Integration & Automation
Reduce costs with an ephemeral Amazon FSx for Lustre file system
This article introduces an ephemeral Amazon FSx for Lustre file system that’s active on an as-needed basis, allowing you to pay for services only when the system is used. With the file system running only when needed, you can still benefit from a powerful system with fast processing speeds without the high costs associated with a continuously running implementation.
An example use case is a machine learning (ML) training task that relies on data stored in an Amazon Simple Storage Service (Amazon S3) bucket. In this scenario, you could write code to download the data directly from the Amazon S3 bucket to the training task, but this approach isn’t feasible when data is constantly growing. The training task would spend more time downloading the data than performing the actual training. No organization is prepared to waste so many compute resources.
NOTE: An alternative to Amazon FSx for Lustre is to use Amazon Elastic File System (Amazon EFS) as a mounted storage and AWS DataSync to sync data between Amazon EFS and Amazon S3. Amazon FSx, however, is better suited for processing large data sets (such as in the ML training scenario) and reducing data synchronization issues.
| About this blog post | |
| Time to read | ~7 min. |
| Time to complete | ~30 min. |
| Cost to complete | $0 |
| Learning level | Advanced (300) |
| AWS services | Amazon CloudWatch
Amazon FSx Amazon Simple Notification Service (Amazon SNS) AWS CloudFormation AWS Lambda AWS Serverless Application Model (AWS SAM) AWS Step Functions |
Overview
Figure 1 shows the workflow for creating the ephemeral FSx for Lustre file system.
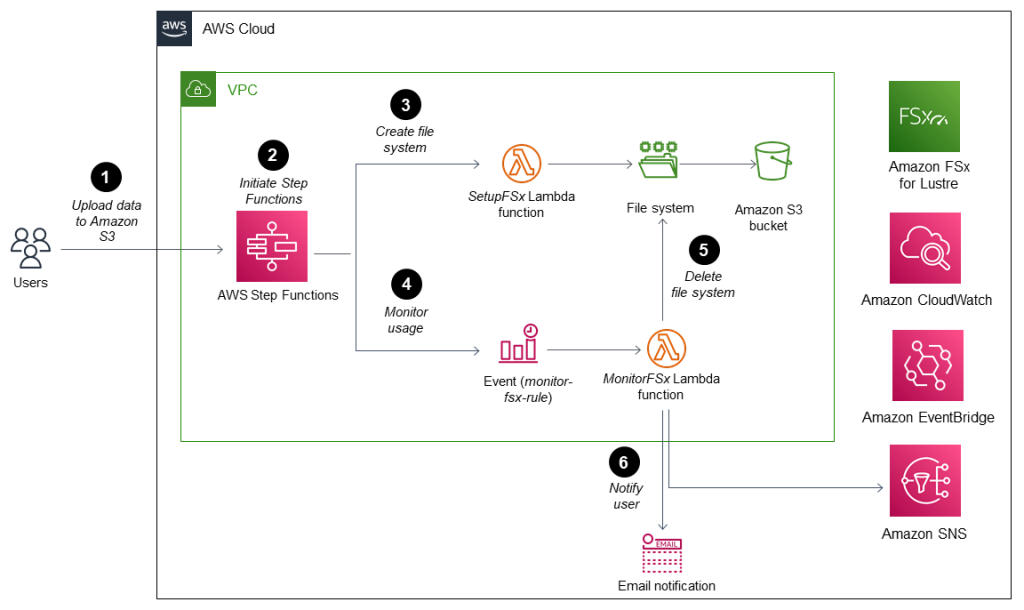
Figure 1: Automation workflow
- A user uploads data to the Amazon S3 bucket used to create the FSx for Lustre file system.
- Using the AWS Management Console, a user initiates AWS Step Functions.
- The SetupFSx Lambda function launches and creates the file system, and AWS Step Functions accesses data from the Amazon S3 bucket (no copying of data is required).
- A MonitorFSx Lambda function accesses Amazon CloudWatch metrics to monitor the I/O operations per second (IOPS) of the FSx for Lustre file system. An I/O operation of less than 0.4 for a minimum of one hour is interpreted as no activity. As long as the file system is active, an Amazon EventBridge event rule (monitor-fsx-rule) runs the MonitorFSx Lambda function every 10 minutes to monitor usage.
- When the MonitorFSx Lambda function logs no activity from the CloudWatch metrics for at least one hour, AWS Step Functions deletes the FSx for Lustre file system.
- The MonitorFSx Lambda function disables the event rule and sends a notification to Amazon SNS, which initiates an automated email to users who are subscribed to the SNS topic.
Solution overview
In the sections that follow, you perform the following steps:
- Create an Amazon S3 bucket with default encryption enabled, and copy sample data into it. The Amazon S3 bucket provides data to the FSx for Lustre file system via AWS Step Functions. If you have an existing Amazon S3 bucket configured with encryption, you can skip this step.
- Clone the GitHub repository. The repository contains all the code required to deploy the solution using AWS SAM.
- Deploy the infrastructure and resources using AWS SAM and AWS CloudFormation.
- Invoke AWS Step Functions with JSON code that specifies the Amazon S3 bucket name and phase detail.
- Verify the solution.
Prerequisites
- Python 3.9 installed and configured on your local machine.
- AWS SAM installed and configured on your local machine.
- For running AWS SAM, either a Python virtual environment or local Amazon Workspace.
- If you don’t have administrator access to the AWS account used to test the solution, refer to Creating your first IAM admin user and user group.
- For deploying the solution, either an Amazon Elastic Compute Cloud (Amazon EC2) instance or your own workstation.
- (Optional) AWS managed keys for encrypting the solution. If you prefer to use your own managed keys, ensure that you set the appropriate permissions.
- A working knowledge of AWS CloudFormation.
Walkthrough
Step 1: Create a new Amazon S3 bucket
Using AWS Command Line Interface (AWS CLI), run the following command to create a new Amazon S3 bucket. For all commands, replace <my-bucket> with the name of your bucket.
aws s3api create-bucket –bucket --region us-east-1 --acl private
Run the following command to enable encryption for your Amazon S3 bucket.
aws s3api put-bucket-encryption –bucket<my-bucket> --server-side-encryption-configurations
‘{“Rule”:[{“ApplyServerSideEncryptionByDefault”:{“SSEAlgorithm”:”AES256”}}]}’
Run the following command to copy the sample data to your Amazon S3 bucket. Later in this walkthrough, this data is used by Amazon FSx to validate the solution.
aws s3 cp sample-data/ s3://<my-bucket> --recursive
NOTE: If your Amazon S3 bucket contains sensitive objects, refer to Enabling Amazon S3 server access logging.
Step 2: Clone the source code repository
Run the following commands to clone the GitHub repository and then navigate to the directory on your local machine.
git clone https://github.com/aws-samples/amazon-fsx-for-lustre-ephemeral.git
cd amazon-fsx-for-lustre-ephemeral
Step 3: Deploy the infrastructure
Using AWS SAM, run the following commands to build and deploy the application:
sam build
sam deploy –guided
Provide the following parameter values:
-
- Stack name: Name of the AWS CloudFormation stack (for example, ephemeral-fsx-for-lustre-demo).
- AWS Region: AWS Region where the stack is deployed.
- Subnets parameter: AWS subnets in which the file system is created.
- Security groups parameter: Security groups for FSx for Lustre file system. Ensure that you allow the necessary inbound rules. For more information, refer to File System Access Control with Amazon Virtual Private Cloud (Amazon VPC).
- Parameter notification email: Email address for sending notifications when the FSx for Lustre file system is deleted.
The following sample output is expected after running the sam deploy –guided command using default settings:
=========================================
Stack Name [sam-app]:
AWS Region [us-east-1]:
Parameter Subnets [subnet-9320bXXX]:
Parameter SecurityGroups [sg-061c0303e71aXXXXX]:
Parameter NotificationEmail [emailaddress]:
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [y/N]:
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]:
#Preserves the state of previously provisioned resources when an operation fails
Disable rollback [y/N]:
Save arguments to configuration file [Y/n]:
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]:
NOTE: You can use either your default Amazon VPC or a custom VPC and subnet.
Step 4: Invoke AWS Step Functions
Run the following sample JSON code to initiate AWS Step Functions. Replace the placeholder variables with your own values.
To follow the example ML use case described in the overview, our solution uses team and phase parameters. Phases are used to share Amazon FSx between different ML lifecycle phases such as train, predict, etc. Your parameters and values may be different, depending on your use case.
{
"team": "<my-team>",
"bucket": "<my-bucket>",
"phase":"<phase>"
}
Replace the following parameters with custom values. These parameters are used to calculate the name of the FSx for Lustre file system, so they must be unique:
<my-team>: Shares Amazon FSx across multiple use cases within the same team. For more information, refer to Figure 1.<my-bucket>: Can be either an existing Amazon S3 bucket or the one created in step 1. For validation purposes, this bucket must have data that is available to Amazon FSx.<phase>: Part of the machine learning process in which you either share the file systems between two models in training or predict the phase within the same team.
Figure 2 shows a successful workflow of AWS Step Functions while creating the Amazon FSx for Lustre file system.
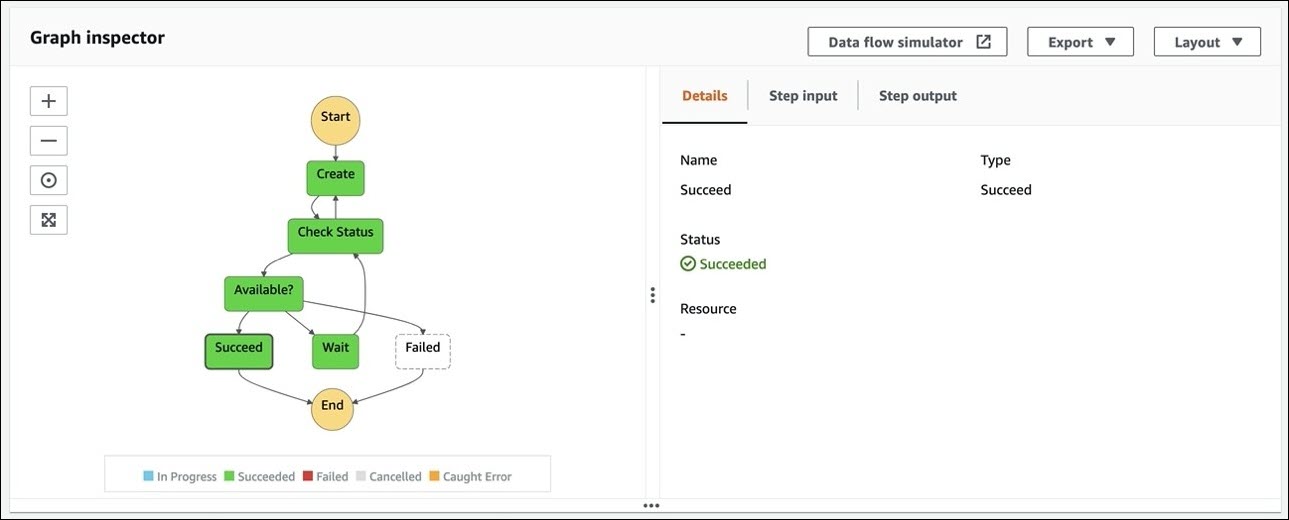
Figure 2: AWS Step Functions workflow
When you receive an email from no-reply@sns.amazonaws.com, accept the subscription request so you can start receiving emails from Amazon SNS.
Step 5: Verify the solution
Log in to the Amazon CloudWatch console, and view the logs.
Figure 3 shows the Amazon EventBridge rule that the solution creates for monitoring Amazon FSx usage. The event schedule is set to run every 10 minutes.
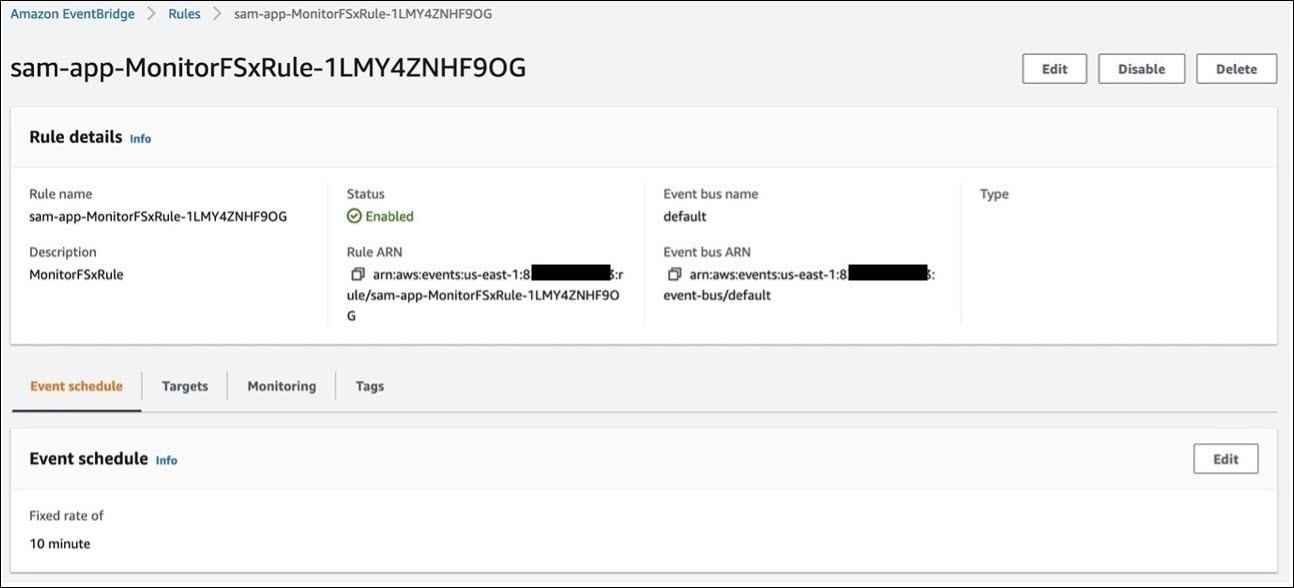
Figure 3: EventBridge rule for monitoring data usage
Figure 4 confirms that the target of the EventBridge rule target is the MonitorFSx Lambda function.
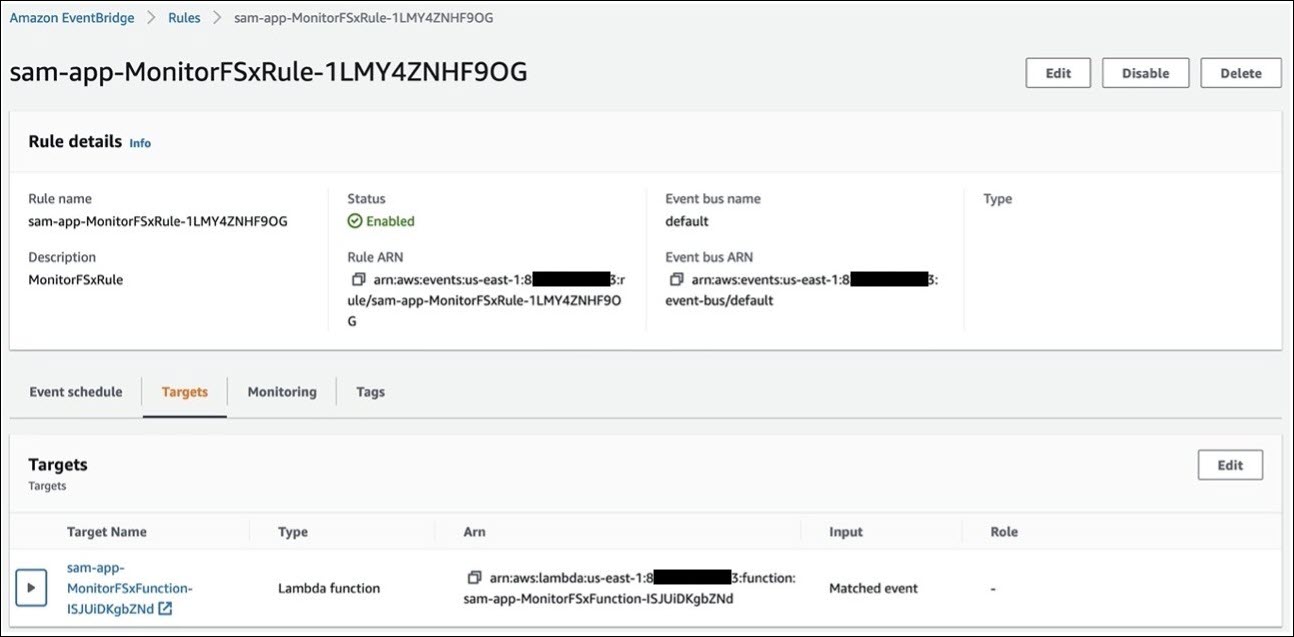
Figure 4: Lambda function target
To access CloudWatch logs, complete the following steps:
- Open the AWS Lambda console.
- Choose the SetupFSx Lambda function for this solution.
- Navigate to the Monitor tab.
- Choose View logs in CloudWatch, as shown in Figure 5.

Figure 5: View logs
- Choose the latest log stream, as shown in Figure 6.

Figure 6: Log streams
The log file shows details about the Lambda function process, including the steps that create the FSx for Lustre file system and a list of errors (if any are generated).
Cleanup
To avoid charges, run the following command to delete this solution’s resources:
sam delete
By design, the Amazon FSx for Lustre file system is deleted automatically if it’s not used for more than 60 minutes, and you are notified via email if you subscribe to the Amazon SNS topic.
Conclusion
In this article, we showed you how to create an ephemeral FSx for Lustre file system that’s active on an as-needed basis. Designed for organizations that need the file system only for short periods of time, our solution helps mitigate cost issues associated with running the service continuously.
For more information about how FSx for Lustre can be used in an ML use case, refer to Speed up training on Amazon SageMaker using Amazon FSx for Lustre and Amazon EFS file systems. For more information about FSx for Lustre use cases, refer to FSx for Lustre: Use Cases, Architecture, and Deployment Options.
For questions or feedback about this article, submit a comment below.
About the authors
 Bhushan Chirmade
Bhushan Chirmade
Bhushan Chirmade is a Sr. DevOps architect with AWS Professional Services based out of Dallas, Texas. He has been helping customers follow DevOps best practices for over decade. He is also an MLOps specialist helping AWS customers build end-to-end ML training, deployment and inference pipelines. Outside of work, Bhushan’s passion is playing cricket and traveling with family.
 Balaji Raju
Balaji Raju
Balaji Raju is a DevOps architect with AWS Professional Services. He helps AWS customers design and automate their CI/CD pipelines and supports their adoption of DevOps culture and processes. He researches AI/ML technologies and applies that knowledge to build better solutions for customers. Outside of work, he is passionate about fitness, cooking, and adventurous sport.