Artificial Intelligence
Amazon Comprehend now supports multi-label custom classification
Amazon Comprehend is a fully managed natural language processing (NLP) service that enables text analytics to extract insights from the content of documents. Amazon Comprehend supports custom classification and enables you to build custom classifiers that are specific to your requirements, without the need for any ML expertise. Previously, custom classification supported multi-class classification, which is used to assign a single label to your documents from a list of mutually exclusive labels. Starting January 6, custom classification also supports multi-label classification. With multi-label classification you can train models and classify your documents with more than one label.
For example, you can use multi-label classification to categorize customer contact transcripts with one or more labels to identify departments within your company like Payments, Renewals or Tech Support. These labels can then be mapped to relevant content in your support library or directed towards the appropriate contacts within your company.
In this post, let’s take a look at how to predict the subjects of an academic paper based on the abstract (data source: Yang et al. 2018. Sequence Generation Model for Multi-Label Classification). Custom classification is a two-step process. First you train a custom classifier to recognize the labels that are of interest to you. In the image below we’ve created a CSV file with abstracts and the applicable labels on each row:

You can download a subsample of the dataset above in Comprehend supported input format at comprehend_multilabel.zip.
Next we train the classifier in the Amazon Comprehend console. We choose multi-label mode, point to the S3 location where the training data is stored and manage other settings. See detailed instructions in the developer guide:

In the second step of custom classification, after Amazon Comprehend trains the classifier, you send unlabeled documents to be classified using the console or StartDocumentClassificationJob API. For our example, we will run an inference with a file that has one document per line:

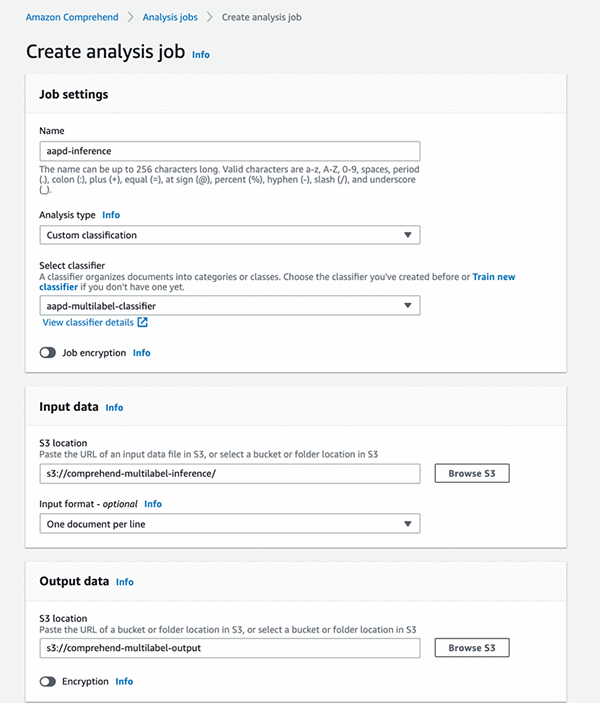
Depending on whether you trained a multi-class or multi-label custom classifier, the classification API examines each document and returns either the specific label that best represents the content (multi-class) or the set of labels that best represent it (multi-label). For our analysis job, we get an output as shown below:
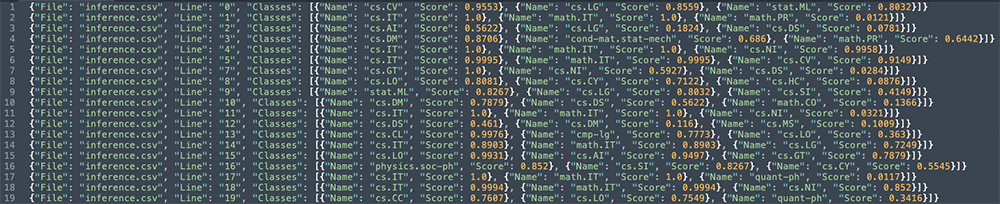
Here’s a detailed look at one line:
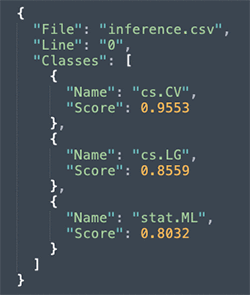
The output identifies all the subjects that apply to each abstract and their associated scores.
You can also create an endpoint with your custom multi-label classifier to enable real-time applications. Learn more about creating an endpoint for synchronous inference here.
Amazon Comprehend multi-label classification is now available in all AWS regions where Amazon Comprehend is available. To try the new feature, log in to the Amazon Comprehend console for a code-free experience, or download the AWS SDK. You can also learn more about this new feature in the documentation.
The dataset used in this post is a redacted, subsampled, and reformatted version of the AAPD dataset made available as part of Yang et al. 2018. Sequence Generation Model for Multi-Label Classification which is licensed under CC BY 4.0. A copy of the license is available here.

About the Author
 Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.
Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.