Artificial Intelligence
AWS Finance and Global Business Services builds an automated contract-processing platform using Amazon Textract and Amazon Comprehend
Processing incoming documents such as contracts and agreements is often an arduous task. The typical workflow for reviewing signed contracts involves loading, reading, and extracting contractual terms from agreements, which requires hours of manual effort and intensive labor.
At AWS Finance and Global Business Services (AWS FGBS), this process typically takes more than 150 employee hours per month. Often, multiple analysts manually input key contractual data into an Excel workbook in batches of a hundred contracts at a time.
Recently, one of the AWS FGBS teams responsible for analyzing contract agreements set out to implement an automated workflow to process incoming documents. The goal was to liberate specialized accounting resources from routine and tedious manual labor, so they had more free time to perform value-added financial analysis.
As a result, the team built a solution that consistently parses and stores important contractual data from an entire contract in under a minute with high fidelity and security. Now an automated process only requires a single analyst working 30 hours a month to maintain and run the platform. This is a 5x reduction in processing time and significantly improves operational productivity.
This application was made possible by two machine learning (ML)-powered AWS-managed services: Amazon Textract, which enables efficient document ingestion, and Amazon Comprehend, which provides downstream text processing that enables the extraction of key terms.
The following post presents an overview of this solution, a deep dive into the architecture, and a summary of the design choices made.
Contract workflow
The following diagram illustrates the architecture of the solution:

The AWS FGBS team, with help from the AWS Machine Learning (ML) Professional Services (ProServe) team, created an automated, durable, and scalable contract processing platform. Incoming contract data is stored in an Amazon Simple Storage Service (Amazon S3) data lake. The solution uses Amazon Textract to convert the contracts into text form and Amazon Comprehend for text analysis and term extraction. Critical terms and other metadata extracted from the contracts are stored in Amazon DynamoDB, a database designed to accept key-value and document data types. Accounting users can access the data via a custom web user interface hosted in Amazon CloudFront, where they can perform key user actions such as error checking, data validation, and custom term entry. They can also generate reports using a Tableau server hosted in Amazon Appstream, a fully-managed application streaming service. You can launch and host this end-to-end contract-processing platform in an AWS production environment using an AWS CloudFormation template.
Building an efficient and scalable document-ingestion engine
The contracts that the AWS FGBS team encounters often include high levels of sophistication, which has historically required human review to parse and extract relevant information. The format of these contracts has changed over time, varying in length and complexity. Adding to the challenge, the documents not only contain free text, but also tables and forms that hold important contextual information.
To meet these needs, the solution uses Amazon Textract as the document-ingestion engine. Amazon Textract is a powerful service built on top of a set of pre-trained ML computer vision models tuned to perform Optical Character Recognition (OCR) by detecting text and numbers from a rendering of a document, such as an image or PDF. Amazon Textract takes this further by recognizing tables and forms so that contextual information for each word is preserved. The team was interested in extracting important key terms from each contract, but not every contract contained the same set of terms. For example, many contracts hold a main table that has the name of a term on the left-hand side, and the value of the term on the right-hand side. The solution can use the result from the Form Extraction feature of Amazon Textract to construct a key-value pair that links the name and the value of a contract term.
The following diagram illustrates the architecture for batch processing in Amazon Textract:

A pipeline processes incoming contracts using the asynchronous Amazon Textract APIs enabled by Amazon Simple Queue Service (Amazon SQS), a distributed message queuing service. The AWS Lambda function StartDocumentTextAnalysis initiates the Amazon Textract processing jobs, which are triggered when new files are deposited into the contract data lake in Amazon S3. Because contracts are loaded in batches, and the asynchronous API can accommodate PDF files natively without first converting to an image file format, the design choice was made to build an asynchronous process to improve scalability. The solution uses DocumentAnalysis APIs instead of the DocumentDetection APIs so that recognition of tables and forms is enabled.
When a DocumentAnalysis job is complete, a JobID is returned and input into a second queue, where it is used to retrieve the completed output from Amazon Textract in the form of a JSON object. The response contains both the extracted text and document metadata within a large nested data structure. The GetDocumentTextAnalysis function handles the retrieval and storage of JSON outputs into an S3 bucket to await post-processing and term extraction.
Extracting standard and non-standard terms with Amazon Comprehend
The following diagram illustrates the architecture of key term extraction:
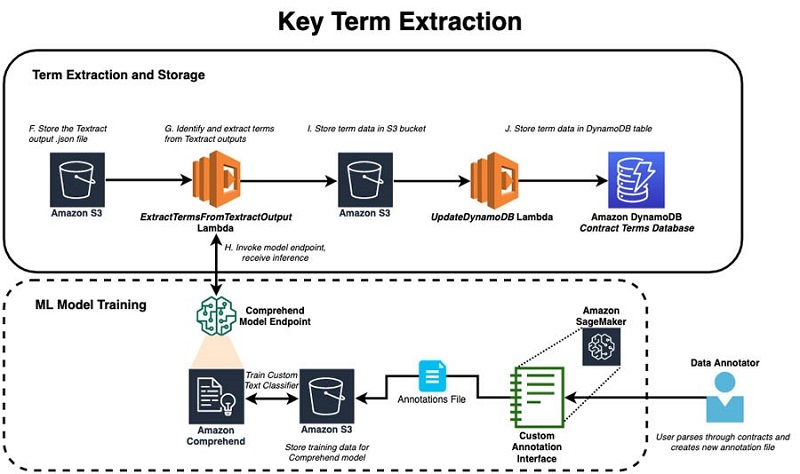
After the solution has deposited the processed contract output from Amazon Textract into an S3 bucket, a term extraction pipeline begins. The primary worker for this pipeline is the ExtractTermsFromTextractOutput function, which encodes the intelligence behind the term extraction.
There are a few key actions performed at this step:
- The contract is broken up into sections and basic attributes are extracted, such as the contract title and contract ID number.
- The standard contract terms are identified as key-value pairs. Using the table relationships uncovered in the Amazon Textract output, the solution can find the right term and value from tables containing key terms, while taking additional steps to convert the term value into the correct data format, such as parsing dates.
- There is a group of non-standard terms that can either be within a table or embedded within the free text in certain sections of the contract. The team used the Amazon Comprehend custom classification model to identify these sections of interest.
To produce the proper training data for the model, subject matter experts on the AWS FGBS team annotated a large historical set of contracts to identify examples of standard contract sections (that don’t contain any special terms) and non-standard contract sections (that contain special terms and language). An annotation platform hosted on an Amazon SageMaker instance displays individual contract sections that were split up previously using the ExtractTermsFromTextractOutput function so that a user could label the sections accordingly.
A final custom text classification model was trained to perform paragraph section classification to identify non-standard sections with an F1 score over 85% and hosted using Amazon Comprehend. One key benefit of using Amazon Comprehend for text classification is the straightforward format requirements of the training data, because the service takes care of text preprocessing steps such as feature engineering and accounting for class imbalance. These are typical considerations that need to be addressed in custom text models.
After dividing contracts into sections, a subset of the paragraphs is passed to the custom classification model endpoint from the ExtractTermsFromTextractOutput function to detect the presence of non-standard terms. The final list of contract sections that were checked and sections that were flagged as non-standard is recorded in the DynamoDB table. This mechanism notifies an accountant to examine sections of interest that require human review to interpret non-standard contract language and pick out any terms that are worth recording.
After these three stages are complete (breaking down contract sections, extracting standard terms, and classifying non-standard sections using a custom model), a nested dictionary is created with key-value pairs of terms. Error checking is also built into this processing stage. For each contract, an error file is generated that specifies exactly which term extraction caused the error and the error type. This file is deposited into the S3 bucket where contract terms are stored so that users can trace back any failed extractions for a single contract to its individual term. A special error alert phrase is incorporated into the error logging to simplify searching through Amazon CloudWatch logs to locate points where extraction errors occurred. Ultimately, a JSON file containing up to 100 or more terms is generated for each contract and pushed into an intermediate S3 bucket.
The extracted data from each contract is sent to a DynamoDB database for storage and retrieval. DynamoDB serves as a durable data store for two reasons:
- This key-value and document database has flexibility over a relational database because it can accept data structures such as large string values and nested key-value pairs, while not requiring a pre-defined schema, so that new terms can easily be added to the database in the future as contracts evolved.
- This fully managed database delivers single-digit millisecond performance at scale so the custom front end and reporting can be integrated on top of this service.
Additionally, DynamoDB supports continuous backups and point-in-time-recovery, which enables data restoration in tables to any single second for the prior 35 days. This feature was crucial in earning trust from team; it protects their critical data against accidental deletions or edits and provides business continuity of essential downstream tasks such as financial reporting. An important check to perform during data upload is the DynamoDB item-size limit, which is set at 400 KB. With longer contracts, and long lists of extracted terms, some contract outputs exceed this limit, so a check is performed in the term extraction function to break up larger entries into multiple JSON objects.
Secure data access and validation through a custom web UI
The following diagram illustrates the custom web user interface (UI) and reporting architecture:

To effectively interact with the extracted contract data, the team built a custom web UI. The web application, built using the Angular v8 framework, is hosted through Amazon S3 on Amazon CloudFront, a cloud content delivery network. When the Amazon CloudFront URL is accessed, the user is first authorized and authenticated against a user pool with strict permissions allowing them to view and interact with this UI. After validation, the session information is saved to make sure the user stays logged in for only a set amount of time.
On the landing page, the user can navigate to the three key user scenarios displayed as links on the navigation panel:
- Search for Records – View and edit a record for a contract
- View Record History – View the record edit history for a contract
- Appstream Reports – Open the reporting dashboard hosted in Appstream
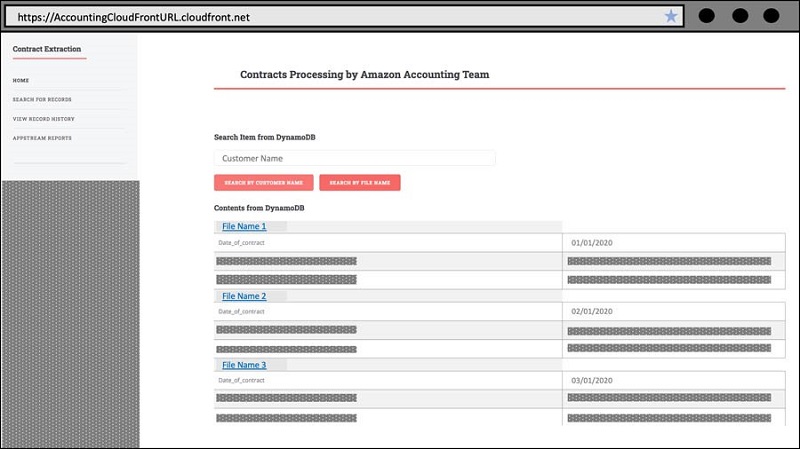
To view a certain record, the user is prompted to search for the file using the specific customer name or file name. In the former, the search returns the latest records for each contract with the same customer name. In the latter, the search only returns the latest record for a specific contract with that file name.
After the user identifies the right contract to examine or edit, the user can choose the file name and go to the Edit Record page. This displays the full list of terms for a contract and allows the user to edit, add to, or delete the information extracted from the contract. The latest record is retrieved with form fields for each term, which allows the user to choose the value to validate the data, and edit the data if errors are identified. The user can also add new fields by choosing Add New Field and entering a key-value pair for the custom term.
After updating the entry with edited or new fields, the user can choose the Update Item button. This triggers the data for the new record being passed from the frontend via Amazon API Gateway to the PostFromDynamoDB function using a POST method, generating a JSON file that is pushed to the S3 bucket holding all the extracted term data. This file triggers the same UpdateDynamoDB function that pushed the original term data to the DynamoDB table after the first Amazon Textract processing run.
After verification, the user can choose Delete Record to delete all versions of the contract consistently through the DynamoDB and to the S3 buckets that store all the extracted contract data. This is initiated using the DELETE method, triggering the DeleteFromDynamoDB function that expunges the data. During contract data validation and editing, every update to a field that is pushed creates a new data record that automatically logs a timestamp and user identity, based on the login profile, to ensure fine-grained tracking of the edit history.
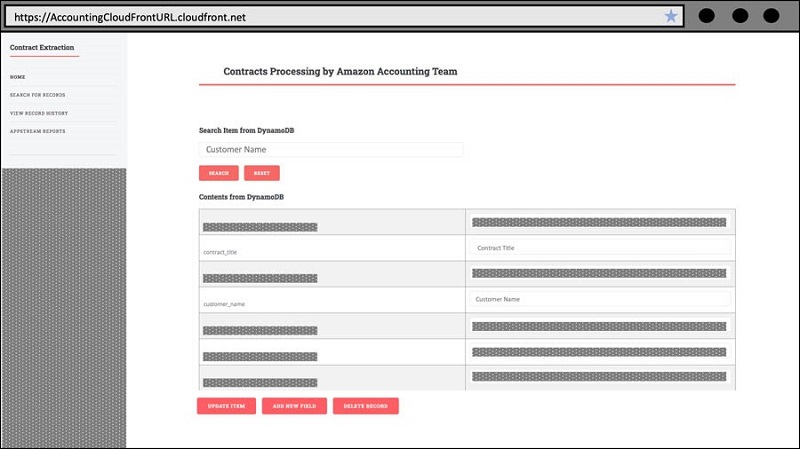
To take advantage of the edit tracking, the user can search for a contract and view the entire collection of records for a single contract, ordered by timestamp. This allows the user to compare edits made across time, including any custom fields that were added, and link those edits back to the editor identity.
To make sure the team could ultimately realize the business value from this solution, they added a reporting dashboard pipeline to the architecture. Amazon AppStream 2.0, a fully managed application streaming service, hosts an instance of the reporting application. AWS Glue crawlers build a schema for the data residing in Amazon S3, and Amazon Athena queries and loads the data into the Amazon AppStream instance and into the reporting application.
Given the sensitivity of this data for Amazon, the team implemented several security considerations so they could safely interact with the data without unauthorized third-party access. An Amazon Cognito authorizer secures the API Gateway. During user login, Amazon internal single sign-on with two-factor authentication is verified against an Amazon Cognito user pool that only contains relevant team members.
To view record history, the user can search for a contract and examine the entire collection of records for a single contract to review any erroneous or suspicious edits and trace back to the exact time of edit and identity of editor.
The team also took additional application-hardening steps to secure the architecture and front end. AWS roles and policies are ensured to be narrowly scoped according to least privilege. For storage locations such as Amazon S3 and DynamoDB, access is locked down and protected with server-side encryption enabled to cover encryption at rest, all public access is blocked, and versioning and logging is enabled. To cover encryption in transit, VPC interface endpoints powered by AWS PrivateLink connect AWS services together so data is transmitted over private AWS endpoints versus public internet. In all the Lambda functions, temporary data handling best practices are adhered to by using the Python tempfile library to address time of use attacks (TOCTOU) where attackers may pre-emptively place files at specified locations. Because Lambda is a serverless service, all data stored in a temp directory is deleted after invoking the Lambda function unless the data is pushed to another storage location, such as Amazon S3.
Customer data privacy is a top concern for the AWS FGBS team and AWS service teams. Although incorporating additional data to further train ML models in AWS services like Amazon Textract and Amazon Comprehend is crucial towards improving performance, you always retain the option to withhold your data. To prevent the retention of contract data processed by Amazon Textract and Amazon Comprehend to be stored for model retraining purposes, the AWS FGBS team requested for Customer Data Opt-Out by creating a customer support ticket.
To verify the integrity of the application given the sensitivity of the data processed, both internal security reviews and penetration testing from external vendors were performed. That included static code review, dynamic fuzz testing, form validation, script injection and cross site scripting (XSS), and other items from the OWASP top 10 web application security risks. To address distributed denial-of-service (DDos) attacks, throttling limits were set on the API Gateway, and CloudWatch alarms were set for a threshold invocation limit.
After security requirements were integrated into the application, the entire solution was codified into an AWS CloudFormation template so the solution can be launched into the team’s production account. The CloudFormation templates are comprised of nested stacks, delineating key components of the application’s infrastructure (front-end versus back-end services). A continuous deployment pipeline was set up using AWS CodeBuild to build and deploy any change to the application code or infrastructure. Development and production environments were created in two separate AWS accounts, with deployment into these environments managed by environment variables set in the respective accounts.
Conclusion
The application is now live and being tested with hundreds of contracts every month. Most importantly, the business is beginning to realize the benefits of saving time and value by automating this previously routine business process.
The AWS ProServe team is working with the AWS FGBS team on a second phase of the project to further enhance the solution. To improve accuracy of term extraction, they’re exploring pretrained and custom Amazon Comprehend NER models. They will implement a retraining pipeline so the platform intelligence can improve over time with new data. They’re also considering a new service, Amazon Augmented AI (Amazon A2I), which is a human-review capability, for aiding in reviewing low-confidence Amazon Textract outputs and generating new training data for model improvement.
As exciting new ML services are being launched by AWS, the AWS FGBS team hopes that solutions like these will replace legacy accounting practices as they continue to achieve their goals of modernizing their business operations.
Get started today! Explore your use case with the services mentioned in this post and many others on the AWS Management Console.
About the Authors
 Han Man is a Senior Data Scientist with AWS Professional Services. He has a PhD in engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today he is passionately working with customers from a variety of industries to develop and implement machine learning & AI solutions on AWS. He enjoys following the NBA and playing basketball in his spare time.
Han Man is a Senior Data Scientist with AWS Professional Services. He has a PhD in engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today he is passionately working with customers from a variety of industries to develop and implement machine learning & AI solutions on AWS. He enjoys following the NBA and playing basketball in his spare time.
AWS Finance and Global Business Services Team
 Carly Huang is a Senior Financial Analyst at Amazon Accounting supporting AWS revenue. She holds a Bachelor of Business Administration from Simon Fraser University and is a Chartered Professional Accountant (CPA) with several years of experience working as an auditor focusing on technology and manufacturing clients. She is excited to find new ways using AWS services to improve and simplify existing accounting processes. In her free time, she enjoys traveling and running.
Carly Huang is a Senior Financial Analyst at Amazon Accounting supporting AWS revenue. She holds a Bachelor of Business Administration from Simon Fraser University and is a Chartered Professional Accountant (CPA) with several years of experience working as an auditor focusing on technology and manufacturing clients. She is excited to find new ways using AWS services to improve and simplify existing accounting processes. In her free time, she enjoys traveling and running.
 Shonoy Agrawaal is a Senior Manager at Amazon Accounting supporting AWS revenue. He holds a Bachelor of Business Administration from the University of Washington and is a Certified Public Accountant with several years of experience working as an auditor focused on retail and financial services clients. Today, he supports the AWS business with accounting and financial reporting matters. In his free time, he enjoys traveling and spending time with family and friends.
Shonoy Agrawaal is a Senior Manager at Amazon Accounting supporting AWS revenue. He holds a Bachelor of Business Administration from the University of Washington and is a Certified Public Accountant with several years of experience working as an auditor focused on retail and financial services clients. Today, he supports the AWS business with accounting and financial reporting matters. In his free time, he enjoys traveling and spending time with family and friends.
AWS ProServe Team
 Nithin Reddy Cheruku is a Sr. AI/ML architect with AWS Professional Services, helping customers digital transform leveraging emerging technologies. He likes to solve and work on business and community problems that can bring a change in a more innovative manner . Outside of work, Nithin likes to play cricket and ping pong.
Nithin Reddy Cheruku is a Sr. AI/ML architect with AWS Professional Services, helping customers digital transform leveraging emerging technologies. He likes to solve and work on business and community problems that can bring a change in a more innovative manner . Outside of work, Nithin likes to play cricket and ping pong.
 Huzaifa Zainuddin is a Cloud Infrastructure Architect with AWS Professional Services. He has several years of experience working in a variety different technical roles. He currently works with customers to help design their infrastructure as well deploy, and scale applications on AWS. When he is not helping customers, he enjoys grilling, traveling, and playing the occasional video games.
Huzaifa Zainuddin is a Cloud Infrastructure Architect with AWS Professional Services. He has several years of experience working in a variety different technical roles. He currently works with customers to help design their infrastructure as well deploy, and scale applications on AWS. When he is not helping customers, he enjoys grilling, traveling, and playing the occasional video games.
 Ananya Koduri is an Application Cloud Architect with the AWS Professional Services – West Coast Applications Teams. With a Master’s Degree in Computer Science, she’s been a consultant in the tech industry for 5 years, with varied clients in the Government, Mining and the Educational sector. In her current role, she works closely with the clients to implement the architectures on AWS. In her spare time she enjoys long hikes and is a professional classical dancer.
Ananya Koduri is an Application Cloud Architect with the AWS Professional Services – West Coast Applications Teams. With a Master’s Degree in Computer Science, she’s been a consultant in the tech industry for 5 years, with varied clients in the Government, Mining and the Educational sector. In her current role, she works closely with the clients to implement the architectures on AWS. In her spare time she enjoys long hikes and is a professional classical dancer.
 Vivek Lakshmanan is a Data & Machine Learning Engineer at Amazon Web Services. He has a Master’s degree in Software Engineering with specialization in Data Science from San Jose State University. Vivek is excited on applying cutting-edge technologies and building AI/ML solutions to customers in cloud. He is passionate about Statistics, NLP and Model Explainability in AI/ML. In his spare time, he enjoys playing cricket and taking unplanned road trips.
Vivek Lakshmanan is a Data & Machine Learning Engineer at Amazon Web Services. He has a Master’s degree in Software Engineering with specialization in Data Science from San Jose State University. Vivek is excited on applying cutting-edge technologies and building AI/ML solutions to customers in cloud. He is passionate about Statistics, NLP and Model Explainability in AI/ML. In his spare time, he enjoys playing cricket and taking unplanned road trips.