AWS DevOps & Developer Productivity Blog
From AI agent prototype to product: Lessons from building AWS DevOps Agent
At re:Invent 2025, Matt Garman announced AWS DevOps Agent, a frontier agent that resolves and proactively prevents incidents, continuously improving reliability and performance. As a member of the DevOps Agent team, we’ve focused heavily on making sure that the “incident response” capability of the DevOps Agent generates useful findings and observations. In particular, we’ve been working on making root cause analysis for native AWS applications accurate and performant. Under the hood, DevOps Agent has a multi-agent architecture where a lead agent acts as an incident commander: it understands the symptom, creates an investigation plan, and delegates individual tasks to specialized sub-agents when those tasks benefit from context compression. A sub-agent executes its task with a pristine context window and reports compressed results back to the lead agent. For example, when examining high-volume log records, a sub-agent filters through the noise to surface only relevant messages to the lead agent.
In this blog post, we want to focus on the mechanisms one needs to develop to build an agentic product that works. Building a prototype with large language models (LLMs) has a low barrier to entry – you can showcase something that works fairly quickly. However, graduating that prototype into a product that performs reliably across diverse customer environments is a different challenge entirely, and one that is frequently underestimated. This post shares what we learned building AWS DevOps Agent so you can apply these lessons to your own agent development.
In our experience, there are five mechanisms necessary to continuously improve agent quality and bridge the gap from prototype to production. First, you need evaluations (evals) to identify where your agent fails and where it can improve, while establishing a quality baseline for the types of scenarios your agent handles well. Second, you need a visualization tool to debug agent trajectories and understand where exactly the agent went wrong. Third, you need a fast feedback loop with the ability to rerun those failing scenarios locally to iterate. Fourth, you need to make intentional changes: establishing success criteria before modifying your system to avoid confirmation bias. Finally, you need to read production samples regularly to understand actual customer experience and discover new scenarios your evals don’t yet cover.
Evaluations
Evals are the machine learning equivalent of a test suite in traditional software engineering. Just like building any other software product, a collection of good test cases builds confidence in quality. Iterating on agent quality is similar to test-driven development (TDD): you have an eval scenario that the agent fails (the test is red), you make changes until the agent passes (the test is green). A passing eval means the agent arrived at an accurate, useful output through correct reasoning.
For AWS DevOps Agent, the size of an individual eval scenario is similar to an end-to-end test in the traditional software engineering testing pyramid. Looking through the lens of “Given-When-Then” style tests:
- Given – The test setup portion tends to be the most time-consuming to author. For the AWS DevOps Agent, an example eval scenario includes an application running on Amazon Elastic Kubernetes Service composed of several microservices fronted by Application Load Balancers, reading and writing from data stores such as Amazon Relational Database Service databases and Amazon Simple Storage Service buckets, with AWS Lambda functions doing data transformations. We inject a fault by deploying a code change that accidentally removes a key AWS Identity and Access Management (IAM) permission to write to S3 deep in the dependency chain.
- When – Once the fault is injected, an alarm fires, and this triggers the AWS DevOps Agent to start its investigation. The eval framework polls the records that the Agent generates, just like how the DevOps Agent web application renders them. This section isn’t fundamentally different from defining the action in an integration or end-to-end test.
- Then – This asserts and reports on multiple metrics. Fundamentally, there’s a single “PASS” (1) or “FAIL” (0) metric for quality. For the DevOps Agent’s incident response capability, a “PASS” means the right root cause surfaced to the customer – in our example, this means identifying the faulty deployment as the root cause and tracing the dependency chain to surface the impacted resources and observations that reveal the missing S3 write permission; otherwise “FAIL”. We define this as a rubric: not just “did the agent find the root cause?” but “did the agent arrive at the root cause through the correct reasoning with the right supporting evidence?”The ground truth (the “expected” or “wanted” in software testing parlance) is compared to the system response (the “actual”) via an LLM Judge – an LLM that receives both the ground truth and the agent’s actual output, then emits its reasoning and a verdict on whether they match. We use an LLM for comparison because the agent’s output is non-deterministic: the agent follows an overall output format but generates the actual text freely, so each run may use different words or sentence structures while conveying the same semantic meaning. We don’t want to strictly search for keywords in the final root cause analysis report but rather evaluate whether the essence of the rubric is met.
The evaluation report is structured with scenarios as rows and metrics as columns. Key metrics that we keep track of are capability (pass@k – whether the agent passed at least once in k attempts), reliability (pass^k – how many times the agent passed across k attempts, e.g., 0.33 means passed 1 out of 3 times for k=3), latency, and token usage.

Why are evals important?
There are several benefits to having evals:
- Red scenarios provide obvious investigation points for the agent development team to increase product quality.
- Over time, green scenarios act as regression tests, notifying us when changes to the system degrade the existing customer experience.
- Once pass rates are green, we can improve customer experience along additional metrics. For example, reducing end-to-end latency and/or optimizing cost (proxied by token usage) while maintaining the quality bar.
What makes evals challenging?
Fast feedback loops help developers know whether code works (is it correct, performant, secure) and whether ideas are good (do they improve key business metrics). This may seem obvious, but far too often, teams and organizations tolerate slow feedback loops […] — Nicole Forsgren and Abi Noda, Frictionless: 7 Steps to Remove Barriers, Unlock Value, and Outpace Your Competition in the AI Era
There are several challenges with evals. In decreasing order of difficulty:
- Realistic and diverse scenarios are hard to author. Coming up with realistic applications and fault scenarios is difficult. Authoring high fidelity microservice applications and faults is significant work that requires prior industry experience. What we’ve found effective: we author a few “environments” (based on real application architectures) but create many failure scenarios on top of them. The environment is the expensive portion of the evaluation setup, so we maximize reuse across multiple scenarios.
- Slow feedback loops. If the “Given” takes 20 minutes to deploy for an eval scenario and then the “When” takes another 10-20 minutes for complex investigations to complete, agent developers won’t thoroughly test their changes. Instead, they’ll be satisfied with a single passing eval, then release to production, potentially introducing regressions until the comprehensive eval report is generated. Additionally, slow feedback loops encourages batching multiple changes together rather than small incremental experiments, making it harder to understand which change actually moved the needle. We’ve found three mechanisms effective for speeding up feedback loops:
- Long-running environments for eval scenarios. The application and its healthy state are created once and kept running. Fault injection happens periodically (e.g., over weekends), and developers point their agent credentials at the faulty environment, completely skipping the “Given” portion of the test.
- Isolated testing of only the agent surface area that matters. In our multi-agent system, developers can trigger a specific sub-agent directly with a prompt from a past eval run rather than running the entire end-to-end flow. Additionally, we built a “fork” feature: developers can initialize any agent with the conversation history from a failing run up to a specific checkpoint message, then iterate only on the remaining trajectory. Both of these approaches significantly lowers the wait time of the “When” portion.
- Local development of the agentic system. If developers must merge changes and release to a cloud environment before testing, the loop is too slow. Running locally enables rapid iteration.
Visualize trajectories
When an agent fails an eval or a production run, where do you start investigating? The most productive method is error analysis. Visualize the agent’s complete trajectory, every user-assistant message exchange including sub-agent trajectories, and annotate each step as “PASS” or “FAIL” with notes on what went wrong. This process is tedious but effective.
For AWS DevOps Agent, agent trajectories map to OpenTelemetry traces and you can use tools like Jaeger to visualize them. Software development kits like Strands provide tracing integration with minimal setup.
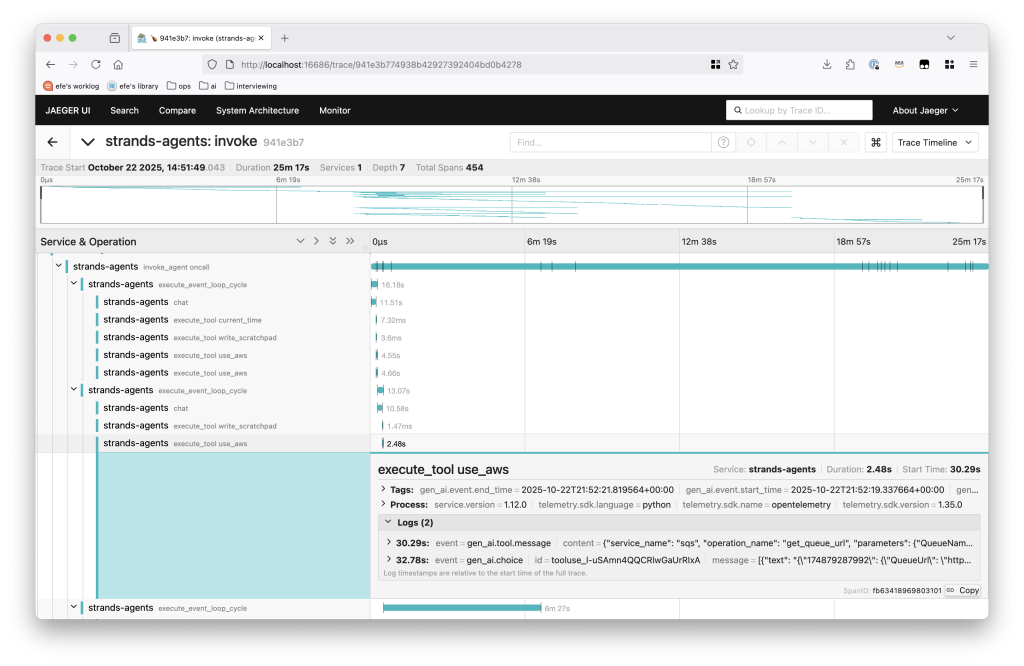
Figure 1 – A sample trace from AWS DevOps Agent.
Each span contains user-assistant message pairs. We annotate each span’s quality in a table such as the following:

This low-level analysis consistently surfaces multiple improvements, not just one. For a single failing eval, one will typically identify many concrete changes spanning accuracy, performance, and cost.
Intentional changes
I had learned from my dad the importance of intentionality — knowing what it is you’re trying to do, and making sure everything you do is in service of that goal. — Will Guidara, Unreasonable Hospitality: The Remarkable Power of Giving People More Than They Expect
You’ve identified failing scenarios and diagnosed the issues through trajectory analysis. Now it’s time to modify the system.
The biggest fallacy we’ve observed at this stage: confirmation bias leading to overfitting. Given the eval challenges mentioned earlier (slow feedback loops and the impracticality of comprehensive test suites) developers typically test only the few specific failing scenarios locally until they pass. One modifies the context (system prompt, tool specifications, tool implementations, etc.) until one or two scenarios pass, without considering broader impact. When changes don’t follow context engineering best practices, they likely have negative effects that we can’t capture through limited evals.
You need both diligence and judgment: establish success criteria through available evals and reusable past production scenarios, but also educate yourself on context engineering best practices to guide your changes. We’ve found Anthropic’s prompting best practices and engineering blog, Drew Breunig’s how long contexts fail, and lessons from building Manus particularly helpful resources.
Establish success criteria first
Before making any change, define what success looks like:
- Baseline. Fix specific git commit IDs for the current system. Think deliberately about which metrics would improve both the agent’s experience and the customer’s experience, then gather those metrics for the baseline.
- Test scenarios. Which evals will measure your change’s impact? How many times will you rerun these evals? Convince yourself this set represents broader customer patterns, not just the one failure you’re investigating.
- Comparison. Measure your changes against the baseline using the same metrics.
This intentional framing protects against confirmation bias (interpreting results favorably) and sunk cost fallacy (accepting changes simply because you invested time). If your modifications don’t move the metrics as expected, reject them.
For example, when optimizing a sub-agent within AWS DevOps Agent, we establish a baseline by fixing git commit IDs and running the same scenario seven times. This reveals both typical performance and variance.

Each metric measures a different dimension:
- Correct observations – How many relevant signals (log records, metric data, code snippets, etc.) that are directly related to the incident did the sub-agent surface?
- Irrelevant observations – How much noise did the sub-agent introduce to the lead agent? This counts signals that are unrelated to the incident and could distract the agent’s investigation.
- Latency – How long did the sub-agent take (measured in minutes and seconds)?
- Sub-agent tokens – How many tokens did the sub-agent to accomplish its task? This serves as a proxy for the cost of running the sub-agent.
- Lead-agent tokens – How much of the lead agent’s context window is the sub-agent’s input and output consuming? This gives us a tangible way to identify optimization opportunities for the sub-agent tool: can we compress the instructions to the sub-agent or the results it returns?
After establishing the baseline, we compare these metrics against the same measurements with our proposed changes. This makes it clear whether the change is an actual improvement.
Read production samples
We’ve been fortunate to have several Amazon teams adopt AWS DevOps Agent early. A DevOps agent team member on rotation regularly samples real production runs using our trajectory visualization tool (similar to the OpenTelemetry-based visualization discussed earlier, but customized to render DevOps Agent-specific artifacts like root cause analysis reports and observations), marking whether the agent’s output was accurate and identifying failure points. Production samples are irreplaceable; they reveal the actual customer experience. Additionally, reviewing samples continuously refines your intuition of what the agent is good and bad at. When production runs aren’t satisfactory, you have real-world scenarios to iterate against: modify your agent locally, then rerun it against the same production environment until the desired outcome is reached. Establishing rapport with a few critical early adopter teams willing to partner in this way is invaluable. They provide ground truth for rapid iteration and create opportunities to identify new eval scenarios. This tight feedback loop with production data works in conjunction with eval-driven development to form a comprehensive test suite.
Closing thoughts
Building an agent prototype that demonstrates the feasibility of solving a real business problem is an exciting first step. The harder work is graduating that prototype into a product that performs reliably across diverse customer environments and tasks. In this post, we’ve shared five mechanisms that form the foundation for systematically improving agent quality: evals with realistic and diverse scenarios, fast feedback loops, trajectory visualization, intentional changes, and production sampling.
If you’re building an agentic application, start building your eval suite today. Even starting with a handful critical scenarios will establish the quality baseline needed to measure and improve systematically. To see how AWS DevOps Agent applies these principles to incident response, check out our getting started guide.