AWS Database Blog
How CRED uses Amazon RDS Blue/Green Deployments at scale
CRED is a fintech platform built for India’s most creditworthy individuals. The platform enables users to manage and pay credit card bills, utility bills, rent, and other payments through a single app. CRED manages over 120 production database clusters on Amazon Relational Database Service (Amazon RDS) and Amazon Aurora, with an average switchover time of 2 minutes and a 100 percent operation success rate. Each maintenance window previously meant roughly 3 hours of coordination, risk, and degraded availability. With stringent Service Level Agreements (SLAs) and a growing cluster count, this approach was unsustainable.
In this post, you will learn how CRED built an automated orchestration framework around Amazon RDS blue/green deployments. The framework performs engine upgrades, instance scaling, storage optimization, and Change Data Capture (CDC) pipeline migration across their entire fleet. This approach achieved zero data loss incidents and zero production incidents.
Solution overview
Database engine upgrades are a routine but high-stakes operation for teams running production workloads on Amazon RDS and Amazon Aurora. Major version upgrades, instance class changes, and storage optimization all require careful planning. This is especially true when the fleet is large and the workloads are critical.
Amazon RDS Blue/Green Deployments create a staging environment that copies the production environment. The blue environment is the current production database, and the green environment is the staging environment that stays in sync through replication. You can make changes to the green environment, such as upgrading the major or minor DB engine version or changing database parameters, without affecting production workloads. For a full list of supported modifications and limitations, see Limitations and considerations for Amazon RDS blue/green deployments. When ready, you switch over the environments, typically under a minute with no data loss and no need for application changes.
CRED’s infrastructure spans multiple AWS accounts serving diverse production workloads with varying performance and availability requirements. Traditional database maintenance, in-place modifications with extended maintenance windows, proved inadequate at this scale. The team needed a systematic, automated approach that could handle database engine version upgrades across MySQL variants, instance upscaling and downscaling, storage shrinkage following data archival operations, large table alterations, and active CDC pipelines using AWS Database Migration Service (AWS DMS) and Debezium (an open source change data capture platform).
To address this, CRED built a blue/green deployment architecture with the following components:
- Blue environment — the current production database serving live traffic.
- Green environment — the new target database with required changes.
- Validation framework — an automated testing suite that verifies green environment readiness.
- CDC pipeline management — AWS DMS and Debezium checkpoint tracking.
- Switchover orchestration — coordinated Domain Name System (DNS), application configuration, and database role transitions.
- Rollback mechanism — reverse replication for rapid recovery.
The automation framework
At the center of this architecture is an internal automation framework that uses the AWS API to run parallel operations, manage state transitions, and provide intelligent decision-making throughout the deployment lifecycle. The framework consists of 6 modules:
- Parallel AWS API orchestration — Executes blue/green switchover operations in parallel across multiple database instances using the AWS SDK, reducing total operation time from hours to minutes.
- Real-time metrics validation — Continuously monitors and validates critical metrics during switchover: replication lag, connection counts, query latency, error rates, and throughput.
- Checkpoint management — Captures and stores checkpoint information from blue/green switchover events, including database position markers, replication coordinates, and transaction IDs.
- CDC pipeline intelligence — Automatically restarts AWS DMS tasks and Debezium connectors using captured checkpoints, ensuring zero data loss during CDC pipeline migration.
- Automated rollback — Establishes reverse replication (native or DMS-based) from green to blue for one-click rollback to the previous state if issues arise post-switchover.
- Decision engine — Evaluates readiness criteria, validates preconditions, and determines go/no-go for each switchover phase based on configurable thresholds.
Pre-deployment preparation
Although many discussions of blue/green deployments focus on the switchover moment, CRED’s data across 200 migrations shows that 90 percent of success is determined in the preparation phase. Incidents traced back to preparation gaps, not execution failures. The team identified several preparation areas that proved critical.
Testing on staging environments
CRED mirrors production configurations in their staging environments. Configuration drift between staging and production caused 40 percent of switchover surprises in early operations. The team enforces a strict rule: If stage tests fail, the production migration is blocked. There are no exceptions.
Application team alignment
Communication proved as important as technical execution. Teams surprised by database changes caused 30 percent of post-switchover incidents. To address this, CRED provides green environment endpoints to application teams early, giving them time to test connection pools, timeouts, and failure modes. Each dependent team must provide explicit sign-off before the switchover proceeds.
Major version upgrade validation
Breaking changes are expected in major version upgrades. For example, MySQL 5.x to 8.x changed GROUP BY behavior, authentication mechanisms, and over 50 system variables. The team replays production queries against both blue and green environments, comparing results row by row. This approach catches 80 percent of issues. Although release notes cover major changes, thorough testing reveals edge cases and interactions.
Piloting green in the read path
Before switchover, CRED progressively shifts read traffic to the green environment in stages: 10 percent, then 50 percent, then 100 percent over several days. This validates the green environment under real production load and catches application-specific issues such as connection pool tuning and client library incompatibilities. By switchover time, the green environment has served production reads successfully, and confidence is earned through data rather than assumption.
Operational considerations
Two additional factors required attention. First, application-level parameter caching can cause issues during switchover if services read stale connection strings from AWS Systems Manager Parameter Store. The team enforces parameter refresh intervals under 5 minutes or coordinates application deployments during the switchover window. Second, AWS does not support cross-region replication for native blue/green deployments, so cross-region replicas must be handled separately. If your database uses cross-region read replicas, you must handle them separately outside the blue/green deployment process.
Maintenance mode and switchover orchestration
CRED’s microservices architecture, running on Amazon Elastic Container Service (Amazon ECS), is designed to handle database switchovers through an intelligent maintenance mode mechanism. Before initiating a switchover, services automatically enter maintenance mode, which triggers a controlled connection closure to the existing database instance. After connections are safely closed, the blue/green switchover is initiated. After the switchover completes and the new instance becomes active, services exit maintenance mode and establish fresh connections to the updated database endpoint. This approach verifies that in-flight transactions are handled properly and connection pools are refreshed without manual intervention.
Pre-switchover validation
The automation framework validates the following conditions before proceeding with any switchover:
- Replication lag below 1 second for a minimum of 2 minutes.
- Checksum validation on critical tables.
- All Amazon CloudWatch alarms in OK state.
- Application configuration management systems updated.
- DNS and load balancer configurations prepared.
- Reverse replication operational for rollback capability.
Switchover flow
The following diagram illustrates the 3 phases of a typical switchover. In the pre-switchover state, the blue database serves as the active primary handling 100 percent of write traffic and 50 percent of read traffic, while the green database operates as a standby replica handling the remaining 50 percent of read traffic.
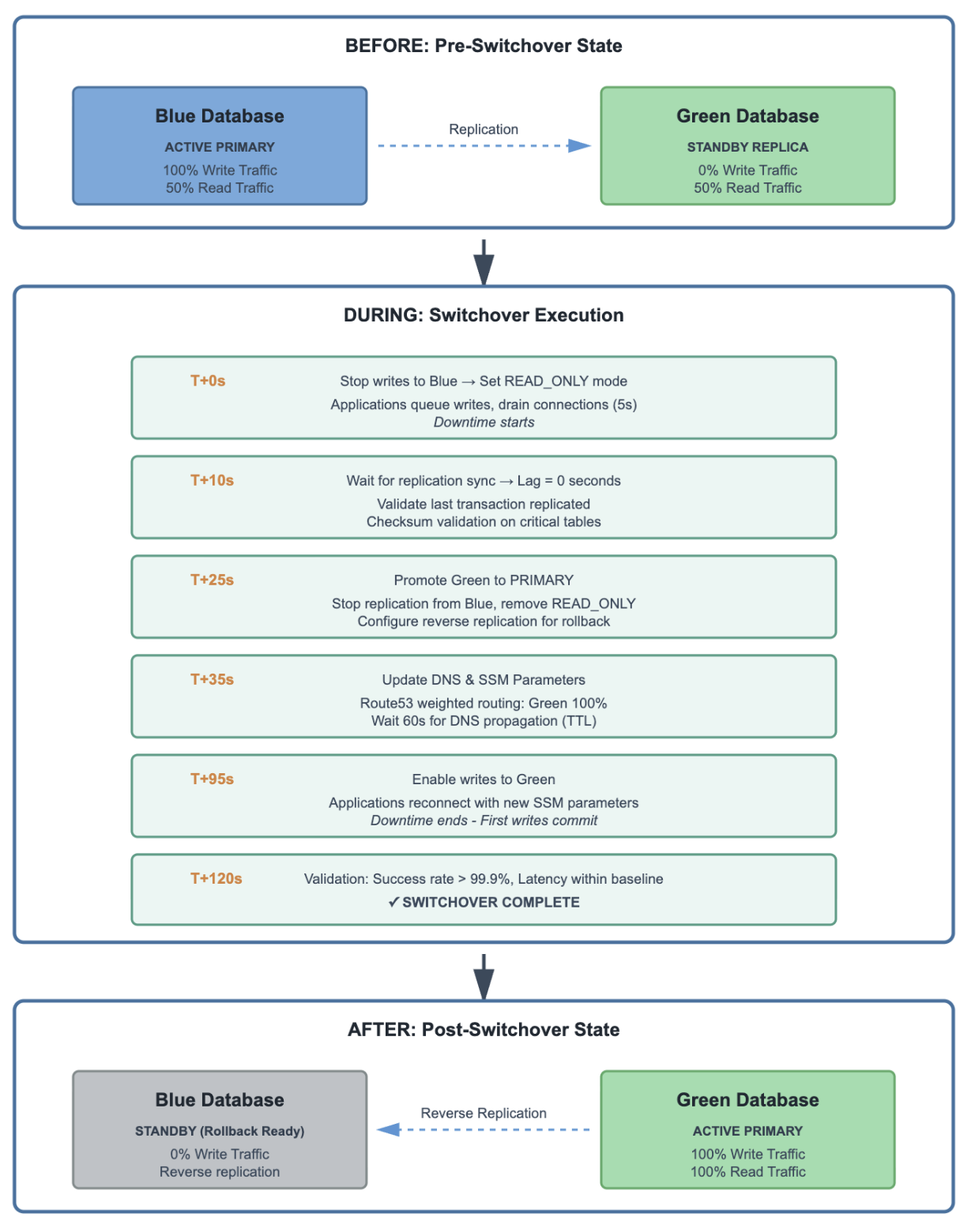
Diagram: Blue/Green Database Switchover Flow — provided by CRED
In the post-switchover state, the green database becomes the active primary handling 100 percent of write and read traffic. The former blue database transitions to standby with reverse replication enabled, ready for rollback if needed.
Post-switchover operations
After switchover, the automation continues with a 30-minute intensive monitoring window. Reverse replication from the new production environment back to the former blue environment is maintained for rollback capability. CDC pipeline health is monitored for AWS DMS task latency and Debezium connector status. If critical thresholds are violated during this window, the framework triggers an automatic rollback.
CDC pipeline migration
One of the most complex aspects of blue/green database deployments is maintaining Change Data Capture (CDC) pipelines. CRED runs active CDC pipelines using AWS DMS and Debezium across their database fleet. During a switchover, these pipelines must be stopped on the blue environment and restarted on the green environment without losing events or introducing duplicates.
CRED’s automation framework handles this through checkpoint-based migration. The process follows 4 steps:
- Stop the current CDC task on the blue environment.
- Update the AWS DMS task checkpoint using the position captured from the blue/green switchover event. The DMS source endpoint remains unchanged because blue/green switchover preserves database connectivity.
- Restart the DMS task pointing to the new primary database post blue/green switchover.
- Monitor pipeline health through Amazon CloudWatch metrics for AWS DMS task latency, events, and errors.
Across 120 databases with active CDC pipelines, this checkpoint-based approach achieved the following results:
- Zero data loss incidents.
- Average CDC pipeline downtime of 30 seconds.
- Zero duplicate event rate.
- 100 percent successful AWS DMS and Debezium migration rate.
Operational lessons and best practices
Over the course of building and operating this framework across 120 database clusters, the CRED team encountered several lessons that shaped their approach.
Test rollback, not just switchover
During a production upgrade, an application compatibility issue emerged 20 minutes after switchover. Because the team had tested the rollback procedure and maintained reverse replication, they reverted to the blue environment in 2.5 minutes with zero data loss. This incident reinforced the importance of treating rollback as a first-class operation rather than an afterthought.
Instrument everything
Early in the journey, subtle performance degradation in a green environment went unnoticed until after switchover. The team now collects and validates hundreds of metrics before, during, and after every switchover. Critical metrics include replication lag at sub-second resolution, connection pool utilization and wait times, query latency percentiles (p50, p90, p95, p99), disk I/O patterns and saturation, CPU and memory utilization, active connection counts and churn rate, and database-specific indicators such as deadlocks and buffer cache hit ratios.
Application connection handling
Applications with poor connection management caused connection storms during switchover, overwhelming the green environment. The team now requires all dependent applications to implement exponential backoff on connection failures, connection pool health checks, circuit breaker patterns for database failures, and graceful degradation when database connectivity issues arise.
Parameter group drift
Green environments inadvertently provisioned with different parameter groups caused performance regressions that were not caught during testing. To prevent this, the automation now validates parameter group consistency between blue and green environments, manages parameter groups as code through infrastructure as code tooling, generates parameter group diff reports before switchover, and alerts on any configuration drift.
Cost monitoring during migrations
Running parallel blue and green environments for extended periods during large migrations increased AWS costs. The team addressed this by integrating with AWS Cost Explorer for cost visibility, setting budget alerts specific to migration operations, automating blue environment decommissioning after validation, and scheduling migrations to minimize the duration of duplicate resources.
Results
Before adopting blue/green deployments, a database change at CRED meant hours of planning, cross-team coordination, and carefully chosen maintenance windows that often spilled into weekends. Every operation carried risk, and even small changes demanded disproportionate effort.
Since adopting this framework, the team has automated MySQL switchovers end-to-end. Across their fleet, CRED achieved the following operational metrics:
- 2 minutes average switchover time (95th percentile: 2.1 minutes).
- 100 percent operation success rate.
- Zero production incidents.
- Zero data loss incidents.
- 85 percent reduction in operational effort.
Services now coordinate their own maintenance mode during switchovers, eliminating the need for manual intervention, cross-team war rooms, and weekend maintenance staff availability. What once took days of planning and execution now completes in hours.
The risk profile has also changed. With automated validation, built-in rollback, and predictable execution, database operations have gone from being one of the most failure-prone areas to delivering zero production incidents since adoption. Database changes no longer block releases or require lengthy approval processes.
Conclusion
In this post, we described how CRED built an automated orchestration framework around Amazon RDS Blue/Green Deployments to manage database engine upgrades, instance scaling, storage optimization, and CDC pipeline migration across 120 production clusters. By investing heavily in pre-deployment preparation, building intelligent maintenance mode coordination into their Amazon ECS services, and automating CDC checkpoint management for AWS DMS and Debezium, the team achieved an average switchover time of 2 minutes, a 100 percent operation success rate, and zero data loss incidents.
The key takeaways from CRED’s experience are that thorough preparation determines the outcome more than the switchover itself, rollback must be treated as a first-class operation, and instrumentation across hundreds of metrics is necessary to catch subtle regressions before they reach production.
To get started with blue/green deployments for your own database fleet, see Overview of Amazon RDS Blue/Green Deployments.