AWS for Industries
Medical Legal Regulatory Review Orchestration with AI Agents on AWS
Healthcare and life sciences companies produce a constant flow of both promotional content (branded advertisements, sales aids, digital campaigns, email outreach) and non-promotional content (patient education brochures, disease awareness materials, clinical visual aids). Regardless of category, none of this content reaches its intended audience until it clears a medical, legal, and regulatory (MLR) review, where every piece is verified for scientific accuracy, regulatory compliance, and adherence to brand and promotional classification guidelines.
The stakes are significant as non-compliant content can result in regulatory warning letters, costly product withdrawals, and substantial financial penalties that have historically reached billions of dollars for major pharmaceutical companies. In September 2025 alone, the FDA issued over 100 cease-and-desist letters and thousands of warning letters to pharmaceutical companies for misleading promotional content, marking one of the agency’s most concentrated enforcement actions in decades.
Today, this process remains largely manual. Cross-functional review teams examine every document line by line, referencing dozens of guidelines and hundreds of scientific sources. Promotional materials demand fair balance and substantiation of efficacy claims, while non-promotional content must avoid language that could be interpreted as off-label promotion. As large organizations manage thousands of these reviews each year, a single asset can take on average 15 days to clear. As regulatory frameworks evolve and product launches span multiple global markets simultaneously, the MLR bottleneck only deepens, delaying time to market for critical drug communications at a moment when speed matters most.
Generative AI and intelligent automation now offer a path to fundamentally rethink this process, with studies suggesting accelerated review cycles with total review time reduction by up to 90% without compromising the rigor that regulatory compliance and patient safety demand.
In this post, we show how a multi-agent AI system built on Amazon Bedrock can accelerate the MLR process. A fleet of specialized AI agents running on Amazon Bedrock AgentCore collaborates to cross-check content against scientific literature, style guides, regulatory codes, and pre-approved claims. The agents work in parallel to identify potential issues, cite their sources, and suggest remediations, enabling reviewers to focus their expertise where it matters most. The solution uses the Strands Agents SDK, an open-source framework for building AI agents.
The MLR review challenge
Medical content review is a multi-dimensional problem. Every document must be evaluated against several distinct bodies of reference:
- Scientific references such as clinical study reports, journal articles, and press releases that substantiate the claims made in the content.
- Regulatory codes such as the IFPMA Code of Practice that govern what can and cannot be communicated in promotional and non-promotional materials.
- Branding and style guides that dictate tone, formatting, terminology, and visual standards.
- Product information including approved indications, contraindications, and prescribing information.
Each dimension requires specialized expertise. A medical reviewer assesses scientific accuracy, a legal reviewer evaluates regulatory compliance, and a brand reviewer ensures consistency with style standards. Coordinating these perspectives across multiple documents, products, and markets is what makes MLR review both slow and costly.
Architecture
We develop a multi-agentic medical content review solution utilizing the stack and capabilities of the open-source Deep Research for AgentCore sample. For a simplified, deployable implementation of this pattern, see the open-source Medical Content Review sample. This allows us to combine the core medical content review tasks with additional external sources and research capabilities. The architecture is presented on Figure 1.
The system takes two inputs: the content document (as a PDF) and the reference materials (scientific papers, guidelines, claims databases, etc). The solution produces a structured review report that lists every flagged issue with the exact quote and page reference, a description of the problem along with the suggested fix, and a confidence score.
The review process follows six steps, each handled by dedicated agents orchestrated through Strands Agents SDK and powered by Anthropic Claude models on Amazon Bedrock. Strands Agents SDK orchestrates the agents within a single runtime, using its native Amazon Bedrock model connector and parallel tool execution. The agents’ review logic written in Strands SDK runs on AgentCore Runtime allowing us to scale agentic capabilities with respect to demand. AgentCore observability helps to trace, debug and monitor the agent’s performance, while connecting to Amazon CloudWatch and AWS X-Ray. AgentCore Memory provides short-term conversation history for each document review session, enabling multi-turn reviews with session continuity.
The solution uses Amazon Cognito for authentication in three places:
- User-based login to the frontend web application on AWS Amplify
- Token-based authentication for the frontend to access AgentCore Runtime
- Token-based authentication when making API requests to Amazon API Gateway.
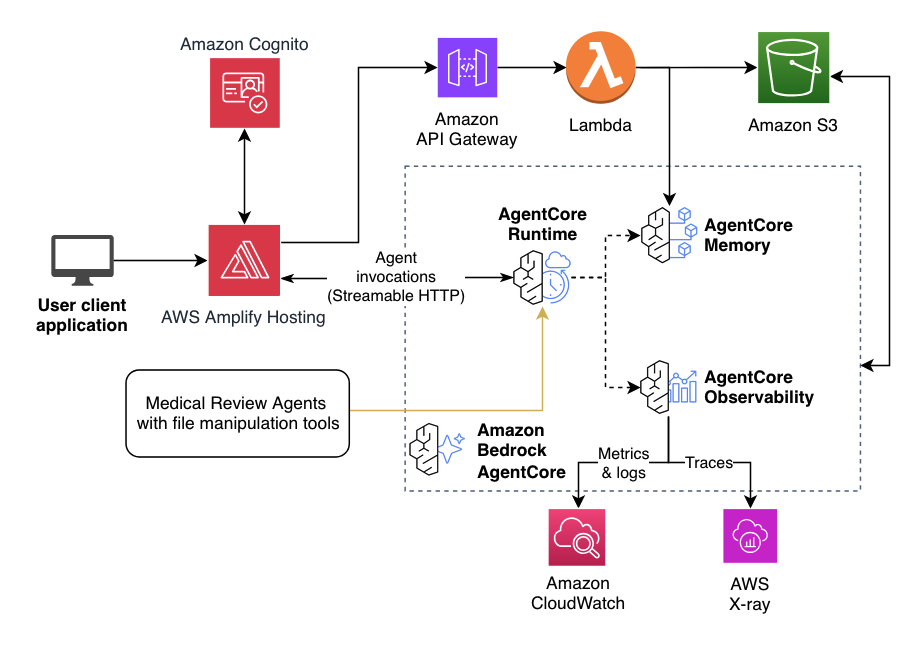
Figure 1. Agentic medical content review architecture
Interaction with files is handled through a pre-signed URL flow: the frontend requests a pre-signed Amazon S3 URL via Amazon API Gateway (authenticated with Amazon Cognito). The Amazon Lambda generates it, and the user’s browser uploads the file directly to the S3 staging bucket. The agent running on AgentCore Runtime can then read those uploaded files and write generated reports back to the same bucket, which the frontend fetches for display.
The entire infrastructure is deployed as a single AWS Cloud Development Kit (CDK) application.
Agentic review workflow
Figure 2 depicts the business logic of the review process, where each review agent acts as a specialized reviewer with its own area of expertise and relevant context. We decompose the review into focused tasks that run in parallel, mirroring how human review teams operate.
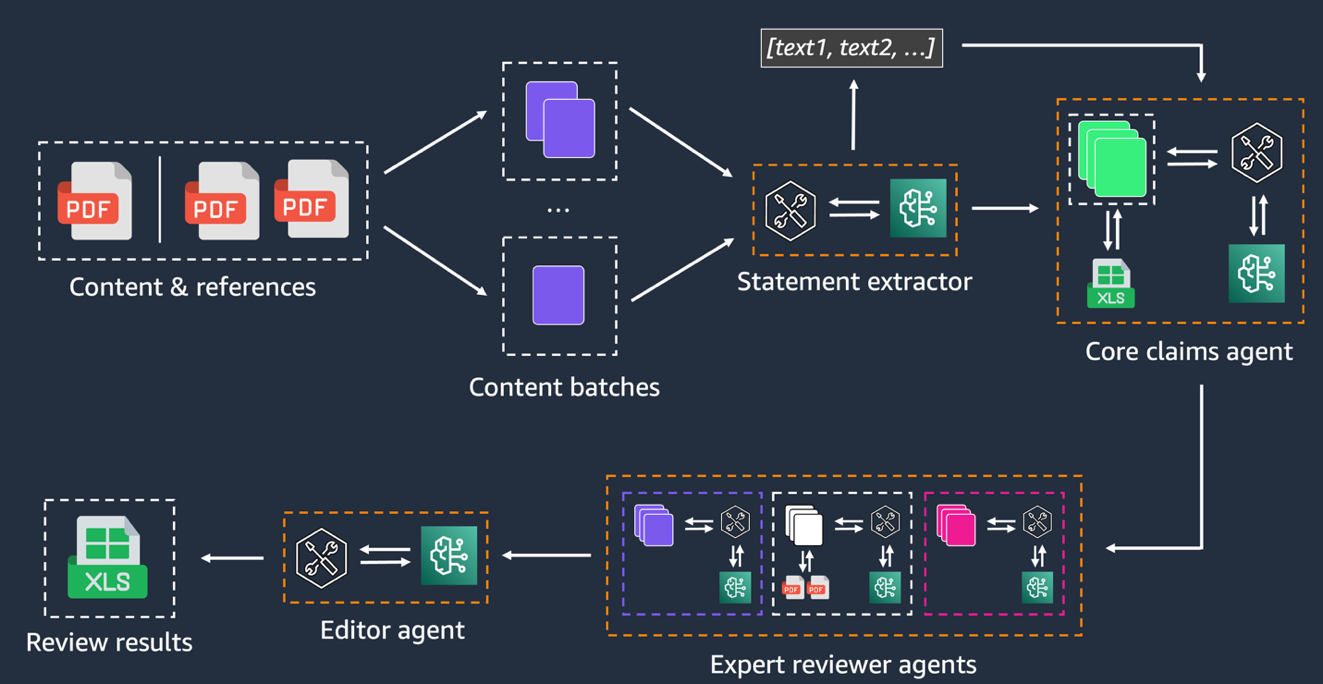
Figure 2. Agentic review workflow
Step 1: Document processing
The first step transforms all input documents into an LLM-readable format. Marketing content often comes as visually rich, multi-page PDFs with complex layouts, embedded images, and tables. We use multimodal LLM capabilities on Amazon Bedrock to extract both the textual content and a description of visual elements from each page. Reference materials such as scientific papers and guidelines are converted using the same multimodal LLM approach with a custom prompt template that structures content as markdown.
While Amazon Bedrock Data Automation provides a managed alternative for document extraction, it requires predefined blueprints, making it most effective for templated, structured use cases. For dynamic, unstructured scenarios like this one, direct LLM calls provide full control over the extraction prompt and model selection. This ensures that downstream agents can reason over the full content of every document.
Step 2: Content batching
Multi-page promotional documents typically contain distinct sections, each spanning one to three pages: a branded cover page, efficacy data with clinical trial results, safety information including adverse events and contraindications, and footnotes with prescribing details and references. Figure 3 shows a single page from a fictitious example of such a document. A multimodal LLM processes pages in sliding windows of up to 5 pages at a time and groups them into semantically coherent batches based on content continuity. For example, a cover page forms its own batch, while efficacy data spanning two pages stays together. Batching keeps each review call focused on a manageable amount of content while preserving the context needed for accurate assessment.

Figure 3. Fictitious example of promotional document for Healthcare providers
Step 3: Statement extraction
For each content batch, a statement extraction agent identifies every distinct claim or assertion. Rather than reviewing raw text, this step produces a structured list of statements, each with the original text as it appears in the document and a normalized full claim that captures the complete meaning. For example, a promotional page might display the headline “Change your life” for a specific medicine, while the product name and therapeutic indication appear in a different section of the same page. The extraction agent combines these elements into a single normalized claim such as “[Product X] for [condition Y] can change your life,” giving downstream reviewers the full context needed to assess the statement. Human experts remain a reliable choice for scoring and evaluation of statement extraction, but they’re not the only option.
The statement extraction component of the system can be evaluated independently to validate that extracted statements match the actual page content. We use an independent LLM-as-a-judge call to calculate precision and recall of the statement extractor given a list of extracted statements and find that latest vision-language models such as Anthropic Opus 4.7 show the best extraction quality. In production, we recommend defining precision and recall thresholds to ensure consistent quality.
Step 4: Pre-approved claims verification
Some organizations maintain a database of pre-approved statements that define the exact wording permitted for product efficacy, safety, and indication statements.
The claims verification agent cross-references the extracted statements against a database of pre-approved claims from previously published content. For each statement, the agent determines whether it matches one of the approved claims, flags any deviations from approved wording, and identifies statements that lack substantiation. This agent uses tool calls to search and retrieve items from the claims database using semantic search. This filters out pre-approved claims before the expert review step.
Step 5: Expert review
The core part of our multi-agent architecture is the expert review. A fleet of expert reviewer agents runs in parallel, each specialized in a different review dimension. The reviewer agents fall into three categories, distinguished by how they access reference materials:
- Reviewers with fixed context receive their reference materials as part of the system prompt. These cover stable, well-defined guidelines that rarely change. For example, code of practice and product information reviewer agents fit the corresponding documents within the model context, which allows them to perform the review in a single pass.
- Reviewers with dynamic context use retrieval-augmented generation (RAG) on Amazon Bedrock Knowledge Bases to pull relevant passages from large reference corpora at review time. For example, a scientific references reviewer verifies claims against clinical studies and publications, while a pre-approved claims reviewer checks exact wording compliance. These agents need tool access to search and retrieve from potentially large document collections that do not fit into a single LLM context.
- Reviewers grounded in model knowledge do not require external reference materials and instead rely on the LLM’s built-in capabilities. A spell-checking agent, for instance, uses the model’s inherent language knowledge to flag errors without needing additional documents.
Each expert reviewer agent receives the extracted statements from Step 3, applies its specialized lens, and produces a list of issues found. Because these agents run in parallel, the total review time is determined by the slowest agent rather than the sum of all agents, significantly reducing the overall latency. In our tests, the fleet of reviewer agents requires on average 2 minutes to process a batch of 1-3 pages. Note that processing of different batches can also be parallelized to further reduce the total document review time.
The multi-agent design is modular: new reviewer agents can be added as guidelines change, and existing agents can be updated independently. This helps the system scale horizontally as document volumes grow.
Step 6: Result compilation
Finally, an editor agent collects the outputs from all expert reviewers, deduplicates overlapping findings, assigns confidence scores on a 1–100 scale calibrated through ten few-shot examples that illustrate different severity levels, and compiles the final structured review report in a JSON format. The output is exported as a spreadsheet where each row represents a flagged issue with the page number, the exact quote, a description of the issue, the relevant reference, a suggested fix, the source guideline, and a confidence score.
To make the review workflow accessible to content creators and medical experts, we use a web-based user interface where users can upload the medical content PDF alongside reference materials and launch the AI review with a single click. Once the review completes, the interface displays the structured results, allowing users to browse flagged issues, inspect the cited references, and review suggested fixes directly in the browser. This process is illustrated in Figure 4.
Running multiple parallel agents across multi-page documents requires careful attention to resilience and cost. The system implements retry logic for each step with exponential backoff for transient failures such as throttled API calls or timeout errors, ensuring that a single failed agent invocation does not halt the entire review pipeline. If a batch fails mid-review, the corresponding reviewer agent is retried without duplicating results.
Cost management is also an important consideration. Running parallel reviewer agents per content batch across multi-page documents generates significant token consumption. To manage costs, the system uses prompt caching, including the extracted document content as the first message to avoid redundant processing, and leverages more cost-effective LLMs for mechanical checks (spelling, formatting) while reserving high-performing LLMs for tasks requiring deeper reasoning (scientific accuracy, regulatory compliance).
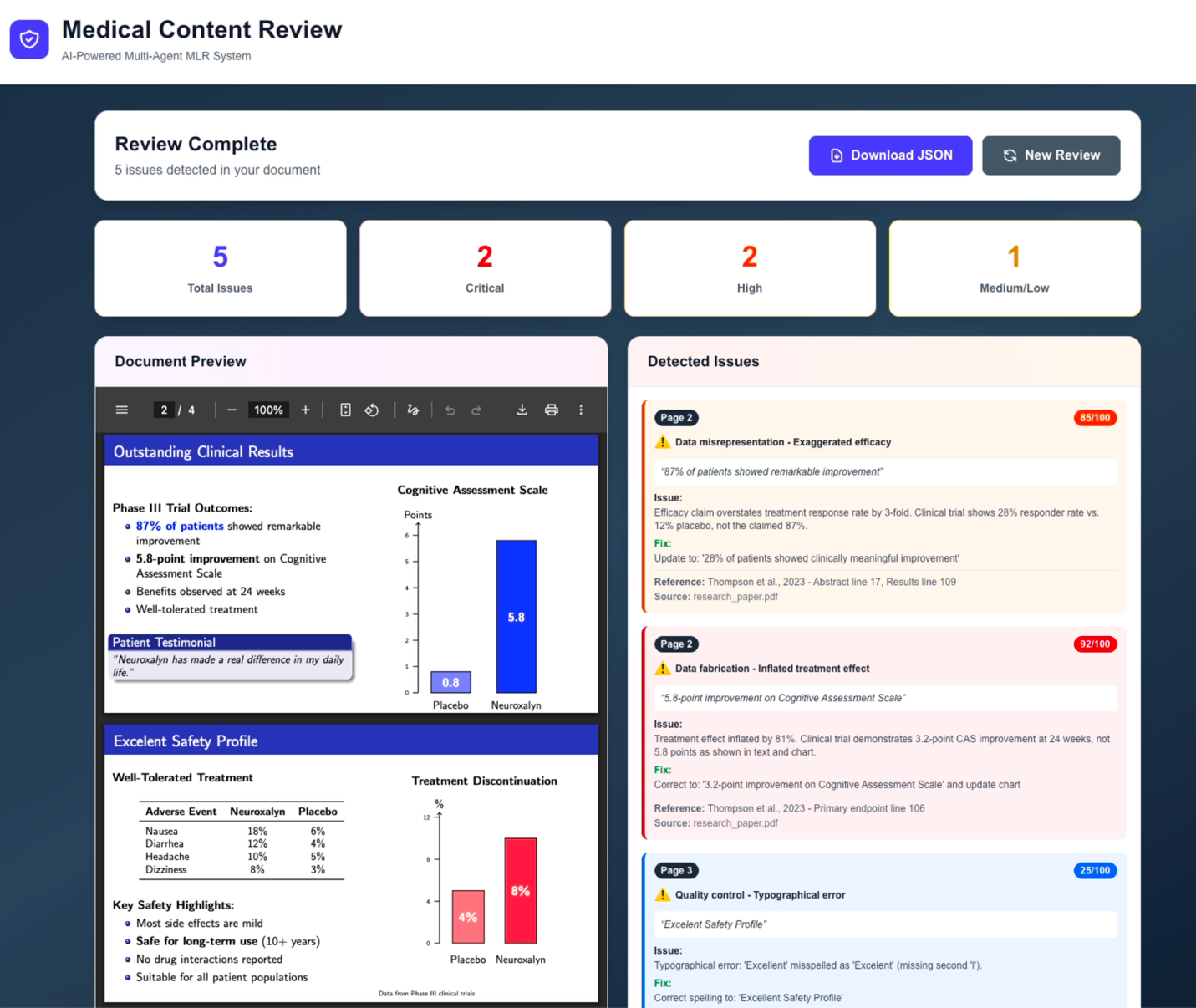
Figure 4. Example review output showing flagged issues with references and suggested fixes
Evaluations on real-world medical documents show that the multi-agent system achieves over 70% recall across different issue types in our proof-of-concept testing. In regulated content review, failing to detect a genuine issue carries significantly greater risk than surfacing a false positive, therefore the system was optimized to prioritize recall over precision. Actual performance will vary based on document complexity, reference material quality, and prompt design. This confirms that the solution accelerates the initial review pass and helps content creators catch issues they might overlook otherwise but also highlights the importance of human oversight, as the final decisions on the content must remain with qualified experts. As the system matures, incorporating human feedback into the pipeline will drive continuous improvement, enabling the solution to adapt to evolving document standards and deliver increasingly accurate results over time.
Conclusion
Multi-agent AI systems offer a promising approach to accelerating content review. By decomposing the MLR review process into specialized agents that mirror the roles of human reviewers, we can process content faster while maintaining the rigor that regulated medical communications demand. Our proof of concept demonstrates that this approach can achieve strong recall on known errors, process documents in minutes rather than hours, and produce structured, actionable review reports.
This work is an initial step. Future directions include expanding the set of reviewer agents to cover additional guidelines and markets, incorporating human feedback loops to continuously improve agent performance, and integrating the system into existing content management workflows for end-to-end automation.
Of course, a proof of concept is only valuable if it can scale. This is where AWS provides a distinct advantage. Amazon Bedrock gives access to a broad selection of foundation models with built-in enterprise security and compliance controls. When organizations are ready to move to production, Amazon Bedrock AgentCore provides a fully managed runtime to deploy, scale, and monitor these multi-agent systems without having to build and maintain the underlying infrastructure. Strands Agents SDK provides the orchestration layer with native Bedrock model connectors, parallel tool execution, and a unified programming model that works in local development and production environments. This solution uses the Strands Agents SDK for custom orchestration logic. For simpler agent patterns, AgentCore Harness provides a declarative alternative that eliminates custom orchestration code.
Together, this creates a complete path from experimentation to enterprise deployment, all within a platform that meets the data residency, auditability, and regulatory requirements life sciences organizations need.
If you are interested in building similar solutions, we encourage you to explore Amazon Bedrock AgentCore for foundation model access and the Strands Agents SDK for multi-agent orchestration. To discuss how generative AI can accelerate your organization’s content review processes, contact the AWS Generative AI Innovation Center or reach out to AWS Professional Services to accelerate your path to production.