AWS Database Blog
Optimize LLM response costs and latency with effective caching
Large language model (LLM) inference can quickly become expensive and slow, especially when serving the same or similar requests repeatedly. As more applications incorporate Artificial Intelligence (AI), organizations often face mounting costs from redundant computations and frustrated users waiting for responses. Smart caching strategies offer a powerful solution by storing and reusing previous results, dramatically reducing both response times and invocation overhead. The right caching approach can cut your model serving costs by up to 90% while delivering sub-millisecond response times for cached queries. In this post, we explore proven caching techniques that can transform your model deployment from a cost center into an efficient, responsive system.
Benefits of caching
Caching in generative AI applications involves storing and reusing previously computed embeddings, tokens, model outputs, or prompts to reduce latency and computational overhead during inference. Implementing caching helps deliver transformative benefits across four critical dimensions:
- Cost – Caching provides immediate relief from expensive LLM API calls. Although model pricing continues to decrease or remain constant, every cached response represents pure savings that compound at scale.
- Performance – Cached responses return in milliseconds rather than seconds, creating a dramatically better user experience where most repeated queries feel instantaneous.
- Scale – This performance boost directly enables greater scale because your infrastructure can handle significantly more concurrent requests when most responses bypass the computationally intensive model inference entirely.
- Consistency – Perhaps most importantly for production applications, caching provides consistency. Although LLMs can produce subtle variations even with deterministic settings, cached responses facilitate identical outputs for identical inputs, providing the reliability that enterprise applications demand.
In short, effective caching helps transform your applications by dramatically reducing costs through minimizing redundant API calls, lightning-fast response times that improve end customer experiences, massive scale improvements that maximize infrastructure efficiency, and consistency that builds customer trust and avoids hallucinations.
Caching strategies
You can implement two strategies for caching. The first, prompt caching, implements caching the dynamically created context or prompts invoked by your LLMs. The second, request-response caching, implements storing the request response pairs and reusing them in subsequent queries.
Prompt caching
Prompt caching is an optional feature that you can use with supported models on Amazon Bedrock to reduce inference response latency by upto 85% and input token costs by up to 90%. Many foundation model (FM) use cases will reuse certain portions of prompts (prefixes) across API calls. With prompt caching, supported models will let you cache these repeated prompt prefixes between requests. This cache lets the model skip recomputation of matching prefixes.
Many applications either require or benefit from long prompts, such as document Q&A, code assistants, agentic search, or long-form chat. Even with the most intelligent FMs, you often need to use extensive prompts with detailed instructions with many-shot examples to achieve the right results for your use case. However, long prompts, reused across API calls, can lead to increased average latency. With prompt caching, internal model state doesn’t need to be recomputed if the prompt prefix is already cached. This saves processing time, resulting in lower response latencies.
For a detailed overview of the prompt caching feature on Amazon Bedrock and to get guidance on how to effectively use it in your application, refer to Effectively use prompt caching on Amazon Bedrock.
Request-response caching
Request-response caching is a mechanism that stores the requests and their results so that when the same request is made again, the stored answer can be provided quickly without reprocessing the request. For example, when a user asks a question to a chat assistant, the text in the question can be used to search similar questions that have been answered before. When a similar question is retrieved, the answer to that question is also available to the application and can be reused without the need to perform additional lookups in knowledge bases or make requests to FMs.
Use prompt caching when you have long, static, or frequently repeated prompt prefixes that includes system prompts, persona definitions, few-shot examples, contexts or large retrieved documents (in RAG scenarios) that are consistently used across multiple requests or turns in a conversation. Use request-response caching when you have identical requests (prompt and other parameters) that consistently produce identical responses, such as retrieving pre-computed answers or static information. Request-response caching offloads the LLM entirely for specific, known queries and gives you more granular control over when cached data becomes stale and needs to be refreshed. The following section describes multiple techniques to implement request-response caching.
In-memory cache
Durable, in-memory databases can be used as persistent semantic caches, allowing the storage of vector embeddings of requests and their response retrieval in only milliseconds. Instead of searching for an exact match, this database allows different types of queries that use the vector space to retrieve similar items. You can use the vector search feature within Amazon MemoryDB, which provides an in-memory database with Multi-AZ durability, as a persistent semantic caching layer. For an in-depth guide, refer to Improve speed and reduce cost for generative AI workloads with a persistent semantic cache in Amazon MemoryDB.
LangChain open source framework provides an optional InMemoryCache that uses an ephemeral local store to cache responses in the compute memory for rapid accessibility. This exists for the duration of the program’s execution and can’t be shared across different processes, making it unsuitable for multi-server or distributed applications. This is especially useful during the app development phase when you’re requesting the same completion multiple times.
Disk-based cache
SQLite is a lightweight, file-based SQL database. It can be used to store prompt-response pairs persistently on the same compute disk with minimal setup. These have larger capacity than in-memory ephemeral local caches. SQLite works well for moderate volumes and single-user or small-scale scenarios. However, it might become slow if you have a high query rate or multiple concurrent accesses because it’s not an in-memory store and has some overhead for disk I/O and locking. For usage examples, refer to the SQLite documentations for details.
External DB cache
If you’re without access to a common filesystem and you’re building distributed applications running across multiple machines that make large volumes of concurrent writes (that is, many nodes, threads, or processes), consider storing the cached data in external dedicated database systems. The GPTCache module, part of LangChain, supports different caching backends, including Amazon ElastiCache for Redis OSS and Valkey, Amazon OpenSearch Service or Amazon DynamoDB. This means you can choose the most appropriate caching backend based on your specific requirements and infrastructure. It also supports different caching strategies, such as exact matching and semantic matching so you can balance speed and flexibility in your caching approach. Semantic caching stores responses based on the semantic meaning of queries using embeddings. It has the advantage of handling semantically similar queries directly from the cache that increases cache hit rates in natural language applications. However, there is additional computational overhead for computing embeddings and setting appropriate similarity thresholds.
The following image illustrates caching augmented generation using semantic search
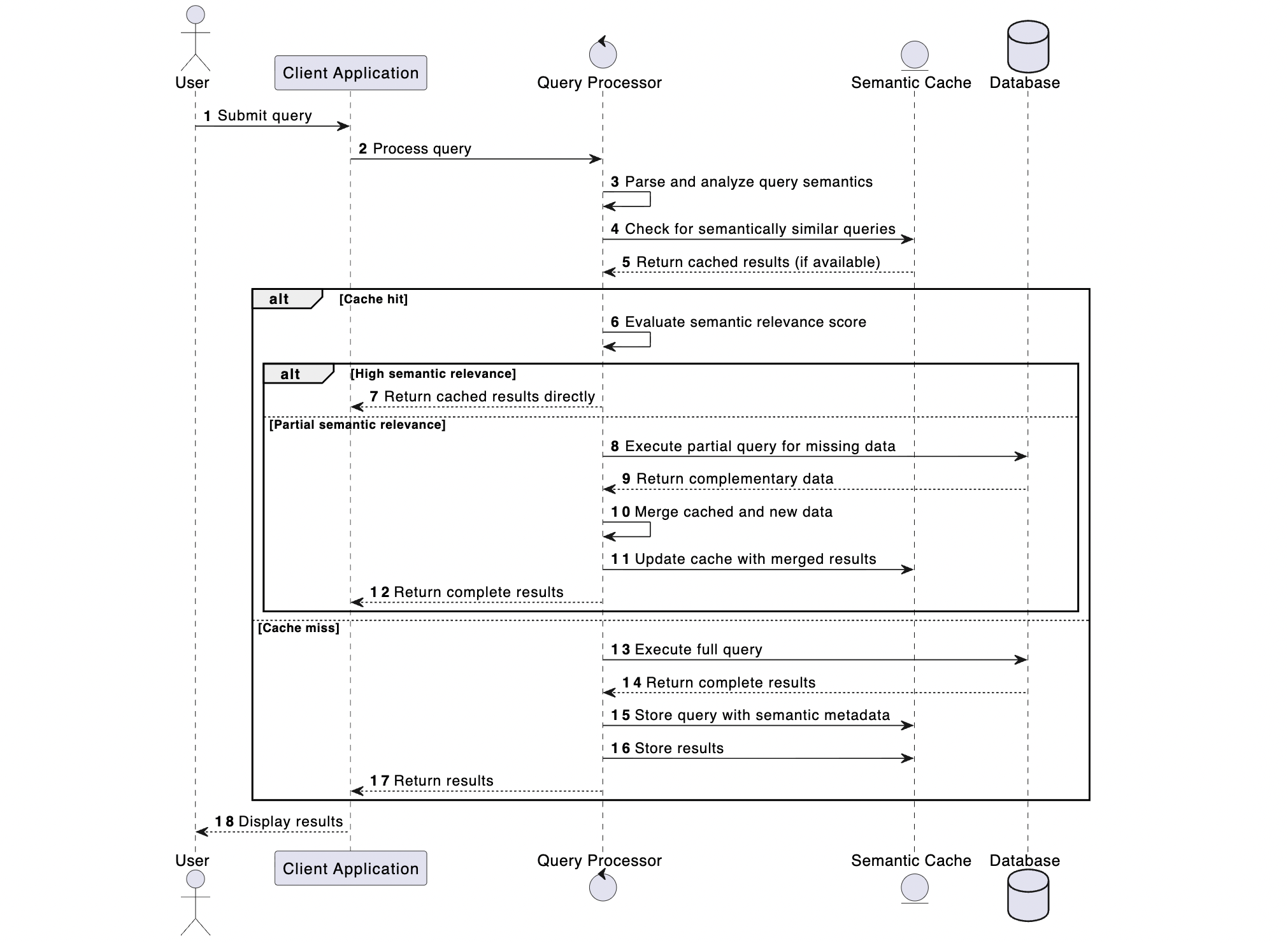
The choice of integrating a robust caching in your application strategy isn’t an either-or decision. You can, and often should, employ multiple caching approaches simultaneously to optimize performance and reduce costs. Consider implementing a multilayered caching strategy. For example, for a global customer service chat assistant, you can use an in-memory cache to handle identical questions asked within minutes or hours, a Valkey based distributed cache to store Region-specific frequently asked information, and an Amazon OpenSearch Service based semantic cache to handle variations of similar questions.
For a deep dive on various caching architectures and algorithms that can be employed for caching, read Bridging the Efficiency Gap: Mastering LLM Caching for Next-Generation AI. If you’re already using Amazon OpenSearch Serverless and want to quickly build a caching layer on top of it, refer to Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock.
Cache invalidation strategies
Although caching offers significant performance benefits, maintaining cache freshness and integrity requires careful consideration of two critical mechanisms:
- Cache invalidation – The systematic process of updating or removing cached entries when the underlying data changes. This provides data consistency between the cache and the source of truth.
- Expiration – A predetermined time to live (TTL) period for cached entries that automatically removes outdated data from the cache, helping maintain data freshness without manual intervention.
These mechanisms must be strategically implemented to balance performance optimization with data accuracy requirements. You can implement one of or a combination of the following strategies: TTL based invalidation, proactive validation, or proactive update on new data.
TTL-based invalidation
Implementing expiration times for cache entries is considered a best practice in cache management. This approach automatically removes entries after a specified period, necessitating a fresh computation upon subsequent requests. By applying TTL values to cache keys, you can effectively manage the freshness of your cached data.The selection of appropriate TTL durations should be based on the volatility of the underlying information. For instance, rapidly changing data might warrant TTLs of only a few minutes, whereas relatively static information, such as definitions and reference data (that is, data that is seldom updated), could be cached for extended periods, potentially days.
Amazon ElastiCache for Redis OSS and Valkey provides built-in support for TTL implementation, as detailed in the Valkey documentation. Amazon OpenSearch Serverless supports automated time-based data deletion from indices. Using Amazon DynamoDB TTL, you can define a per-item expiration timestamp. DynamoDB automatically deletes expired items asynchronously within a few days of their expiration time, without consuming write throughput. After a TTL expires for a given key, the next request for that data will trigger a fetch from the original data source and the LLM, thereby retrieving up-to-date information.
Another best practice when applying TTLs to your cache keys is to add some randomly generated time jitter to your TTLs. This reduces the possibility of LLM inferencing load occurring when your cached data expires. For example, consider the scenario of caching the most frequently asked questions. If your questions expire at the same time and your application is under heavy load, then your model has to fulfill the inferencing requests at the same time. Depending on the load, that could generate throttling, resulting in poor application performance. By adding slight jitter to your TTLs, a randomly generated time value (for example, TTL = your initial TTL value in seconds + jitter) could reduce the pressure on your backend inferencing layer and also reduce the CPU use on your cache engine as a result of deleting expired keys.
Proactive invalidation
In certain scenarios, proactive cache management becomes necessary, particularly when specific information has been updated or when a cache refresh is desired. This can occur, for example, when a chat assistant’s knowledge base undergoes changes or when an error in a cached response is rectified. To address such situations, it’s advisable to implement administrative functions or commands that facilitate the selective deletion of specific cache entries.
For SQLite-based caching, a DELETE query would be executed to remove the relevant entry. Similarly, Valkey has the UNLINK command, and Amazon DynamoDB has the DeleteItem API. You can remove an item in Amazon OpenSearch Service by using either the Delete Document API or Delete by Query API.
Proactive update on new data
When integrating new source data, such as updates to an existing knowledge base, you can implement a proactive cache update strategy. This advanced approach combines traditional caching mechanisms with sophisticated precomputation and batch processing techniques to maintain cache relevancy. Two primary methodologies can be employed:
- Preloading – Systematically populating cache entries with newly ingested information before it’s requested
- Batch updates – Executing scheduled cache refresh operations to synchronize cached content with updated source data
This proactive approach to cache management, although more complex and system-specific, offers significant advantages in maintaining cache freshness and reducing latency for frequently accessed data. The implementation strategy should be tailored to the specific requirements of the system architecture and data update patterns.
Best practices
Although caching offers numerous benefits, several critical factors require careful consideration during system design and implementation, including system complexity, guardrails, and context tenancy. Implementing and maintaining caching mechanisms introduces additional complexity to system architecture. This complexity manifests in several ways.
System intricacy is increased because the logic required for cache creation and management adds layers of abstractions to the overall system design. There will be potential points of failure because caching introduces new components that might malfunction, necessitating additional monitoring and troubleshooting protocols. Cache systems require consistent upkeep to facilitate optimal performance and data integrity. The impact on the whole system needs to be considered because ramifications of increased complexity on system stability and performance are often underappreciated in initial assessments.
Evaluate caching complexity
As a general guideline, the implementation of caching should be carefully evaluated based on its potential impact. A common heuristic suggests that if caching can’t be applied to at least 60% of system calls, the benefits might not outweigh the added complexity and maintenance overhead. In such cases, alternative optimization strategies like prompt optimization or streaming responses might be more appropriate.
Implement appropriate guardrails
Although robust input and output validation mechanisms (guardrails) are fundamental to deployment, they become particularly critical in systems implementing caching functionality. These safeguards require heightened attention due to the persistent nature of cached data. Establish comprehensive validation protocols to make sure that neither cached queries nor responses contain personally identifiable information (PII) or other protected data classes. Amazon Bedrock Guardrails provides configurable safeguards to help safely build generative AI applications at scale. With a consistent and standard approach used across a wide range of FMs, including FMs supported in Amazon Bedrock, fine-tuned models, and models hosted outside of Amazon Bedrock, Bedrock Guardrails delivers industry-leading safety protections. It uses Automated Reasoning to minimize AI hallucinations, identifying correct model responses with up to 99% accuracy—the first and only generative AI safeguard to do so. Industry-leading text and image content safeguards help customers block up to 88% of harmful multimodal content. For a reference implementation, read through Uphold ethical standards in fashion using multimodal toxicity detection with Amazon Bedrock Guardrails.
Maintain context-specific cache segregation
When implementing caching in systems that operate across multiple domains or contexts, it’s essential to maintain context-specific cache segregation. Similar or identical queries might require different responses based on their context. Hence, cache entries should be segregated based on their specific domain context to help prevent cross-domain contamination. Implement distinct cache namespaces, indices, or partitions for different domains. Refer the blog Maximize your Amazon Translate architecture using strategic caching layers that segregates cache entries in Amazon DynamoDB based on source and target languages while caching frequently accessed translations.
Conclusion
In this post, we talked about the benefits of caching in generative AI applications. We also elaborated on a few implementation strategies that can help you create and maintain an effective cache for your application. Implementation of effective caching strategies in generative AI applications represents a critical enabler for large-scale deployment, addressing key operational challenges, including LLM inference costs, response latencies, and output consistency. This approach facilitates the broader adoption of LLM technologies while optimizing operational efficiency and scalability.
For more learning on caching, refer to Caching Overview.