AWS Database Blog
Automating vector embedding generation in Amazon Aurora PostgreSQL with Amazon Bedrock
Vector embeddings have deeply changed how we interact with unstructured data in applications by using generative AI. Embeddings are mathematical representations that enable semantic search, recommendation systems, and various natural language processing tasks by capturing the essence of text, images, and other content in a format that machines can process efficiently.
For organizations building applications that make use of Retrieval-Augmented Generation (RAG) or other AI-powered solutions, maintaining up-to-date vector embeddings is essential. When new data is inserted or modified in your database, making sure that the corresponding embeddings are generated promptly and accurately is key for maintaining the quality and relevance of AI-driven features.
Although Amazon Bedrock offers managed RAG solutions that handle embedding generation and retrieval automatically, many organizations have specific requirements that lead them to implement custom vector database solutions. This can be achieved by using PostgreSQL with the open source pgvector extension. These requirements might include tight integration with existing applications, specific performance optimizations, or data processing workflows.
In this post, we explore several approaches for automating the generation of vector embedding in Amazon Aurora PostgreSQL-Compatible Edition when data is inserted or modified in the database. Each approach offers different trade-offs in terms of complexity, latency, reliability, and scalability, allowing you to choose the best fit for your specific application needs.
Solution overview
When implementing a vector database by using Aurora PostgreSQL with the pgvector extension, you need a reliable system to create and update embeddings whenever data changes occur. The general workflow involves the following steps:
- Detect when new or modified data requires embedding.
- Send the content to Amazon Bedrock embedding models.
- Receive the generated embedding vectors.
- Store these vectors alongside your original data.
In this post, we use Amazon Bedrock with the Amazon Titan foundation model (FM) because it delivers production-grade vector embeddings without managing additional infrastructure. Amazon Titan embeddings excel at capturing semantic relationships in your text data, enabling similarity searches and recommendations right where your data lives.
In this post we choose Amazon Titan that offers the right balance of performance and simplicity for most production workloads, but you can choose other models like Cohere Embed or Anthropic’s Claude that are supported by Amazon Bedrock, so, you have the flexibility to choose the embedding solution that best fits your specific semantic search or document retrieval needs. Additionally, you can explore alternatives such as Amazon SageMaker AI with custom models for specialized use cases, or open source options such as Sentence Transformers when working with smaller datasets.
Prerequisites
Before proceeding with any of the implementation approaches in this post, make sure you have met the following prerequisites:
- An Aurora PostgreSQL cluster with the pgvector extension installed.
- The proper AWS Identity and Access Management (IAM) roles and policies configured for Amazon Bedrock access.
- For AWS Lambda based solutions, the appropriate virtual private cloud (VPC) configurations to allow Lambda functions to access both your database and Amazon Bedrock.
- For the
aws_mlextension approach, confirmed compatibility with your database version. - For
pg_cron, the extension must be enabled and configured correctly.
You can use the GitHub repository to deploy a preconfigured environment that meets these requirements. The repository contains an AWS Cloud Development Kit (AWS CDK) application that provisions the following:
- An Amazon Aurora Serverless v2 for PostgreSQL cluster
- An Amazon Elastic Compute Cloud (Amazon EC2) bastion host for secure database access and running migration scripts
- The required AWS infrastructure components configured to support the demonstration approaches, including:
- Lambda functions
- Amazon Simple Queue Service (Amazon SQS) queues
- Associated IAM roles and security groups
- Networking resources (VPC, subnets, route tables)
For detailed deployment instructions and access to the source code referenced in this post, see the README.md file in the repository.
Implementation approaches
We examine five distinct implementation approaches for automating this workflow, each with its own unique characteristics:
- Direct synchronous calls using database triggers and the aws_ml extension provide simplicity and immediate consistency at the cost of slower performances during transactions.
- AWS Lambda orchestrated synchronous calls using database triggers and the aws_lambda extension offer better separation of duties at the cost of slower performances during transactions.
- Lambda orchestrated asynchronous calls using event-driven invocations improve database performance at the cost of temporary inconsistency.
- Queue-based asynchronous processing with Amazon SQS and batch processing provides the best scalability and resilience for high-volume scenarios while introducing more architectural components.
- Scheduled periodic asynchronous updates using the pg_cron extension offer a simple approach for applications where real-time embedding updates aren’t critical.
For our tests, we use two database tables:
documents: Stores document metadata and content with fields for title, content, and processing status tracking (PENDING/PROCESSING/COMPLETED/ERROR).document_embeddings: Stores vector embeddings (1536 dimensions for Titan) linked to documents through foreign key.
We are assuming that client applications store and modify text in the documents table. You can also find references to this setup in the GitHub repository, where you will find:
- The AWS CDK stack to deploy an Aurora Serverless PostgreSQL database with Amazon EC2 bastion host.
- The
init-public.sqlscript to install database extensions in thepublicdatabase schema. - A dedicated folder with AWS CDK, SQL, and Lambda code for each approach.
Now, let’s dive into the five approaches, and analyze their benefits and limitations.
Design considerations
When implementing these approaches in a production environment, we suggest you carefully evaluate your specific requirements and take the following limitations into consideration to design an architecture that best suits your needs:
- API rate limits – Amazon Bedrock has rate limits that vary by model and account. High-volume applications might require request throttling or batching.
- Token limits – Text embedding models have maximum token limits. Very long text fields might require chunking strategies not covered in these examples.
- Cost implications – Each approach has different cost implications based on the frequency of API calls, Lambda invocations, and additional AWS services used.
- Latency requirements – The trade-off between real-time embedding generation and system performance must be evaluated based on your application needs and business requirements.
- Database performance – Synchronous approaches can impact database throughput and ingestion time, especially during peak load.
- Error handling – The more complex approach provide better error handling and retry capabilities.
Approach 1: Database triggers with the aws_ml extension (synchronous)
This approach uses PostgreSQL triggers to detect data changes and immediately calls Amazon Bedrock by using the aws_ml extension to generate embeddings. The following diagram illustrates this workflow.

This trigger monitors the text column in the documents table. Whenever content changes, the trigger calls the store_embedding function, which performs the following actions:
- Generate the vector embeddings by calling the
generate_embeddingfunction. - Store the embedding results in the
document_embeddingstable.
The generate_embedding function performs a synchronous call to Amazon Bedrock, passing the modified text and record identifier as parameters.
To better visualize this process and the interactions between different components, the following sequence diagram illustrates the step-by-step workflow. This diagram provides a representation of the flow of data and control, showing how the function interacts with Amazon Bedrock and how the embedding is generated and returned:
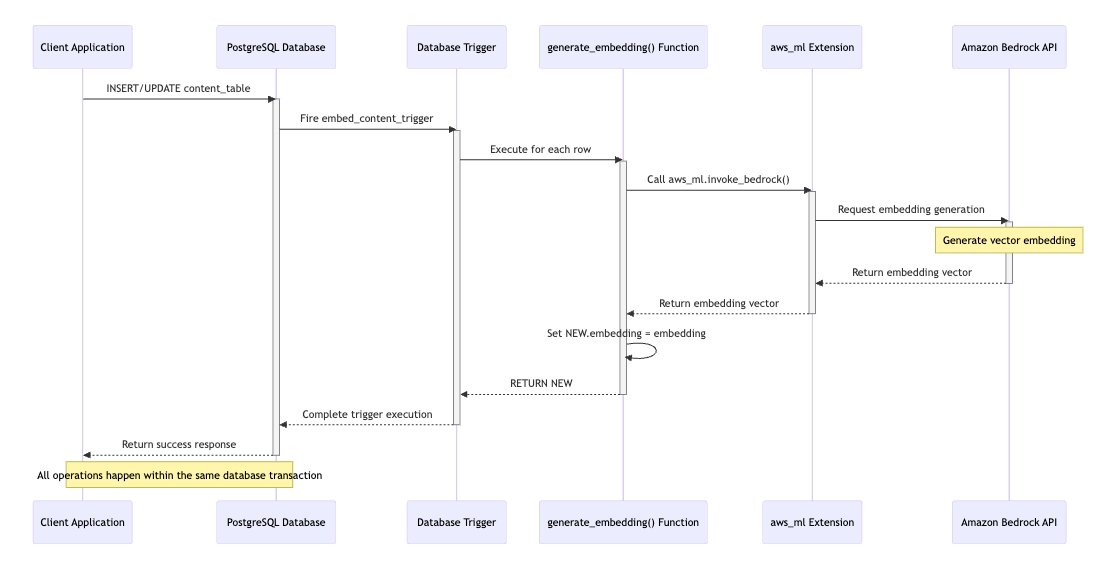
The PostgreSQL trigger automatically runs in response to specific database events, such as:
- Data insertions (INSERT)
- Changes to existing records (UPDATE)
For this embedding generation workflow, we configure triggers to run after insertions or updates of data to the content column. You will find an example and a full implementation in the project repository under the dedicated folder, 01_rds_bedrock.
The database trigger invokes a function that uses the aws_ml PostgreSQL extension, which provides a convenient way to make synchronous calls to Amazon Bedrock directly from within the Aurora database. To implement this, make sure that your cluster has a role with the necessary permissions associated with Amazon Bedrock.
Aurora supports the required minimum version 2.0 of the aws_ml extension starting from PostgreSQL versions 16.1, 15.5, and 14.10. aws_ml 2.0 provides two additional functions that you can use to invoke Amazon Bedrock services: aws_bedrock.invoke_model and aws_bedrock.invoke_model_get_embeddings. The following code snippet shows how to use the aws_ml extension from within a database function and utilize the result to store the vector embeddings in the dedicated database table:
The approach in this section, combines simplicity with real-time consistency by integrating the functionality into the database workflows. This eliminates the need for additional infrastructure while ensuring content and vector representations remain synchronized.
The synchronous processing model affects transaction times and presents scaling considerations, but it offers a straightforward implementation path requiring minimal development effort. The following table lists additional pros and cons of this first approach.
| Pros | Cons |
| Minimalist implementation approach: This solution requires the fewest components compared to other solutions mentioned in this post, eliminating the need for external services or middleware layers and making the debugging process simpler. | Extended transaction duration: Because embedding generation happens synchronously within database transactions, insert and update operations can take significantly longer to complete. This increases lock contention and might noticeably impact application performance, particularly for operations that modify multiple rows simultaneously. |
| Real-time consistency: Embeddings are generated at the moment data is written, with the database engine making sure that vector representations are always in sync with the underlying content. This reduces scenarios where stale embeddings might exist and provides more accurate search and recommendation results immediately after content changes. | Timeout risks: When processing large documents or high volumes of transactions, the time required to generate embeddings can exceed database connection timeout settings. This poses a significant operational risk, potentially causing application errors or data inconsistencies when transactions are interrupted. |
| Simplicity: The architecture operates without additional AWS services beyond the database and Amazon Bedrock, reducing both complexity and operational costs. This makes the solution particularly appealing for organizations with limited DevOps resources. | Limited error resilience: The trigger-based approach provides minimal capabilities for handling API errors, rate limiting, and retry logic. Failed embedding generation attempts can potentially block critical database operations with no built-in fallback mechanisms, requiring custom error handling implementation. |
| Scaling limitations: The embedding generation workload scales in direct proportion to database write operations, creating a tight coupling between database activity and API usage. During high-traffic periods, this can lead to Amazon Bedrock API throttling or quota exceeding issues that directly impact database performance. |
Approach 2: Database triggers with the aws_lambda extension (synchronous)
This approach uses PostgreSQL triggers to invoke a Lambda function synchronously, which then calls Amazon Bedrock to generate embeddings. The following diagram illustrates the workflow.

With this approach, you can automatically create embeddings for new content through the following process:
- A database trigger activates whenever new content is inserted into or updated in the
documentstable. - For each newly inserted or updated row, the system synchronously invokes the Lambda function.
- The Lambda function uses Amazon Bedrock to generate embeddings.
- Generated embedding vectors are returned to the database trigger function.
- The embedding data is then stored in the
document_embeddingstable.
This happens within the same database transaction so that the documents are immediately processed while maintaining a separation between the database and AI components.
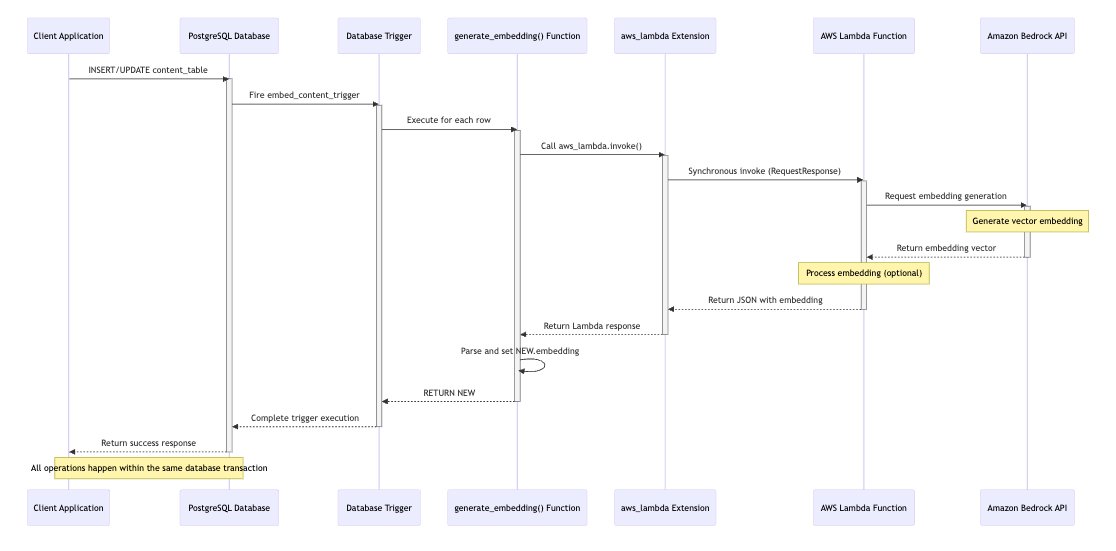
When you need external systems to react to database changes, invoking Lambda functions from within PostgreSQL can be an effective approach to decouple the embedding vectors generation logic from the database.
Both Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Aurora PostgreSQL-Compatible support this integration through the aws_lambda extension, which provides the invoke method. This capability alleviates the need for intermediate polling mechanisms or additional application logic.
In this approach, we use the aws_lambda PostgreSQL extension’s invoke method with the RequestResponse invocation type parameter. This provides synchronous execution, so the database waits for the Lambda function to return a response before proceeding with subsequent operations. Let’s look at how this translates into actual code:
The Lambda function code that follows invokes the Amazon Titan model through Amazon Bedrock. This pattern decouples the database from the large language model (LLM), giving you the flexibility to use various APIs and services for generating embedding vectors as needed.
The database triggers with this aws_lambda extension approach decouple embedding generation from core database functions while maintaining synchronous processing. This architecture allows for more sophisticated processing and better error handling through Lambda, although it still faces transaction duration challenges and introduces Lambda-specific considerations such as cold starts. The following table lists additional pros and cons of this second approach.
| Pros | Cons |
| Logic decoupling: Separates embedding generation logic from database code, allowing for independent updates and management of each component. | Transaction blocking: Still blocks database transactions while waiting for both Lambda execution and Amazon Bedrock API responses. |
| Enhanced processing capabilities: Enables more complex preprocessing and postprocessing operations in Lambda by using full programming languages rather than PL/pgSQL. | Lambda cold starts: Introduces additional latency when Lambda functions need to initialize from cold starts, especially with infrequent writes. |
| Improved monitoring: Better error handling and observability through Amazon CloudWatch logs, metrics, and alarms for operational insights. | Timeout risks: Database operations might fail if Lambda execution exceeds configured timeouts during embedding generation. |
| Additional configuration: Requires setup of IAM permissions, VPC configurations, and network access between the database and Lambda. |
Approach 3: Database triggers with the aws_lambda extension (asynchronous)
This approach uses PostgreSQL triggers to invoke a Lambda function asynchronously, which then generates embeddings and writes them back to the database. The following diagram illustrates the workflow.

With this approach, the database trigger invokes the Lambda function asynchronously, allowing it to return immediately without blocking the database transaction. This means your database operations can proceed without waiting for Amazon Bedrock to complete the embedding vector generation. This approach is beneficial when you need to minimize overhead in database transactions.
After Amazon Bedrock generates the vector embeddings, the Lambda function uses the Amazon Relational Database Service (Amazon RDS) Data API to write the results to the document_embeddings table.
For a detailed understanding of this workflow, see the following sequence diagram, which illustrates each step of the embedding process.
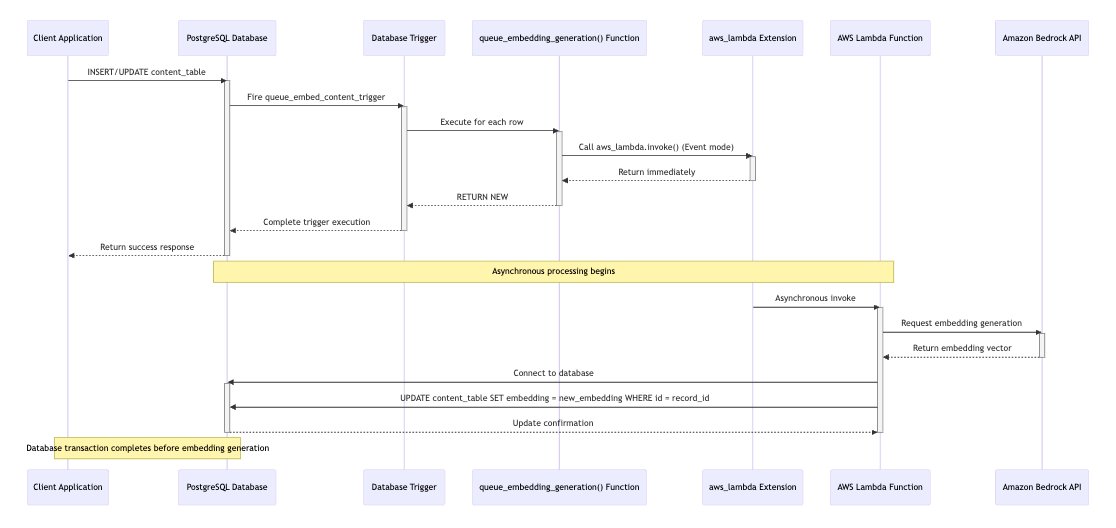
The Amazon RDS Data API updates vector embedding from the Lambda function. This API is an HTTP-based interface for accessing Amazon RDS databases without managing connections; therefore, a persistent connection to the database is not required. With the Amazon RDS Data API, you don’t need to pass credentials with calls to the Amazon RDS Data API because it uses database credentials stored in AWS Secrets Manager.
The key advantages of using the Amazon RDS Data API are eliminating connection management complexity, enabling simplified IAM based authentication without managing credentials, and conserving database resources during function idle periods, all contributing to improved scalability and reduced complexity in serverless architectures. To see this in action, here’s the Lambda function implementation code:
This asynchronous Lambda approach prioritizes database performance by decoupling embedding generation from transaction processing. This creates a nonblocking architecture that significantly improves write operation speed and eliminates timeout risks, but it introduces eventual consistency and more complex error handling patterns. This design is particularly well-suited for high-volume write scenarios where immediate embedding availability isn’t strictly required. The following table lists additional pros and cons of this third approach.
| Pros | Cons |
| Nonblocking transactions: Database operations complete quickly without waiting for embedding generation, improving overall application responsiveness. | Eventual consistency: Data exists temporarily without embeddings, creating a time window where vector search results might be incomplete or inaccurate. |
| Enhanced write performance: Database write operations complete faster and support higher throughput for content creation and updates. | Complex error handling: More challenging to manage and retry failed Lambda invocations with no immediate feedback loop. |
| Timeout elimination: No risk of transaction timeouts caused by Amazon Bedrock API latency because processing happens after database commit. | Status tracking complexity: More difficult to monitor embedding generation progress and handle edge cases where embeddings fail to generate. |
| High-volume scalability: Better scalability for high-volume insert and update scenarios with embedding generation workload distributed across time. |
Approach 4: Amazon SQS queue with Lambda batch processing (asynchronous)
This approach uses database triggers to send messages to an Amazon SQS queue, which are then batch processed by a Lambda function that generates embeddings for multiple records at once. The following diagram illustrates the workflow.
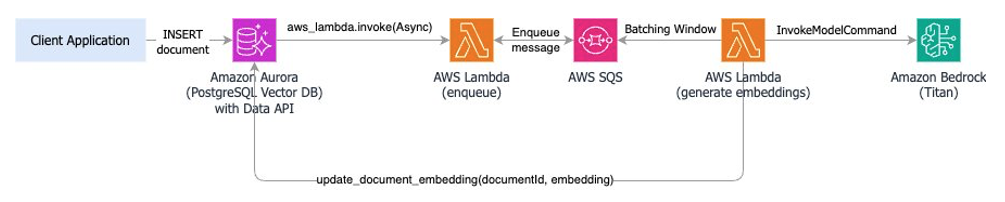
In this solution, the trigger still invokes the Lambda function asynchronously, shortening the transaction time after inserting text in the documents table. Incorporating Amazon SQS enables batch processing of LLM requests, enhancing the retry mechanism and allowing the systems to operate independently and scale during high-volume periods.
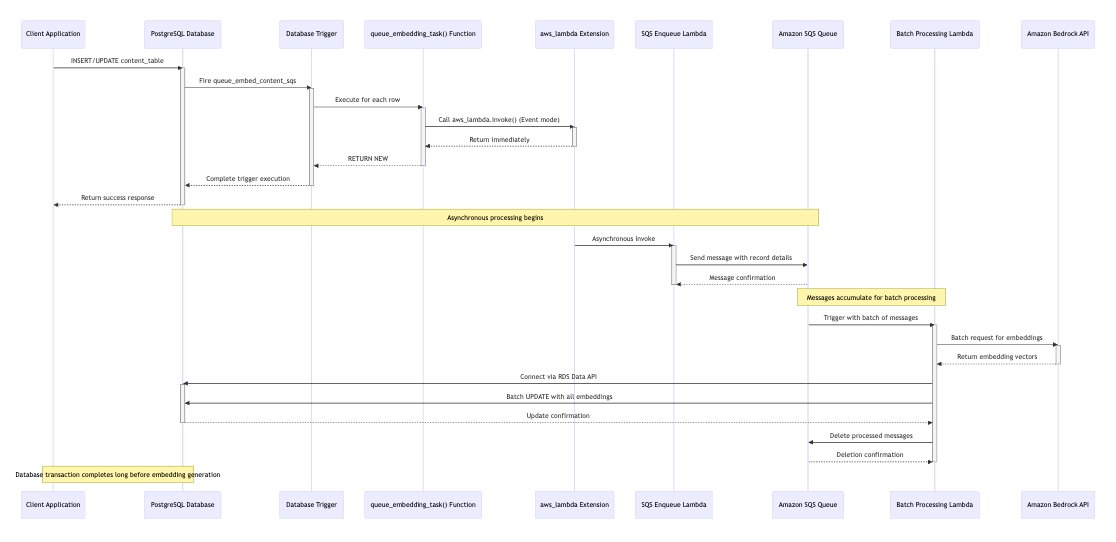
To implement this approach you can use the repository instructions in the 04_rds_lambda_sqs section, where you will find:
- AWS CDK code to implement this pattern.
- SQL code for triggers and procedures.
- TypeScript code for Lambda functions.
We take advantage of the flexible batching capabilities of Amazon SQS that let you configure both the number of messages processed together and the time window for accumulating messages. You can tailor these parameters to your specific requirements, as shown in the following AWS CDK code that creates a Lambda Function with SQS integration:
We used the Amazon SQS queue with Lambda batch processing architecture to optimize for scale and resilience by introducing message queuing and batch processing. This design can improve cost-efficiency and throughput when handling high volumes of embedding requests, while providing robust error handling through the Amazon SQS built-in retry mechanisms.
The trade-off comes in with higher latency between content creation and embedding availability, making it better suited for high-scale production systems where operational robustness takes priority. The following table lists additional pros and cons of this fourth approach.
| Pros | Cons |
| Scalability: Highly scalable and resilient architecture capable of handling production workloads with traffic spikes and sustained high volume. | Increased embedding latency: Longer delay between data insertion and embedding availability because of queuing and batch processing. |
| Efficient resource usage: Batching of embedding requests to Amazon Bedrock reduces API calls and optimizes for cost and throughput limits. | Operational overhead: Additional AWS services increase monitoring requirements and operational complexity. |
| Built-in resilience: Amazon SQS provides automatic retry mechanisms with configurable visibility timeouts and dead-letter queue (DLQ) support. | Integration complexity: Requires careful monitoring and DLQ configuration to handle error cases properly. |
| Cost optimization: More cost-effective for high-volume scenarios through batching and efficient resource utilization. | |
| Workload management: Decoupling of components allows for better rate limiting and load management across the system. |
Approach 5: Periodic updates scheduled with the pg_cron extension (asynchronous)
This approach uses pg_cron to schedule periodic jobs that check for new or modified records and generate embeddings in batches.
pg_cron is an open source, cron-based job scheduler for PostgreSQL that runs as an extension of the database. It allows you to schedule and execute SQL commands or calls to stored procedures using familiar cron, Linux-like syntax. The following diagram illustrates the workflow.
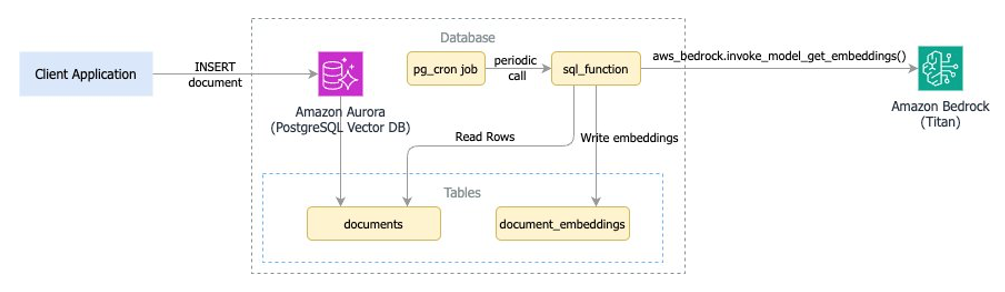
In this approach, documents are written with a status column set to PENDING to mark them for future processing. We have scheduled a pg_cron job to run periodically (every two minutes in this case, but this is configurable) to perform the following actions:
- Fetch all rows requiring processing (SELECT … FOR NO KEY UPDATE SKIP LOCKED … WHERE Status = ‘PENDING’ LIMIT <x>). Eventually the job can be configured to fetch a limited number of rows (LIMIT clause) to standardize the batch size.
- Mark the status of the fetched rows as
PROCESSING. - Generate embedding vectors by using Amazon Bedrock.
- Update the
document_embeddingtable with the resulting embedding values. - Update the
documentstable status toCOMPLETEDfor each processed row.
With this approach, we introduce a batching processing on the database side, and this can eventually scale more by scheduling additional cron jobs.Because this implementation doesn’t use database triggers, the solution has no performance impact on the original database transactions that write documents to the database, but it’s worth to note that there are still few cons related to this approach: they are listed at the end of this section.
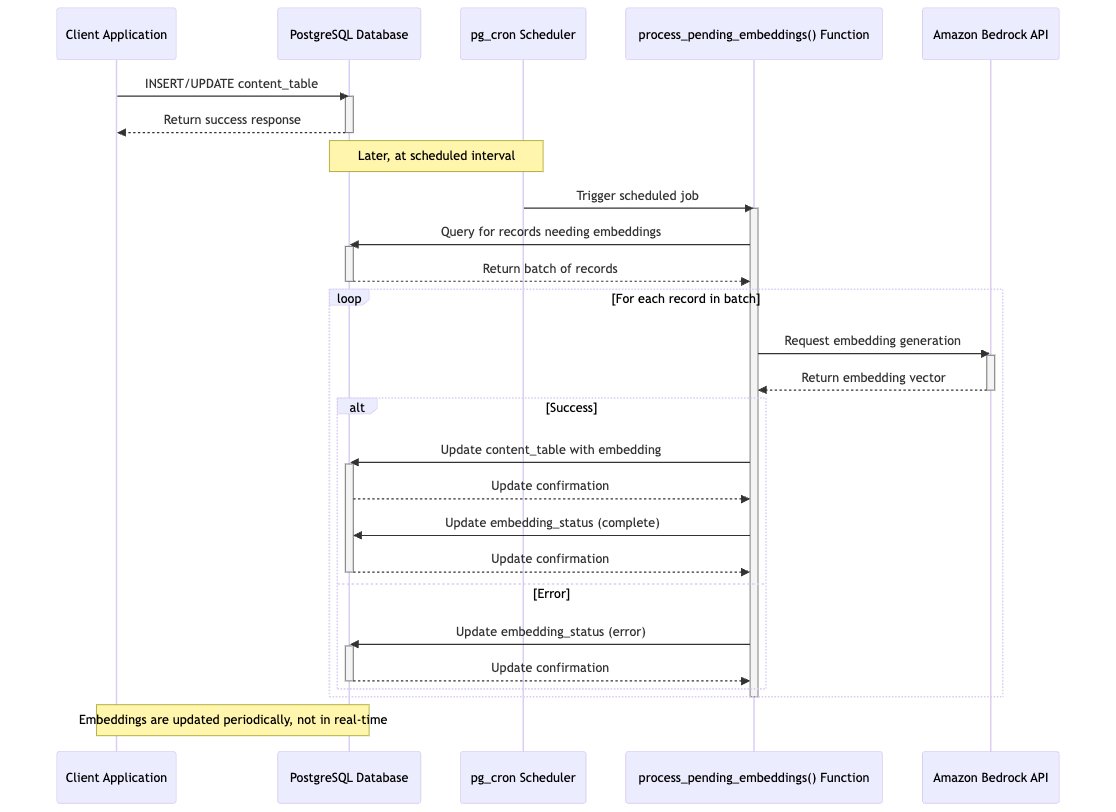
For implementation details of this setup, see the SQL code available in the 05_rds_polling section of the repository.
As shown in the following code, we configured the pg_cron schedule to execute every two minutes. pg_cron offers flexible scheduling options to customize job periodicity. You can use standard cron expressions, conveniently named schedules such as @hourly or @daily, or simple interval syntax such as 1 minute or 1 day. You can adjust these parameters through the cron.schedule function to control execution frequency based on your workload requirements and processing windows.
Also, the pg_cron extension offers various administrative commands that allow you to:
- View currently scheduled jobs.
- Examine job execution outputs and details.
- Remove scheduled jobs when necessary.
As previously mentioned, we use a dedicated function to retrieve all rows with PENDING status, and then we iterate through them to generate embedding vectors for each document. Throughout this process, we track any processing errors, updating document statuses and maintaining an error counter.
If errors are detected upon completion, we use the PostgreSQL RAISE function to notify administrators of issues. In a production environment, you would likely implement more sophisticated error handling strategies—such as an automatic retry mechanism with exponential backoff—alerting systems, or dedicated error logging to achieve reliable processing of all documents.
Let’s examine the database function’s complete implementation to better understand these concepts:
The pg_cron approach offers a balanced solution that prioritizes database performance and operational simplicity over real-time consistency. By processing embeddings in scheduled batches, this method reduces API pressure and provides robust error handling while keeping the entire solution within the database ecosystem.
The main trade-off is increased latency between content updates and embedding availability, making it well-suited for systems where near real-time vector search is acceptable and operational simplicity is valued. The following table lists additional pros and cons of this fifth approach.
| Pros | Cons |
| Self-contained architecture: Simplifies implementation with minimal external dependencies, keeping the entire solution within the database. | Increased update latency: Higher delay between data changes and embedding updates based on scheduled frequency. |
| Efficient batch processing: Improves throughput and cost-efficiency with the Amazon Bedrock API through optimized batch requests. | Database load impact: Resource-intensive periodic scans might impact database performance during busy periods. |
| Robust error management: Built-in error handling and retry logic with detailed status tracking for operational visibility. | Query complexity: Requires carefully optimized queries to efficiently identify changed records without excessive table scanning. |
| Processing control: Fine-grained control over processing frequency and batch size to balance resource usage and latency. | |
| API protection: Reduced risk of rate limiting or throttling through controlled, predictable API call patterns. |
Decision tree
After reviewing these five approaches for generating embeddings in Aurora PostgreSQL-Compatible, you might be wondering which method is best for your specific use case. Here’s a practical decision tree to help you choose:
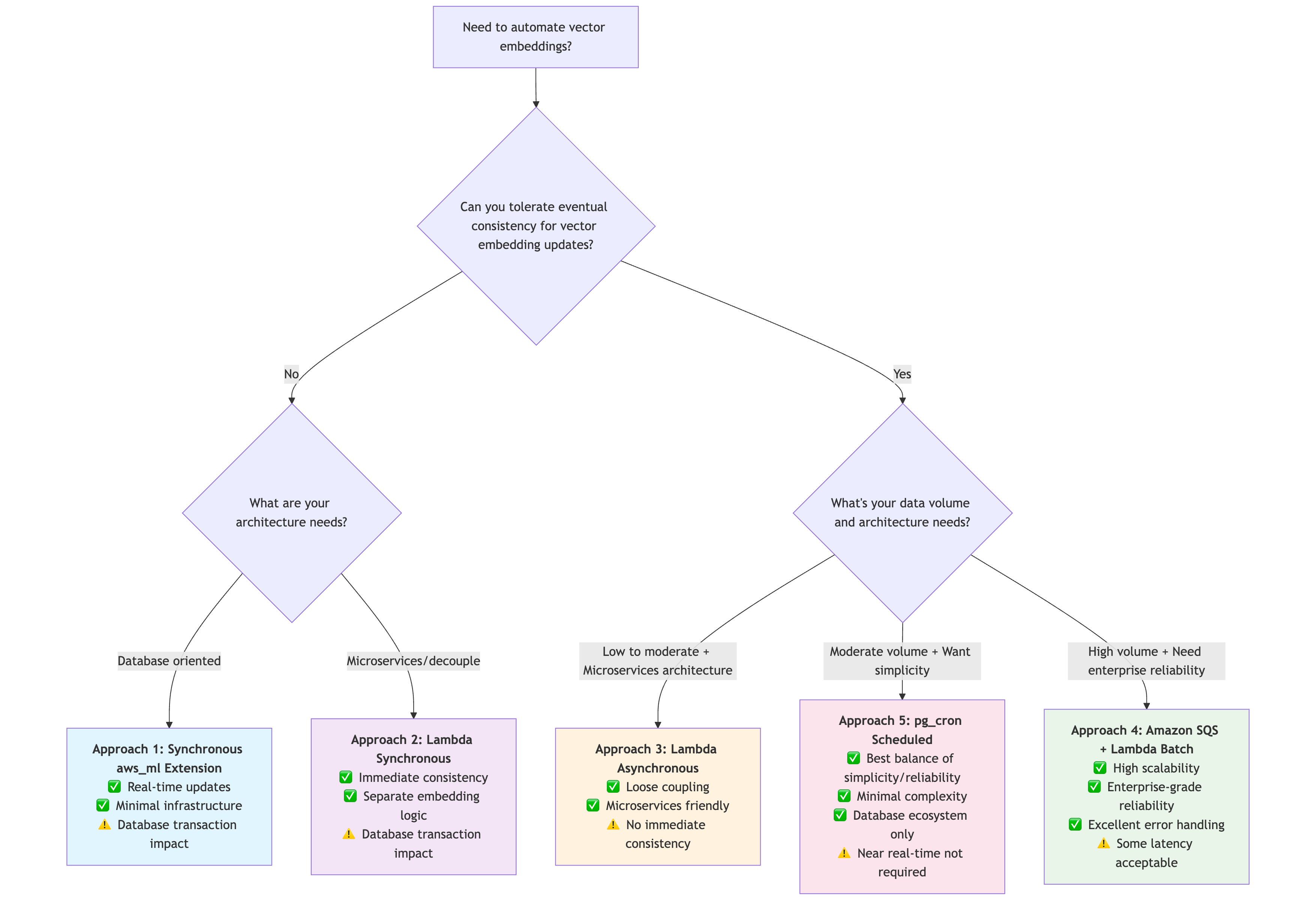
Remember that you can always start with a simpler approach, such as the approach 1 and 5, and evolve into a more sophisticated solution as your needs grow. The main differences lie in how they handle scaling, reliability, and operational complexity.
Note: Related to the performances, indices are crucial in this context. Depending on the type of indices chosen to index the vector embeddings, it may be necessary to perform periodic maintenance to keep these indices performing and relevant, under penalty of a progressive deterioration in performance or in the recall percentage for semantic searches.
For implementation details and code examples, see our GitHub repository and the additional resources listed in this post.
Clean up
To avoid unnecessary costs, clean up the AWS resources you deployed as part of implementing the approaches in this post:
- Delete the AWS CloudFormation stacks in the CloudFormation console.
- Delete any additional resources you created.
Conclusion
Automating embedding generation for vector search in Aurora PostgreSQL can provide significant benefits for applications leveraging AI capabilities. By keeping vector embeddings synchronized with your data, you can make sure that search results, recommendations, and other AI-powered features remain relevant and accurate.
Throughout this post, we’ve presented various approaches to embedding generation automation. The optimal solution for your application will depend on your specific requirements regarding consistency, latency, scalability, and operational complexity.
You can find the complete solution in the GitHub repository. We welcome your contributions and feedback through issues or pull requests.
If you have any questions about this post, please share them in the comments section below.