Artificial Intelligence
Category: Amazon Bedrock Data Automation

Build an agentic AI healthcare claims pipeline with Amazon Bedrock and AWS HealthLake
In this post, we show you how to build an automated claims processing pipeline using two key Amazon Bedrock capabilities: Amazon Bedrock Data Automation for intelligent document extraction from healthcare claim forms, and Amazon Bedrock AgentCore for hosting an AI agent that validates and transforms the extracted data into FHIR (Fast Healthcare Interoperable Resources) resources in AWS HealthLake. You will learn how to combine these services to create an end-to-end workflow that reduces manual processing while maintaining accuracy through automated validation checks.

From PDFs to insights: Architecting an intelligent document processing pipeline with AWS generative AI services
This post outlines the development of a cost-effective and scalable intelligent document processing pipeline on AWS, powered by Amazon Bedrock and its features. BDA is a managed service within Amazon Bedrock that automates the extraction of insights from documents. We demonstrate how BDA extracts and analyzes document content, while Strands Agent hosted on Amazon Bedrock AgentCore Runtime coordinate specialized processing tasks, and Amazon Bedrock Knowledge Base enable contextual understanding across multiple documents. By combining these capabilities within a unified architecture, organizations can transform their document processing workflows with minimal development effort.

Optimize blueprint extraction accuracy in Amazon Bedrock Data Automation
Blueprint instruction optimization is a BDA feature that automatically refines your extraction instructions to address this challenge directly. You provide three to ten example documents with expected values, and BDA refines your blueprint instructions to improve accuracy in minutes, not weeks. No separate model fine-tuning is required.
By the end of this post, you can optimize your blueprints to improve accuracy, run the optimization workflow through the Amazon Bedrock console or the API, and apply best practices for selecting examples and ground truth.

Detect and redact personally identifiable information using Amazon Bedrock Data Automation and Guardrails
This post shows an automated PII detection and redaction solution using Amazon Bedrock Data Automation and Amazon Bedrock Guardrails through a use case of processing text and image content in high volumes of incoming emails and attachments. The solution features a complete email processing workflow with a React-based user interface for authorized personnel to more securely manage and review redacted email communications and attachments. We walk through the step-by-step solution implementation procedures used to deploy this solution. Finally, we discuss the solution benefits, including operational efficiency, scalability, security and compliance, and adaptability.
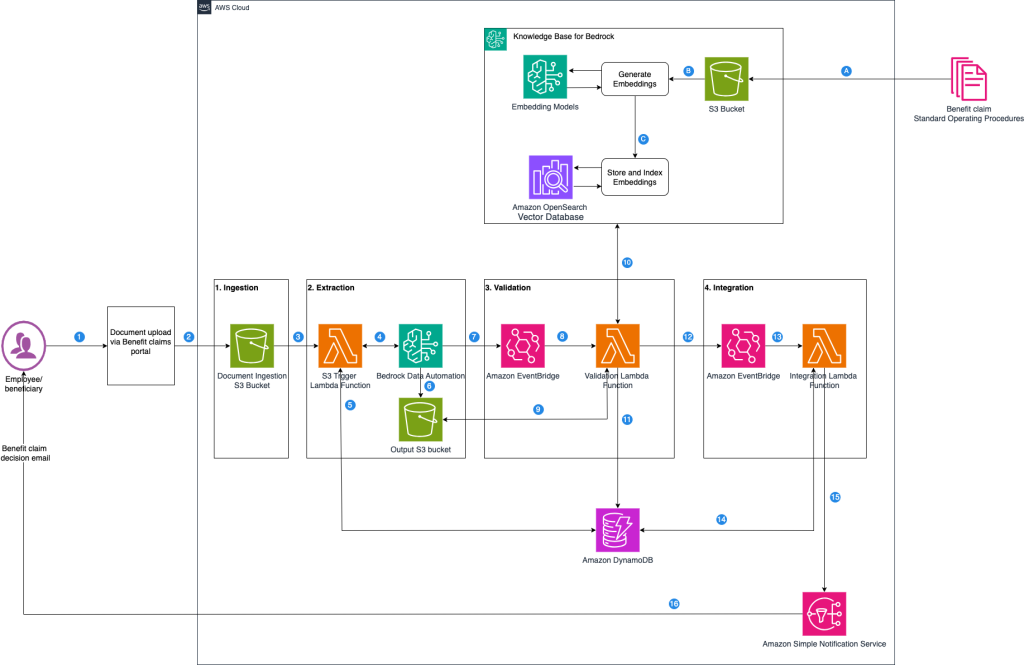
Accelerate benefits claims processing with Amazon Bedrock Data Automation
In the benefits administration industry, claims processing is a vital operational pillar that makes sure employees and beneficiaries receive timely benefits, such as health, dental, or disability payments, while controlling costs and adhering to regulations like HIPAA and ERISA. In this post, we examine the typical benefit claims processing workflow and identify where generative AI-powered automation can deliver the greatest impact.
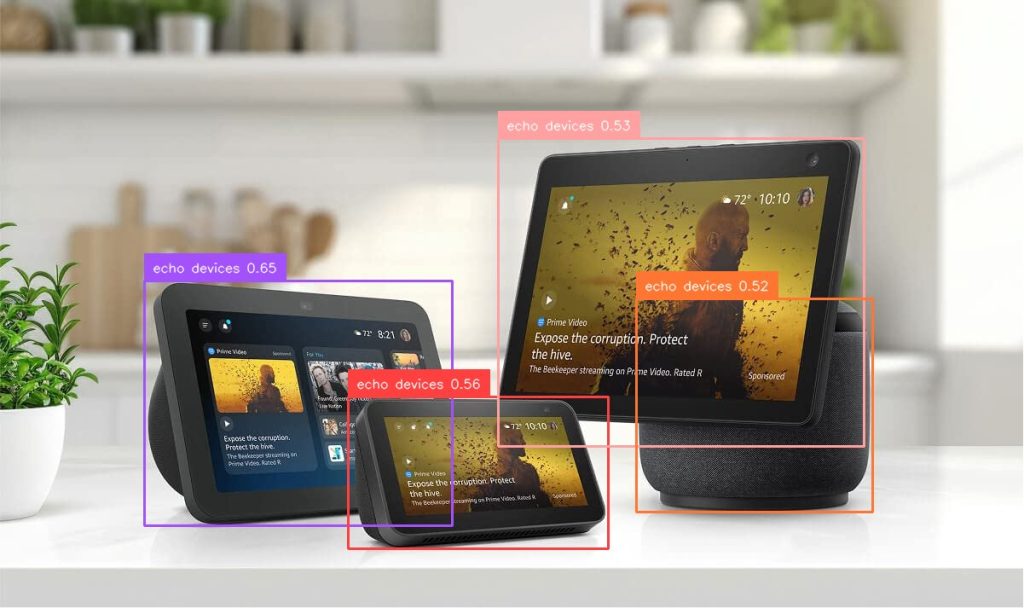
Enhance video understanding with Amazon Bedrock Data Automation and open-set object detection
In real-world video and image analysis, businesses often face the challenge of detecting objects that weren’t part of a model’s original training set. This becomes especially difficult in dynamic environments where new, unknown, or user-defined objects frequently appear. In this post, we explore how Amazon Bedrock Data Automation uses OSOD to enhance video understanding.
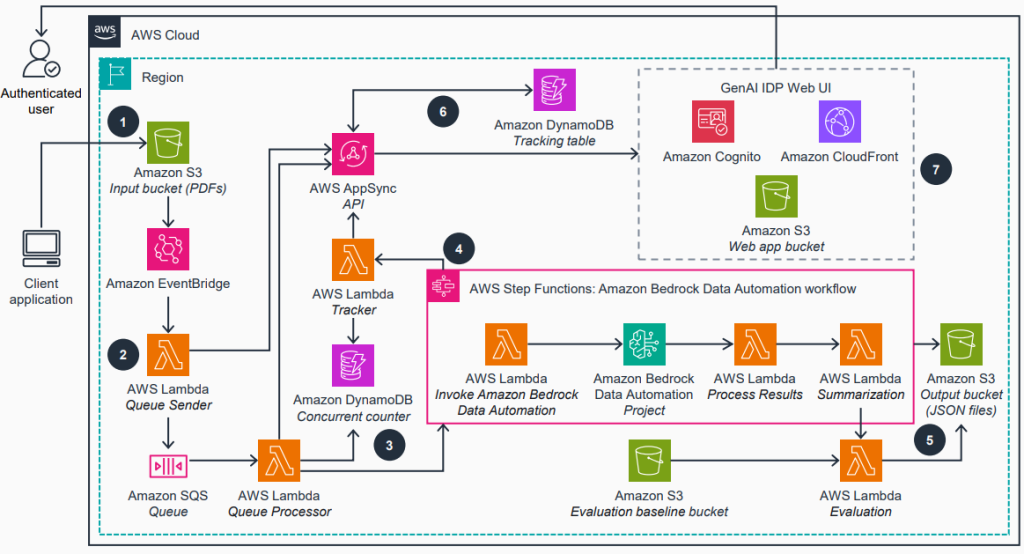
Accelerate intelligent document processing with generative AI on AWS
In this post, we introduce our open source GenAI IDP Accelerator—a tested solution that we use to help customers across industries address their document processing challenges. Automated document processing workflows accurately extract structured information from documents, reducing manual effort. We will show you how this ready-to-deploy solution can help you build those workflows with generative AI on AWS in days instead of months.
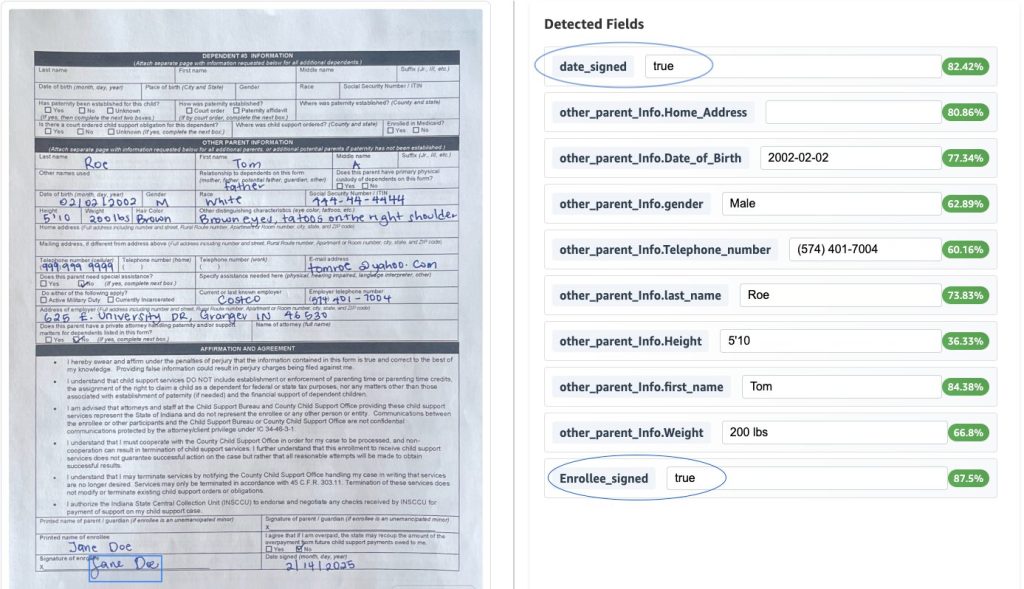
Scalable intelligent document processing using Amazon Bedrock Data Automation
In the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey.

Whiteboard to cloud in minutes using Amazon Q, Amazon Bedrock Data Automation, and Model Context Protocol
We’re excited to share the Amazon Bedrock Data Automation Model Context Protocol (MCP) server, for seamless integration between Amazon Q and your enterprise data. In this post, you will learn how to use the Amazon Bedrock Data Automation MCP server to securely integrate with AWS Services, use Bedrock Data Automation operations as callable MCP tools, and build a conversational development experience with Amazon Q.

Process multi-page documents with human review using Amazon Bedrock Data Automation and Amazon SageMaker AI
In this post, we show how to process multi-page documents with a human review loop using Amazon Bedrock Data Automation and Amazon SageMaker AI.