Artificial Intelligence
AWS and NVIDIA achieve the fastest training times for Mask R-CNN and T5-3B
Note: At the AWS re:Invent Machine Learning Keynote we announced performance records for T5-3B and Mask-RCNN. This blog post includes updated numbers with additional optimizations since the keynote aired live on 12/8.
At re:Invent 2019, we demonstrated the fastest training times on the cloud for Mask R-CNN, a popular instance segmentation model, and BERT, a popular natural language processing (NLP) model. Over the past several months, we have worked in collaboration with NVIDIA to significantly improve the underlying infrastructure, network, machine learning (ML) framework, and model code to once again achieve the best training times for state-of-the-art models used by our customers. Today, we’re excited to share with you the fastest training times for Mask R-CNN on TensorFlow and PyTorch and T5-3B (NLP) on PyTorch, and dive deep into the technology stack, our optimizations, and how you can leverage these capabilities to train large models quickly with Amazon SageMaker.
Summary results
Our customers training deep neural network models in PyTorch and TensorFlow have asked for help with problems they face with training speed and model size. First, customers told us they wanted to train models faster without waiting days or weeks for results. Data scientists need to iterate daily to get ML applications to market faster. Second, customers told us they struggled to apply the latest research in NLP because these model architectures didn’t fit in a single NVIDIA GPU’s memory during training. Customers knew they could get higher accuracy from these larger models with billions of parameters. But there was no easy way to automatically and efficiently split a model across multiple NVIDIA GPUs.
To solve these problems, AWS released new SageMaker distributed training libraries, which provide the easiest and fastest way to train deep learning models. The SageMaker data parallelism library provides better scaling efficiency than Horovod or PyTorch’s Distributed Data Parallel (DDP), and its model parallelism library automatically splits large models across multiple GPUs. In this post, we describe how this underlying technology was used to achieve record training times for Mask R-CNN and T5-3B.
Mask R-CNN
Object detection algorithms form the backbone of many deep learning applications. Self-driving cars, security systems, and image processing all incorporate object detection. In particular, Mask R-CNN is ubiquitous in this field. Mask R-CNN takes in an image and then isolates and identifies objects within that image, providing both a bounding box and object mask. Since it was first proposed in 2017, training Mask R-CNN on the COCO dataset has become the standard benchmark for object detection models, and many of our customers use this as their baseline to build their own models.
One issue with Mask R-CNN is its complexity. The model incorporates multiple different neural networks performing different tasks. One network identifies candidate objects, while two others are responsible for identifying objects and generating masks. In addition, the model must perform operations like non-max suppression and sample selection, which can be difficult to optimize on the GPU. In the original 2017 paper, Mask R-CNN took 32 hours to train on 8 GPUs with the COCO data. Since then, training time has significantly improved. In 2019, we demonstrated the fastest training times in the cloud for Mask R-CNN—27 minutes with PyTorch and 28 minutes with TensorFlow. In 2020, we collaborated with NVIDIA to bring this down to 6:45 minutes on PyTorch and 6:12 minutes on TensorFlow. To our knowledge, this is the fastest time to train Mask R-CNN in the cloud and a 75% reduction from our record last year.
Mask-RCNN Technology stack and performance
Achieving these results required optimizations to the underlying hardware, networking, and software stack. We added GPU implementations of some operations that are central to training Mask R-CNN. We also added new data pipelining utilities to speed up pre-processing and avoid any degradation in GPU utilization. In collaboration with NVIDIA, we deployed a new optimizer, NovoGrad, to push the boundaries further on large batch training. All of these optimizations are available in SageMaker, the AWS Deep Learning Containers, and the AWS Deep Learning AMIs. The result is that our training times this year are more than twice as fast on a single-node workload, and more than three times as fast on a multi-node workload, as compared to 2019.
Next, we scaled this optimized single-node workload to a cluster of 64 p3dn.24xlarge instances, each with 8 NVIDIA V100 GPUs. Efficiently scaling to 512 V100 GPUs requires fully utilizing the available bandwidth and topology between Amazon Elastic Compute Cloud (Amazon EC2) instances. At SC20 this year, we demonstrated a reimagined parameter server at scale that was designed from scratch to use the AWS Elastic Fabric Adapter (EFA) and node-to-node communication between EC2 instances. This technology is available to developers as of today with the SageMaker data parallelism library, with native framework APIs for both TensorFlow and PyTorch.
Distributed training generally uses one of two distribution strategies: parameter servers or AllReduce. Although parameter servers can perform gradient reduction with less communication than AllReduce (2 hops vs. 2(n-1) hops, respectively) and can perform asynchronous parameter updates, parameter servers tend to suffer from uneven bandwidth allocation and network congestion. Both drawbacks become more apparent with larger clusters. As a result, AllReduce is more often used. However, AllReduce has its own drawbacks. In addition to the increased number of hops, AllReduce requires synchronous updates between nodes, meaning all training is impacted by a single straggler node.
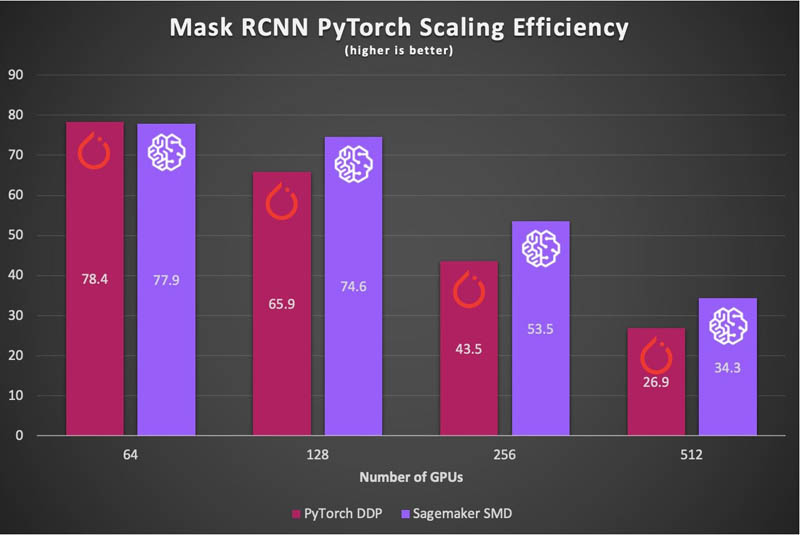
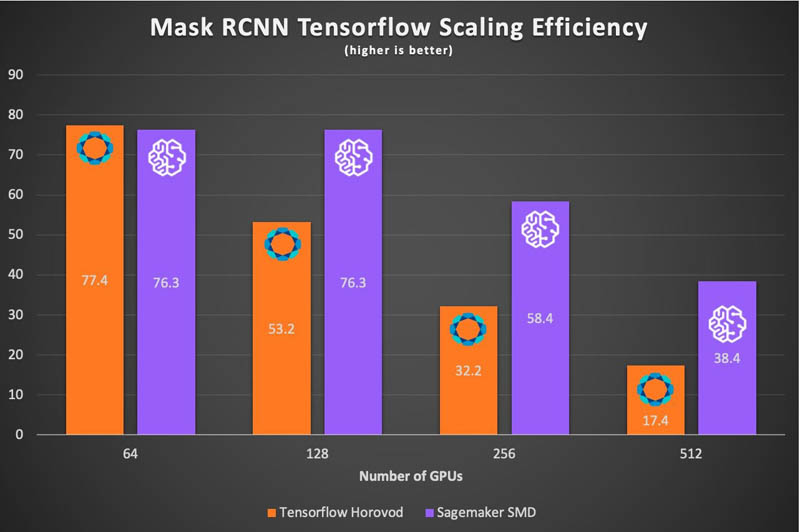
We can use EFA to overcome network congestion by spreading communication evenly across multiple routes between nodes. In addition, SageMaker introduces a balanced fusion buffer, which collects gradients on each GPU and shards them evenly to each parameter server, ensuring a balanced workload across the entire cluster. The results show significantly improved scaling efficiency, and reduced training times on larger clusters. With SageMaker, along with new large batch optimizations, we can efficiently scale both TensorFlow and PyTorch to 512 A100 GPUs, while scaling almost linearly. With these new tools, we can train Mask R-CNN to convergence in just above 6 minutes on both frameworks, beating last year’s best time by more than 75%. The following charts show the improvement in scaling efficiency using SageMaker’s data parallelism library when training Mask-RCNN relative to DDP and Horovod.
T5-3B: Text-to-Text Transfer Transformer
We’ve seen rapid progress in NLP model accuracy in the past few years. In 2017, we saw the invention of the transformer layer, a novel way for models to identify the portion of the text to focus on. We then saw state-of-the-art models such as BERT, RoBERTa, ALBERT, and DistilBERT. Now we see researchers achieving record accuracy and zero- or few-shot learning with large models that have billions or hundreds of billions of parameters.
Empirical results from OpenAI show that optimal performance comes from scaling up in three dimensions: model size, dataset size, and training steps. Model size is the primary bottleneck, and for smaller models such as BERT, data parallelism alone has been sufficient. Yet scaling to extreme language model sizes has been prohibitively difficult for developers and researchers because models can no longer fit onto a single GPU’s memory, preventing any data parallelism from taking place.
T5 is 15 times larger than the original BERT model and achieved near-human performance on the SuperGLUE benchmark. In addition, sequence-to-sequence models can perform machine translation, text summarization, and open-domain question-answering. In collaboration with NVIDIA, who supplied the base technology for T5 pre-training and fine-tuning tasks [1], we trained T5-3B in 4.68 days on 2,048 A100 GPUs on 256 p4d.24xlarge instances. The technologies for automatic and efficient splitting of large models across multiple GPU devices are now available in SageMaker.
T5-3B Technology stack and performance
SageMaker splits the model into multiple partitions that each fit on a single GPU. The freed memory can then be used to scale to larger batch sizes, further increasing training throughput and speeding up convergence. SageMaker also implements pipelined execution that splits data into smaller micro-batches and interleaves execution to increase GPU utilization.
The following figure illustrates an example execution schedule for the interleaved pipeline over two GPUs. F0 represents the forward pass for micro-batch 0, and B1 represents the backward pass for micro-batch 1. “Update” represents the optimizer update of the parameters. The figure shows that GPU0 always prioritizes backward passes whenever possible (for instance, running B0 before F2), which allows for clearing the memory used for activations earlier.

To train T5-3B, SageMaker performed 8-way model parallel training combined with 256-way data parallel training. We further improved training time by using the new p4d.24xlarge instances, equipped with 8 NVIDIA A100 GPUs and supporting 400 Gbps network bandwidth. We reduced the training time to 4.68 days by efficiently scaling out to 256 instances. We used EFA to optimize network communication over large clusters. We achieved the best training performance by using SageMaker, 256 p4d.24xlarge instances, and EFA.
To evaluate model performance, we fine-tuned the pre-trained checkpoints on a downstream natural language inference task. We used the Multi-Genre Natural Language Inference (MNLI) corpus for fine-tuning. The corpus contains around 433,000 hypothesis/premise sentence pairs and covers a range of genres of spoken and written text with support for cross-genre evaluation. We obtained a score of 91.48 for in-genre (matched) and a score of 91.29 for cross-genre (mismatched) in only 4.68 days time to train.
Conclusion
With these new record-breaking training times, AWS continues to be the industry leader in cloud ML. These models are now available for everyone to use in AWS by leveraging the new SageMaker data parallelism and model parallelism libraries. You can get started with distributed training on SageMaker using the following examples. For further information, please feel free to reach out to Aditya Bindal directly at bindala@amazon.com.
Editor’s Note: All of the following contributors were essential to our ability to achieve this year’s results and to the writing of this post (listed in alphabetical order by last name): Rahul Huilgol, Rejin Joy, Sami Kama, Gautam Kumar, Yu Liu, Roshani Nagmote, Sam Oshin, Harsh Patel, Abhinav Sharma, Anurag Singh, Lai Wei, Qinggang Zhou, Sheng Zha, and Shuai Zheng.
About the Authors
 Aditya Bindal is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to train deep learning models on AWS. In his spare time, he enjoys spending time with his daughter, playing tennis, reading historical fiction, and traveling.
Aditya Bindal is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to train deep learning models on AWS. In his spare time, he enjoys spending time with his daughter, playing tennis, reading historical fiction, and traveling.
 Abhinav Sharma is a Software Engineer at AWS Deep Learning. He works on bringing state-of-the-art deep learning research to customers, building products that help customers use deep learning engines. Outside of work, he enjoys playing tennis, noodling on his guitar and watching thriller movies.
Abhinav Sharma is a Software Engineer at AWS Deep Learning. He works on bringing state-of-the-art deep learning research to customers, building products that help customers use deep learning engines. Outside of work, he enjoys playing tennis, noodling on his guitar and watching thriller movies.
 Ben Snyder is an applied scientist with AWS Deep Learning. His research interests include computer vision models, reinforcement learning, and distributed optimization. Outside of work, he enjoys cycling and backcountry camping.
Ben Snyder is an applied scientist with AWS Deep Learning. His research interests include computer vision models, reinforcement learning, and distributed optimization. Outside of work, he enjoys cycling and backcountry camping.
 Derya Cavdar is currently working as a software engineer at AWS AI in Palo Alto, CA. She received her PhD in Computer Engineering from Bogazici University, Istanbul, Turkey, in 2016. Her research interests are deep learning, distributed training optimization, large-scale machine learning systems, and performance modeling.
Derya Cavdar is currently working as a software engineer at AWS AI in Palo Alto, CA. She received her PhD in Computer Engineering from Bogazici University, Istanbul, Turkey, in 2016. Her research interests are deep learning, distributed training optimization, large-scale machine learning systems, and performance modeling.
 Jared Nielsen is an Applied Scientist with AWS Deep Learning. His research interests include natural language processing, reinforcement learning, and large-scale training optimizations. He is a passionate rock climber outside of work.
Jared Nielsen is an Applied Scientist with AWS Deep Learning. His research interests include natural language processing, reinforcement learning, and large-scale training optimizations. He is a passionate rock climber outside of work.
 Khaled ElGalaind is the engineering manager for AWS Deep Engine Benchmarking, focusing on performance improvements for AWS machine learning customers. Khaled is passionate about democratizing deep learning. Outside of work, he enjoys volunteering with the Boy Scouts, BBQ, and hiking in Yosemite.
Khaled ElGalaind is the engineering manager for AWS Deep Engine Benchmarking, focusing on performance improvements for AWS machine learning customers. Khaled is passionate about democratizing deep learning. Outside of work, he enjoys volunteering with the Boy Scouts, BBQ, and hiking in Yosemite.
Brian Pickering is the VP of Sales & Business Development – Amazon Relationship at NVIDIA. He joined NVIDIA in 2016 to manage NVIDIA’s relationship with Amazon. Prior to NVIDIA, Brian was at F5 Networks, where he led their Cloud Sales and Cloud Partner Ecosystem. In 2012, while at AWS and responsible for leading the AWS Consulting Partner Ecosystem program and teams, CRN recognized Brian as one of the top 100 “People You Don’t Know But Should for Channel.” Prior to AWS, Brian lead various strategic business efforts, including winning the first non-MS OS OEM deal with Dell while at Red Hat.
Anish Mohan is a Machine Learning Architect at NVIDIA and the technical lead for ML/DL engagements with key NVIDIA customers in the greater Seattle region. Before NVIDIA, he was at Microsoft’s AI Division, working to develop and deploy AI/ML algorithms and solutions.