AWS for Industries
How Acxiom reduced their model inference time from days to hours with Spark on Amazon EMR
Customer intelligence company Acxiom provides data-driven solutions that help marketers worldwide better understand their customers to create better customer experiences and drive business growth. To deliver these customer experiences, Acxiom builds and manages a large number of machine learning (ML) models on Amazon Web Services (AWS), using services like Amazon EMR—a solution for rapidly processing, analyzing, and applying ML to big data using open-source frameworks like Apache Spark.
By using Apache Spark on Amazon EMR—which lets users quickly and easily create managed Apache Spark clusters—companies can run petabyte-scale analysis at less than 50 percent of the cost of traditional on-premises solutions and over three times faster by using standard Apache Spark. In this blog, Varadarajan Srinivasan, Sr. Director, Data Science and ML Engineering at Acxiom, and Jim Parker, Sr. Manager Data Science and ML Engineering at Acxiom talk about how Acxiom used Apache Spark on Amazon EMR to compress the model inference duration on a large dataset for over 4,500 ML models from days to hours. We also discuss the design considerations and key learnings from this journey.
Introduction
Acxiom generates a large number of audience propensity scores to help its brand and marketing clients segment and choose audiences for marketing campaigns. We developed over 4500 machine learning models used to generate propensity scores for 620 million individual and household records (about 400 GB of data). We built these models over the years using custom modeling tools and packages using C++ and R. This process runs about three trillion inferences. Prior to migrating this workload to AWS, we ran this inference workload in our own datacenters on multiple infrastructure platforms including a large on-premises Hadoop cluster.
Acxiom’s infrastructure challenges and goals
In our datacenter configuration, Acxiom generated consumer propensity scores once a month, with on-premises Apache Hadoop MapReduce-based pipeline taking ~11 days to complete. Multiple teams in the company shared this infrastructure, so we set ourselves the following goals for improvement:
- To compress propensity ML model scoring time from 11 days to 1 day or less
- To deliver frequent and up-to-date propensity scores to its clients
- To reduce its dependency on aging on-premises shared infrastructure and innovate faster
We evaluated a few alternatives to modernize big data applications and determined that Amazon EMR was the right solution to meet our requirements.
Acxiom’s design approach
Here are some key application and architecture design considerations we used for our solution.
Input file
Our team receives a csv file (bz2 compression) from various upstream systems. This universe file contains 620 million records and 2000 columns.
Output files
Each C++ model writes out two inference outputs. These outputs are organized together as marts of 350-400 models each. They are named modelX_Rank, modelX_binary where “X” is a model number ranging from 1 to 350-400.
Because there are 620 million unique records, the model inference will produce a dataset that has 3 columns and 620 million unique identifiers x 2 outputs x 1 model, which equals about 1.24billion rows. So, each mart of 350 models produces an output dataset that has 434 billion rows (620million x 2 x 350).
Scaling dimensions
Each of our models are independent and uses a different set of input columns from the input file. So, we converted the input dataset format from csv to parquet to optimize data read concurrently at scale. Based on the input dataset size and some experimentation, we discovered that about 3,500 parquet files at about 240 MB each provided the optimal performance.
Units of work
The unit of work determines the granularity at which to track and detect failures. To optimize cluster utilization while not losing track of failures at the model level and minimize the Apache Spark overhead, we grouped 10 models in each Apache Spark job. Each job performed about 35,000 tasks and on about 240 MB of data each. With this partition size, each task was completed under 2 minutes. We ran this on a cluster with 6,000 – 7,000 cores and a microbatch of 10 models working on the full dataset completed the tasks in an average of 7-10 minutes.
To improve resiliency and repeatability of the process, instead of scoring all 350 – 400 models in a single Amazon EMR step, we spread the entire volume of scoring jobs per mart across three or four EMR steps. Each step has 10 microbatches of 10 models; thus, each step scores a total of 100 models. This helped us better manage the memory requirements for each step. Please review the Figure 1 below.
Infrastructure needs
As the work to process 4500 models could be parallelized, the more resources we could utilize, the faster we could get it done. So, we created the notion of “marts”, a grouping of 350-400 related models, and distributed these model groups across four Amazon EMR clusters running concurrently in four Availability Zones of the AWS Region. Because the four large clusters that were being provisioned were of several hundred nodes each, the team took advantage of the instance fleet configuration for Amazon EMR clusters, a capability that lets users select a wide variety of provisioning options for Amazon Elastic Compute Cloud (Amazon EC2) instances. By configuring instance fleets, we maximized the utilization of available compute resources in the AWS Region and was able to complete the entire job in our target time of about 15 hours.
Cost Optimization
Each of the scoring tasks was compute-intensive, so we decided to use the compute intensive (C) instance type for the EMR Core node fleet. For the Task node fleet, we decided to save costs by maximizing the use of Amazon EC2 Spot Instances—which let us take advantage of unused Amazon EC2 capacity on AWS at up to a 90 percent discount compared to Amazon EC2 On-Demand Pricing. also selected a variety of Amazon EC2 instance types to diversify this fleet, with the goal to minimize Spot Instance interruptions.
The final configuration was 20 percent On-demand instances for the core node fleet and 80 percent Spot Instances for the task node fleet. Because the majority of tasks took under 2 minutes to complete, any Spot Instance interruptions had limited impact on the overall duration of the job.
A design-for-failure approach
This was a mission critical workload, so handling and recovering from unexpected failures was an important design consideration. Several modes of failure had to be accounted for, including cluster failure, node failure within the cluster, task failure, application failure, and potentially failure of one of the models within the application.
We handled cluster failure and application failure using the orchestration layer outside Amazon EMR, with Apache Airflow and Amazon Relational Database Service (Amazon RDS). This orchestration layer monitors for these events, logs them, and re-submits the workload if applicable. Node failure and task failure within an Apache Spark cluster are fairly common and expected, and Apache Spark has reasonable mechanisms to handle the scenarios including using deny lists bad nodes and resubmitting failed tasks to good nodes. We simply tuned the number of retries that suited our usecase.
The Apache Spark application itself can fail for many reasons. If too many nodes fail, or if too many tasks fail after several retries, Apache Spark will return an error to the application. Also, there could be a bug in the actual model code that might cause an error. To handle all these situations, we wrapped all code in multiple try and except blocks, and we logged the errors to an Amazon RDS for PostgreSQL database. This meant that the larger job could continue even if few independent models failed and also allowed us to retry the failed model groups only in a second run if needed.
Acxiom’s solution design and architecture
The diagrams below demonstrate the solution design and the overall architecture. Figure 1 shows the Apache Spark application design to better manage the unit of work and to detect and track model level failures.

Figure 1- Acxiom’s Apache Spark application design to track and detect model-level failures
Figure 2 shows the overall architecture with job control layer and distributed model inference with EMR.
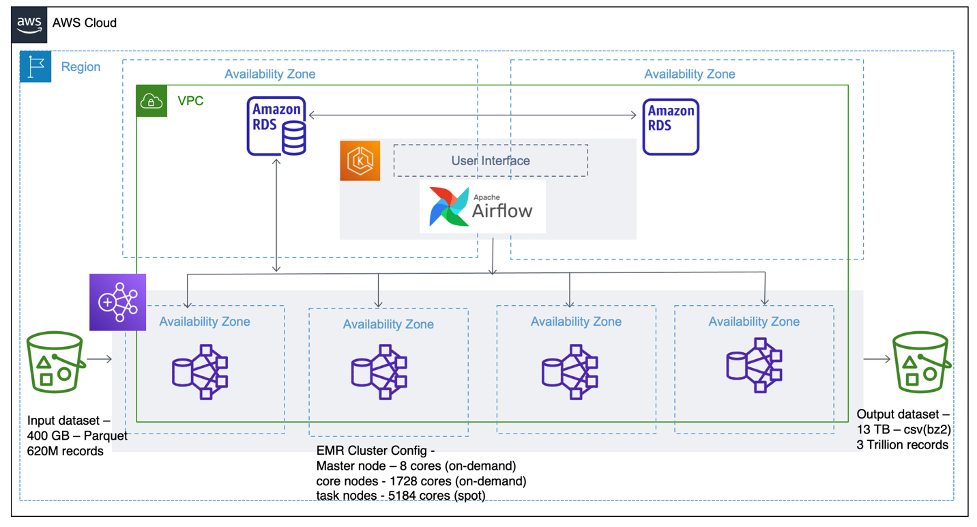
Figure 2- Acxiom’s Amazon EMR architecture for model inference at scale
In Figures 3 and 4, the Ganglia charts from a single Amazon EMR cluster from our recent production run demonstrates various aspects of our cluster configuration and utilization. Figure 3 and Figure 4 demonstrates the consistent utilization of all cluster nodes and the utilization of the cluster resources for each unit of work (10 models).


Figure 3: Consistent load distribution across the cluster nodes

Figure 4- Consistent aggregated load across the cluster for each unit of work
Summary of Acxiom’s important learnings
- Use modular units of work: Breaking the entire scoring exercise into smaller units of work (for example, a microbatch of 10 and steps of 100 models) made it easier for us to test and track failures. When you are developing a large-scale data-processing solution, always design for repeatable smaller components or units of a workload rather than using large monolithic steps.
- Scale the Amazon S3 request rate: Although Amazon Simple Storage Service (Amazon S3), an object storage service, is highly resilient and scalable, it accepts 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in an Amazon S3 bucket. With four large Amazon EMR clusters (about 30,000–35,000 cores total) reading the data from the same location and writing it to specific buckets, we worked with Amazon S3 performance experts to design the right S3 prefix partitioning scheme based on the read and write throughput needs of our implementation.
- Work backward from the desired service-level agreement: This perspective helped us design the right architecture with a job control layer (with Apache Airflow) for the concurrent distribution of models. Specifically, this provided us the flexibility to utilize the scale of AWS through Amazon EMR and Spot Instances to distribute the required compute capacity.
- Scale and tune your Amazon EMR cluster: Amazon EMR has several features and cluster settings to maximize the Amazon EC2 resource utilization and to optimize data processing, read and write performance. To avoid long iterations through trial and error across these many settings, we collaborated with AWS solutions architects to choose and fine tune and arrive at an initial set of cluster settings. This helped us quickly iterate through functional and scale testing, and fine-tune additional settings to arrive at the final cluster configuration.
- Perform and architecture review – Lastly, before we began building the scalable production-ready solution, we performed an AWS Well-Architected review – by collaborating with AWS Solutions Architects and other AWS service specialists. Architecture reviews are important for hyperscale data and ML solutions so that teams can identify potential issues prior to the start of the implementation.
Conclusion
By migrating model inference workloads to Apache Spark on Amazon EMR, we are able to drastically reduce the model inference duration from days to hours. For example, in the most recent production run, we inferenced all 4500-plus models on the large dataset in about 15 hours. This reduced our operational effort on a monthly basis from multiple weeks to half a day.
Additionally, this time reduction, not only freed up our data scientists and engineers for other modeling activities but also unlocked several incremental opportunities to increase data coverage (correlated to increased revenue). Previously, our teams hadn’t been able to pursue such opportunities due to long inference times of on-premises infrastructure. Finally, leveraging Spot Instances on Amazon EMR clusters significantly reduced per-model inference costs.
Acxiom will present additional details about this workload, including how it used Amazon SageMaker to build large-scale machine learning pipelines for audience scoring, live at re:Invent 2021 on November 30, 2021 in the advertising and marketing technology track. Register now to watch the session, Predictive audience scoring at scale with Amazon SageMaker, virtually.