Artificial Intelligence
Category: Amazon Titan

How Palo Alto Networks enhanced device security infra log analysis with Amazon Bedrock
Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. They partnered with the AWS Generative AI Innovation Center (GenAIIC) to develop an automated log classification pipeline powered by Amazon Bedrock. In this post, we discuss how Amazon Bedrock, through Anthropic’ s Claude Haiku model, and Amazon Titan Text Embeddings work together to automatically classify and analyze log data. We explore how this automated pipeline detects critical issues, examine the solution architecture, and share implementation insights that have delivered measurable operational improvements.
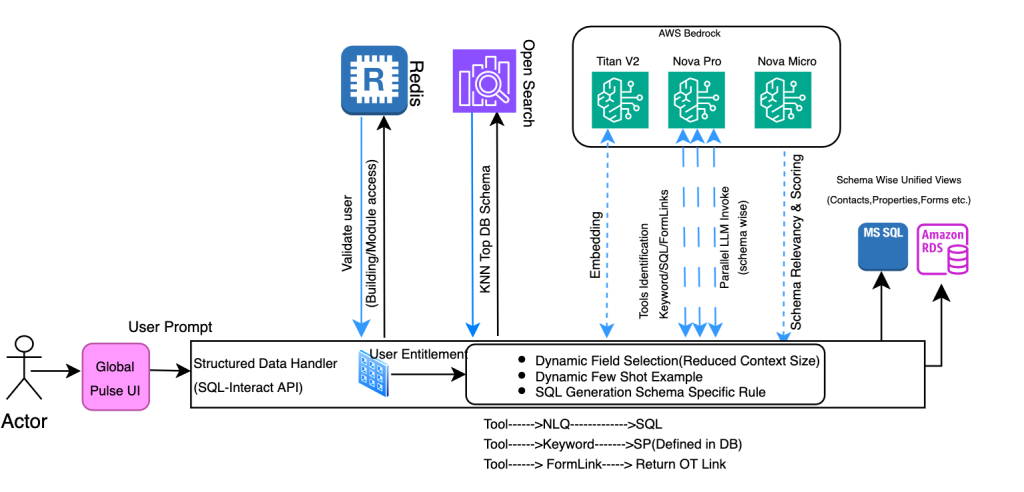
How CBRE powers unified property management search and digital assistant using Amazon Bedrock
In this post, CBRE and AWS demonstrate how they transformed property management by building a unified search and digital assistant using Amazon Bedrock, enabling professionals to access millions of documents and multiple databases through natural language queries. The solution combines Amazon Nova Pro for SQL generation and Claude Haiku for document interactions, achieving a 67% reduction in processing time while maintaining enterprise-grade security across more than eight million documents.

Using Amazon OpenSearch ML connector APIs
OpenSearch offers a wide range of third-party machine learning (ML) connectors to support this augmentation. This post highlights two of these third-party ML connectors. The first connector we demonstrate is the Amazon Comprehend connector. In this post, we show you how to use this connector to invoke the LangDetect API to detect the languages of ingested documents. The second connector we demonstrate is the Amazon Bedrock connector to invoke the Amazon Titan Text Embeddings v2 model so that you can create embeddings from ingested documents and perform semantic search.

Combine keyword and semantic search for text and images using Amazon Bedrock and Amazon OpenSearch Service
In this post, we walk you through how to build a hybrid search solution using OpenSearch Service powered by multimodal embeddings from the Amazon Titan Multimodal Embeddings G1 model through Amazon Bedrock. This solution demonstrates how you can enable users to submit both text and images as queries to retrieve relevant results from a sample retail image dataset.
Build a computer vision-based asset inventory application with low or no training
In this post, we present a solution using generative AI and large language models (LLMs) to alleviate the time-consuming and labor-intensive tasks required to build a computer vision application, enabling you to immediately start taking pictures of your asset labels and extract the necessary information to update the inventory using AWS services

Generate synthetic counterparty (CR) risk data with generative AI using Amazon Bedrock LLMs and RAG
In this post, we explore how you can use LLMs with advanced Retrieval Augmented Generation (RAG) to generate high-quality synthetic data for a finance domain use case. You can use the same technique for synthetic data for other business domain use cases as well. For this post, we demonstrate how to generate counterparty risk (CR) data, which would be beneficial for over-the-counter (OTC) derivatives that are traded directly between two parties, without going through a formal exchange.

Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock
This post presents a strategy for optimizing LLM-based applications. Given the increasing need for efficient and cost-effective AI solutions, we present a serverless read-through caching blueprint that uses repeated data patterns. With this cache, developers can effectively save and access similar prompts, thereby enhancing their systems’ efficiency and response times.

Automate Q&A email responses with Amazon Bedrock Knowledge Bases
In this post, we illustrate automating the responses to email inquiries by using Amazon Bedrock Knowledge Bases and Amazon Simple Email Service (Amazon SES), both fully managed services. By linking user queries to relevant company domain information, Amazon Bedrock Knowledge Bases offers personalized responses.

Build cost-effective RAG applications with Binary Embeddings in Amazon Titan Text Embeddings V2, Amazon OpenSearch Serverless, and Amazon Bedrock Knowledge Bases
Today, we are happy to announce the availability of Binary Embeddings for Amazon Titan Text Embeddings V2 in Amazon Bedrock Knowledge Bases and Amazon OpenSearch Serverless. This post summarizes the benefits of this new binary vector support and gives you information on how you can get started.

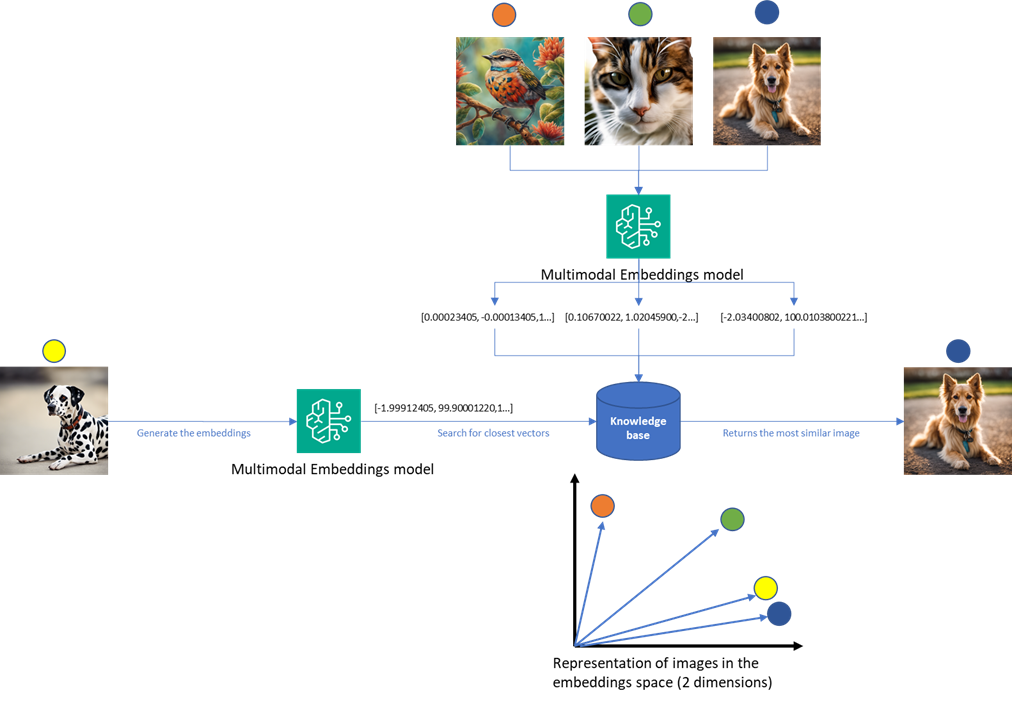
Build a reverse image search engine with Amazon Titan Multimodal Embeddings in Amazon Bedrock and AWS managed services
In this post, you will learn how to extract key objects from image queries using Amazon Rekognition and build a reverse image search engine using Amazon Titan Multimodal Embeddings from Amazon Bedrock in combination with Amazon OpenSearch Serverless Service.