Artificial Intelligence
Category: Amazon Machine Learning
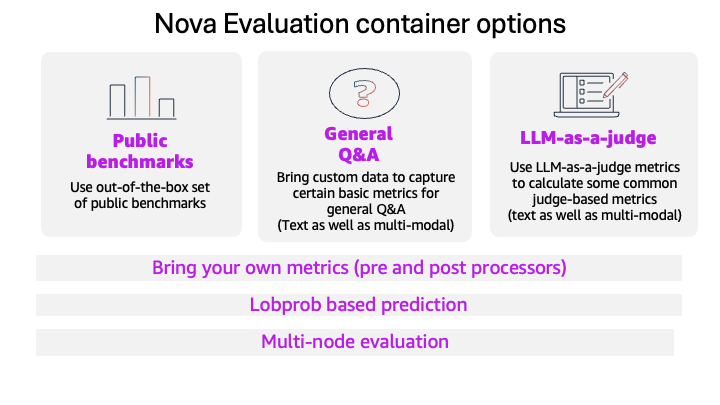
Evaluate models with the Amazon Nova evaluation container using Amazon SageMaker AI
This blog post introduces the new Amazon Nova model evaluation features in Amazon SageMaker AI. This release adds custom metrics support, LLM-based preference testing, log probability capture, metadata analysis, and multi-node scaling for large evaluations.

Enhanced performance for Amazon Bedrock Custom Model Import
You can now achieve significant performance improvements when using Amazon Bedrock Custom Model Import, with reduced end-to-end latency, faster time-to-first-token, and improved throughput through advanced PyTorch compilation and CUDA graph optimizations. With Amazon Bedrock Custom Model Import you can to bring your own foundation models to Amazon Bedrock for deployment and inference at scale. In this post, we introduce how to use the improvements in Amazon Bedrock Custom Model Import.

Accelerate generative AI innovation in Canada with Amazon Bedrock cross-Region inference
We are excited to announce that customers in Canada can now access advanced foundation models including Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5 on Amazon Bedrock through cross-Region inference (CRIS). This post explores how Canadian organizations can use cross-Region inference profiles from the Canada (Central) Region to access the latest foundation models to accelerate AI initiatives. We will demonstrate how to get started with these new capabilities, provide guidance for migrating from older models, and share recommended practices for quota management.

Claude Opus 4.5 now in Amazon Bedrock
Anthropic’s newest foundation model, Claude Opus 4.5, is now available in Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models from leading AI companies. In this post, I’ll show you what makes this model different, walk through key business applications, and demonstrate how to use Opus 4.5’s new tool use capabilities on Amazon Bedrock.

Deploy GPT-OSS models with Amazon Bedrock Custom Model Import
In this post, we show how to deploy the GPT-OSS-20B model on Amazon Bedrock using Custom Model Import while maintaining complete API compatibility with your current applications.
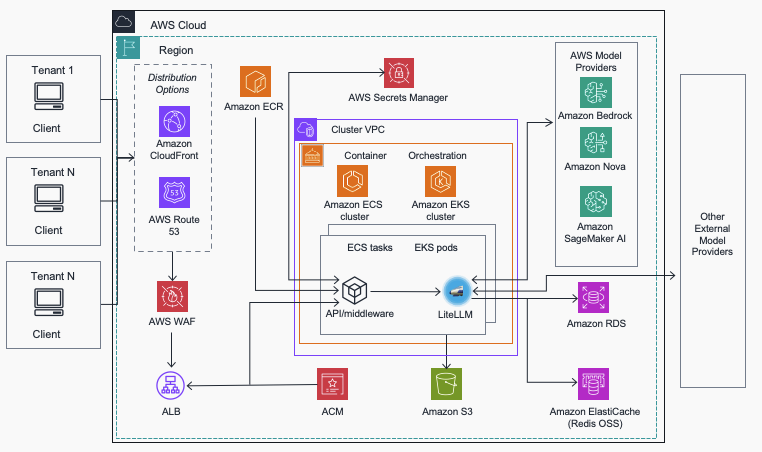
Streamline AI operations with the Multi-Provider Generative AI Gateway reference architecture
In this post, we introduce the Multi-Provider Generative AI Gateway reference architecture, which provides guidance for deploying LiteLLM into an AWS environment to streamline the management and governance of production generative AI workloads across multiple model providers. This centralized gateway solution addresses common enterprise challenges including provider fragmentation, decentralized governance, operational complexity, and cost management by offering a unified interface that supports Amazon Bedrock, Amazon SageMaker AI, and external providers while maintaining comprehensive security, monitoring, and control capabilities.
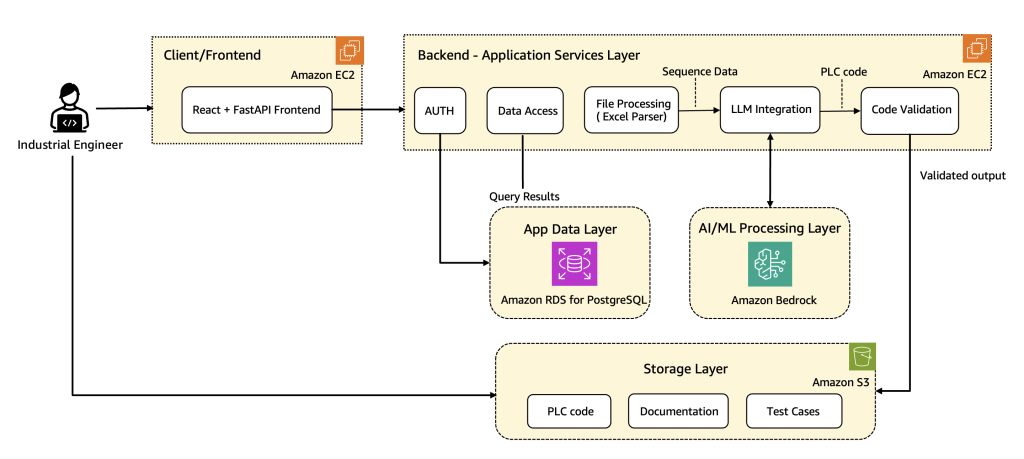
How Wipro PARI accelerates PLC code generation using Amazon Bedrock
In this post, we share how Wipro implemented advanced prompt engineering techniques, custom validation logic, and automated code rectification to streamline the development of industrial automation code at scale using Amazon Bedrock. We walk through the architecture along with the key use cases, explain core components and workflows, and share real-world results that show the transformative impact on manufacturing operations.
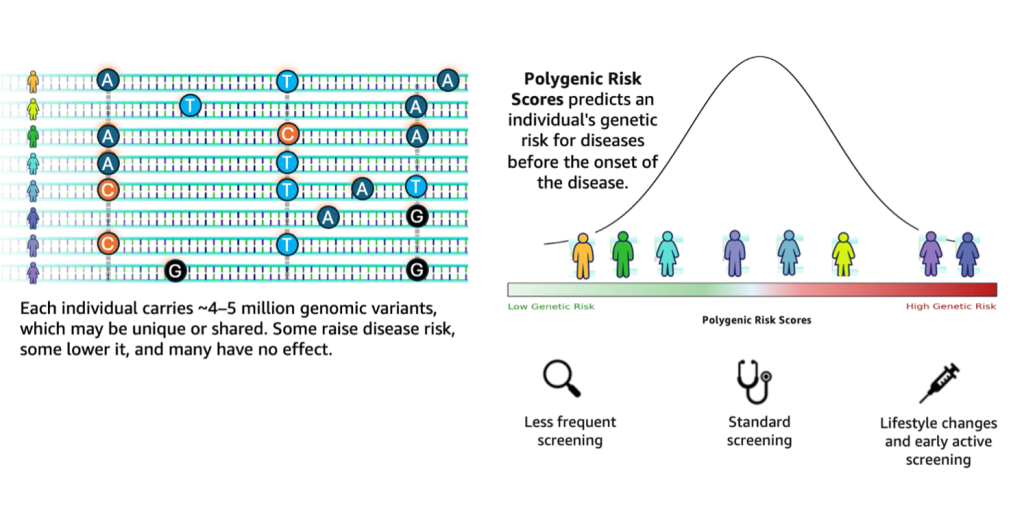
Accelerating genomics variant interpretation with AWS HealthOmics and Amazon Bedrock AgentCore
In this blog post, we show you how agentic workflows can accelerate the processing and interpretation of genomics pipelines at scale with a natural language interface. We demonstrate a comprehensive genomic variant interpreter agent that combines automated data processing with intelligent analysis to address the entire workflow from raw VCF file ingestion to conversational query interfaces.
How Rufus scales conversational shopping experiences to millions of Amazon customers with Amazon Bedrock
Our team at Amazon builds Rufus, an AI-powered shopping assistant which delivers intelligent, conversational experiences to delight our customers. More than 250 million customers have used Rufus this year. Monthly users are up 140% YoY and interactions are up 210% YoY. Additionally, customers that use Rufus during a shopping journey are 60% more likely to […]

How Care Access achieved 86% data processing cost reductions and 66% faster data processing with Amazon Bedrock prompt caching
In this post, we demonstrate how healthcare organizations can securely implement prompt caching technology to streamline medical record processing while maintaining compliance requirements.