites
You must have the following prerequisites:
- An AWS account
- The AWS Command Line Interface (AWS CLI)
- Amazon Bedrock model access enabled for Amazon Titan Text Embeddings V2 in the
us-east-1AWS Region - Python 3.11 with the pip package manager
Create an ElastiCache cluster to use vector search
You can create an ElastiCache cluster to use vector search within the AWS CLI (see the following code) or AWS Management Console. Vector search is available for ElastiCache version 8.2 for Valkey.
Next, create an Amazon Elastic Compute Cloud (Amazon EC2) instance and ensure it can connect to the ElastiCache cluster nodes by following the steps outlined in Accessing your ElastiCache cluster or replication group.
SSH into your EC2 instance, and install the following Python libraries:
Create vector embeddings using Amazon Titan Text Embeddings
In this step, you populate the vector store with the text data that builds the foundation of the semantic search body. This data will later be used for semantic search queries and represents the knowledge base of a RAG model.
First, the text data is loaded and split into chunks using a document loader from the LangChain library. For the purposes of this post, we retrieve data from a webpage, but many other data sources are supported through the same library. The LangChain AWS package also provides integration with multiple AWS services.
Next, the text chunks are converted into vector embeddings using an embedding model. You can use Amazon Titan Text Embeddings or other embedding models to create vector embeddings, which are available in Amazon Bedrock. After you generate the vector embeddings using the Amazon Titan Text Embeddings model, you can connect to your ElastiCache cluster and save these embeddings to Valkey using the HSET command.
You have successfully populated the vector embeddings to Valkey. Next, you will create a vector index to enable fast vector similarity search.
Create a vector index
To query your vector data, you first need to create a vector index using the FT.CREATE command in Valkey or the equivalent ft().create_index() API in valkey-py. Vector indexes are constructed and maintained over a subset of the Valkey keyspace. Vectors can be saved in JSON or HASH data types, and modifications to the vector data are automatically updated in a keyspace of the vector index.
The HNSW algorithm gives the developer three parameters to adjust the CPU and memory consumption vs recall. We use the cosine distance as a measure of similarity between two points in vector space, which represents the semantic similarity of the original text chunks. A small cosine distance means the embedding vectors are pointing almost in the same direction, suggesting the texts are very similar, while a large cosine distance indicates the embedding vectors point in different directions, implying the texts have dissimilar meanings.
Search vector space
Finally, you can use the FT.SEARCH command in Valkey or the equivalent ft().search() API in valkey-py to query your vector data. First, create the text embedding of the search query string:
Next, search the vector data using the query string embedding. The following example uses approximate nearest neighbor search to retrieve the K most similar document chunks matching a query string:
For example, when using cosine distance, the score value ranges from 0 to 2, where a value closer to 0 means higher similarity to the search query. Here are the three most similar document chunks based on cosine distance:
You can retrieve the individual document chunks using the id attribute of the returned documents. In a RAG application, these semantic search results can be used to enrich the context of a prompt to a foundation model to increase the relevancy of the LLM output.
The search result with the lowest cosine distance to the search query contains the following text.
To learn more, refer to the following sample semantic search application using ElastiCache as a vector store.
Clean up
To avoid incurring additional cost, delete all the resources you created previously:
Scaling and performance of vector search for ElastiCache
When using vector search for ElastiCache you can scale your cluster through all three supported modes – vertical scaling, horizontal scaling, or adding more replicas. Vertical scaling, upgrading to instances with more vCPUs, linearly increases throughput for both querying and ingesting vectors. If you need to boost query performance specifically, adding read replicas increases query throughput without affecting ingestion. Horizontal scaling by adding more shards delivers linear improvements in ingestion performance and recall accuracy. However, there’s a trade-off: because queries must fan out across more shards, this introduces additional network and coordination overhead that can increase tail latencies and reduce query throughput.
The following table shows the performance gains from horizontal and vertical scaling with the performance of a cache.r7g.large instance that has two-cores as the baseline (upper left, marked in green). The tests were performed on a one shard cluster without replicas using vectorDBBench on the GIST-dataset (1 million vectors, 960 dimensions). The tests use 100 read clients and 50 write clients with HNSW parameters set as M = 32, EF_construction = 300, EF_runtime = 128, and K = 10. The table shows throughput gains of up to 43x achievable from vertical scaling.
| Relative Queries Per Second (QPS) | 1-Shard | 2-shard | 4-Shard | 8-Shard |
| cache.r7g.large | 1 | 1.1 | 1.2 | 1.4 |
| cache.r7g.xlarge | 3.2 | 3.5 | 3.8 | 4.1 |
| cache.r7g.2xlarge | 7.3 | 7.9 | 8.6 | 9.5 |
| cache.r7g.4xlarge | 14.9 | 15.9 | 16.9 | 18.3 |
| cache.r7g.8xlarge | 29.7 | 30.4 | 31.1 | 29.9 |
| cache.r7g.16xlarge | 42.9 | 37.5 | 31.8 | 28.8 |
Table 2: Scaling Performance – Horizontal vs Vertical Scaling.
The following table shows the performance results measured using vectorDBBench on a single shard with 2 replicas using r7g.16xlarge instances. HNSW indexes were used with parameters as M =32, EF_construction = 300, EF_runtime = 100 and K = 10. The table shows that vector search for ElastiCache can support up to tens of thousands of search queries with latency as low as microseconds with recall up to 99%.
| Dataset | Vector dimensions | Total vectors | Recall | Average query latency (ms, with single client) | Queries per second (with 128 clients) | Average query latency (with 128 clients) | Load time (s) |
| SIFT | 128 | 1M | 95% | 0.8 | 26,451 | 4.9 | 87 |
| GIST | 960 | 1M | 91% | 3.4 | 16,902 | 6.7 | 130 |
| Cohere | 768 | 1M | 99% | 2.0 | 13783 | 9.5 | 520 |
| Cohere | 768 | 10M | 95% | 3.5 | 18,723 | 8.0 | 5,555 |
| OpenAI | 1536 | 5 M | 94% | 3.9 | 17,607 | 8.5 | 3,335 |
| Big-ANN | 128 | 10 M | 93% | 3.1 | 11,135 | 10.4 | 1,123 |
| Big-ANN | 128 | 100M | 94% | 3.8 | 10,031 | 11.6 | 10,726 |
Table 3: Throughput and Latency Performance.
Conclusion
In this post, we explored vector search for ElastiCache, covering example use cases in generative AI applications, a sample implementation of semantic search, and scaling concepts. Vector search is a new capability on ElastiCache, enabling low-latency, in-memory storage of vectors, with zero-downtime scalability and high-performance search across billions of vectors. Vector search for ElastiCache is built with valkey-search and remains fully compatible with the OSS module.
Vector search is available for ElastiCache version 8.2 for Valkey on node-based clusters in all AWS Regions at no additional cost. To get started, create a new Valkey 8.2 cluster using the console, AWS SDK, or AWS CLI. You can also use vector search on your existing cluster by upgrading from any previous version of Valkey or Redis OSS to Valkey 8.2 in a few clicks with no downtime. You can use this capability with Valkey client libraries, such as valkey-glide, valkey-py, valkey-java, and valkey-go. To learn more about vector search, the list of supported commands or version management for ElastiCache, check out the ElastiCache documentation.