Artificial Intelligence
Apache MXNet Model Server adds optimized container images for Model Serving at scale
Today AWS released Apache MXNet Model Server (MMS) v0.3, which streamlines the deployment of model serving for production use cases. The release includes pre-built container images that are optimized for deep learning workloads on GPU and CPU. This enables engineers to set up a scalable serving infrastructure. To learn more about Apache MXNet Model Server (MMS) and how to serve deep learning models at scale – read on!
What is Apache MXNet Model Server (MMS)?
MMS is an open source model serving framework, designed to simplify the task of deploying deep learning models at scale. Here are some key advantages of MMS:
- Tooling to package MXNet and ONNX neural network models into a single Model Archive, which encapsulates all of the artifacts needed to serve the model.
- Ability to customize every step in the inference execution pipeline using custom code packaged into the Model Archive, which enables overriding initialization, pre-processing, and post-processing.
- Pre-configured serving stack, including REST API endpoints, and an inference engine.
- Pre-built and optimized container images for scalable model serving.
- Real-time operational metrics to monitor the service and endpoints.
In this blog post we review how to deploy MMS into a production environment using containers, how to monitor your cluster, and how to scale for the target demand.
Running MMS in a container
Before we jump into a scalable production-serving stack setup, let’s walk through how to run MMS in a container. Understanding this, will help you when we discuss the more complex setup of a scalable production cluster.
With the new release, pre-built and optimized MMS container images are published to Docker Hub. These images are pre-configured and optimized for CPU hosts (Amazon EC2 C5.2xlarge instance type) and multi-GPU hosts (Amazon EC2 P3.8xlarge instance type), so engineers don’t need to tweak the MMS configuration for these instance types.
Let’s go over how to run containerized MMS locally, serving the default SqueezeNet V1.1, a convolutional neural network for object classification.
First, we will install the Docker CLI, which is required to pull and run containers locally. Installation details available here.
Next, we will pull and run the pre-built MMS CPU container image from Docker Hub:
This command pulls the container image onto your host, runs it, and starts MMS with the default configuration file.
With the MMS container running, we can invoke inferences requests against MMS. We’ll start by downloading an image:
Next, we will invoke an inference request, asking MMS to classify the image:
You should see a JSON response, classifying the image as an Egyption cat with 85% probability:
To terminate the container, execute the following command:
To learn more about customizing the MMS container and the models it serves, refer to the container documentation in the MMS GitHub repository.
Orchestrating, monitoring and scaling an MMS cluster
High-scale and mission-critical production systems require a robust and monitored orchestration. Next, we’ll demonstrate how to orchestrate such a cluster with MMS and Amazon ECS, leveraging Amazon CloudWatch for monitoring and logging.
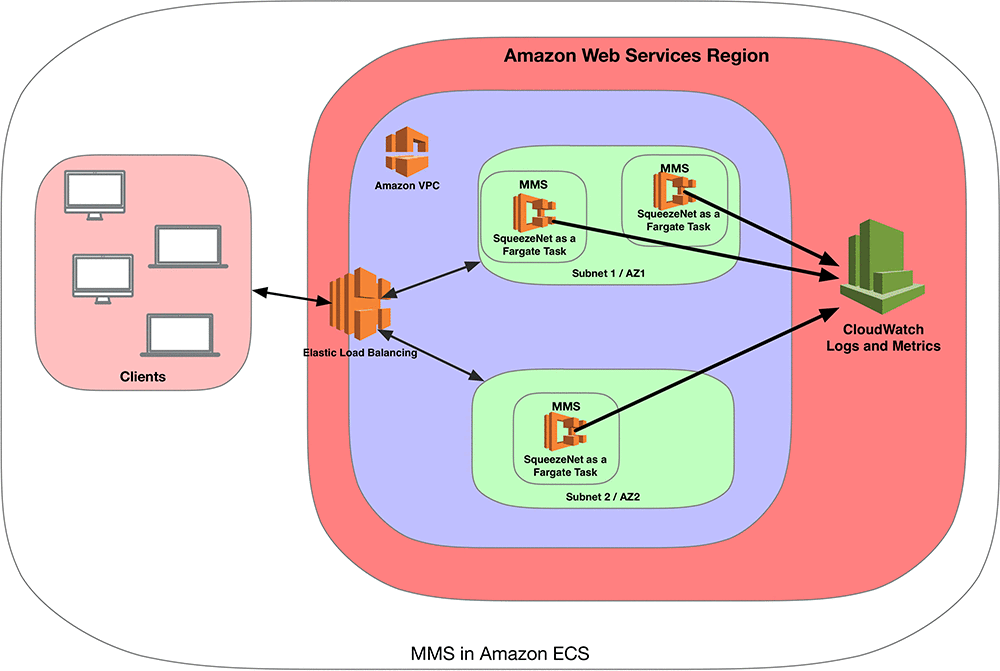
The following figure illustrates a setup that depicts a managed inference service running MMS in an Amazon ECS cluster. We have created a VPC in one of the AWS Regions. The VPC is configured with two Availability Zones, which provides service level redundancy and security. Each of these Availability Zones is running MMS as an AWS Fargate task. AWS Fargate technology allows you to run containers without having to manage the underlying servers. This allows you to scale seamlessly and pay only for resources used by the AWS Fargate tasks used for MMS. This managed inference service is also integrated with Amazon CloudWatch for logs and metrics and for monitoring. An Elastic Load Balancing service load balancer is attached to this VPC, which provides a public DNS name. Clients use the load balancer’s public DNS name to submit their inference requests.
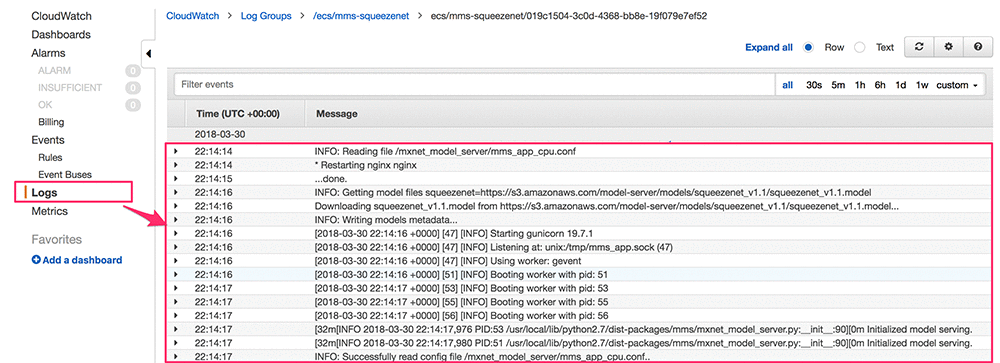
Each MMS Fargate task is configured with awslogs as the logDriver. This pushes the service-specific logs to CloudWatch. To access these logs, log onto the Amazon CloudWatch console and look for the configured log-group under the Logs tab. The following screenshot of the CloudWatch Logs page shows you that the MMS service started successfully and is ready to serve inference requests for “SqueezeNet V1.1”.
Similarly, MMS publishes service-specific metrics to CloudWatch. To set this up, you should ensure that the Task Role configured for the Fargate task has the associated CloudWatch policies to publish the metric-data. These metrics can be used to create alarms to get real-time notifications about the cluster’s health and performance. These metrics can also be used to trigger auto-scaling of the cluster.
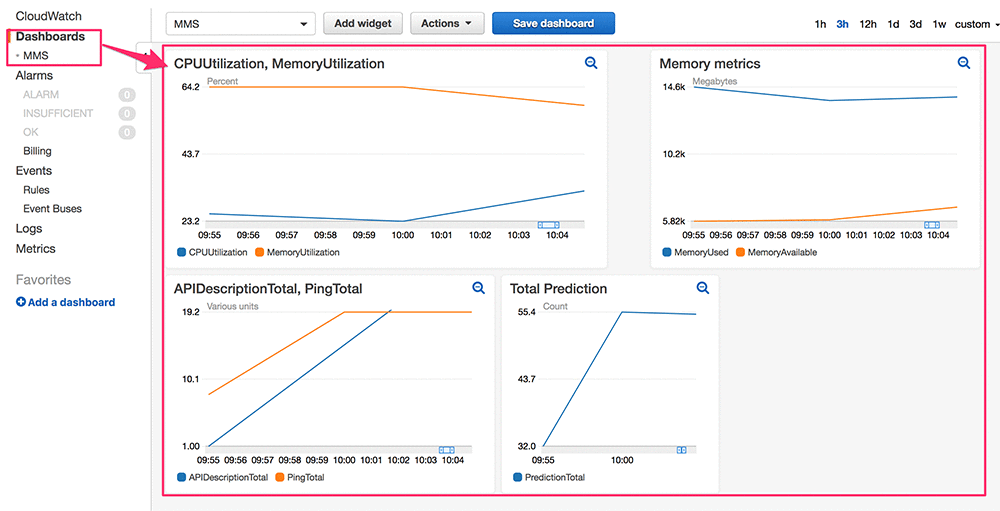
To learn more about the real-time CloudWatch metrics that are published by MMS, refer to the Metrics on Model Server document.
To learn more about the MMS production setup, refer to the MXNet Model Server documentation.
MMS performance and scalability
As mentioned earlier, the pre-built MMS container images are pre-configured and optimized for specific target platforms: the CPU image is optimized for the Amazon EC2 C5.2xlarge instance type, and the GPU image is optimized for the Amazon EC2 P3.8xlarge instance type. These container images come installed with the required drivers and packages, leverage optimized linear algebra libraries, and are pre-configured with the optimal number of worker processes, GPU assignment per process, and other configuration options. To learn more about tweaking the container configuration for your use case and hardware, see Advanced Settings in the documentation.
Load tests executed against MMS pre-built container images, serving a ResNet-18 convolutional neural network, show that a single CPU instance handles more than 100 requests per second, and a single multi-GPU instance handles more than 650 requests per second – both with zero error rate.
With the orchestrated container cluster setup we described, it’s easy to scale out the cluster to address service demand of an arbitrary scale by launching new task instances to the running service in the cluster.
Learn more and contribute
To learn more about MMS, start with our Single Shot Multi Object Detection (SSD) tutorial, which walks you through exporting and serving an SSD model. You can find more examples and documentation in the repository’s model zoo and documentation folder.
As we continue to develop MMS, we welcome community participation submitted as questions, requests, and contributions. If you are using MMS already, we welcome your feedback via the repository’s GitHub issues.
Head over to awslabs/mxnet-model-server to get started!
About the Authors
 Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton.
Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton.
 Ankit Khedia is a a Software Engineer with AWS Deep Learning. He focus area involves developing systems and applications which puts deep learning in the hands of developers and researchers for easy usage. Outside of work, he likes swimming , traveling and hiking.
Ankit Khedia is a a Software Engineer with AWS Deep Learning. He focus area involves developing systems and applications which puts deep learning in the hands of developers and researchers for easy usage. Outside of work, he likes swimming , traveling and hiking.
 Hagay Lupesko is an Engineering Leader for AWS Deep Learning. He focuses on building deep learning systems that enable developers and scientists to build intelligent applications. In his spare time, he enjoys reading, hiking, and spending time with his family.
Hagay Lupesko is an Engineering Leader for AWS Deep Learning. He focuses on building deep learning systems that enable developers and scientists to build intelligent applications. In his spare time, he enjoys reading, hiking, and spending time with his family.