Artificial Intelligence
Category: Amazon SageMaker

Accelerate your model training with managed tiered checkpointing on Amazon SageMaker HyperPod
AWS announced managed tiered checkpointing in Amazon SageMaker HyperPod, a purpose-built infrastructure to scale and accelerate generative AI model development across thousands of AI accelerators. Managed tiered checkpointing uses CPU memory for high-performance checkpoint storage with automatic data replication across adjacent compute nodes for enhanced reliability. In this post, we dive deep into those concepts and understand how to use the managed tiered checkpointing feature.

Maximize HyperPod Cluster utilization with HyperPod task governance fine-grained quota allocation
We are excited to announce the general availability of fine-grained compute and memory quota allocation with HyperPod task governance. With this capability, customers can optimize Amazon SageMaker HyperPod cluster utilization on Amazon Elastic Kubernetes Service (Amazon EKS), distribute fair usage, and support efficient resource allocation across different teams or projects. For more information, see HyperPod task governance best […]
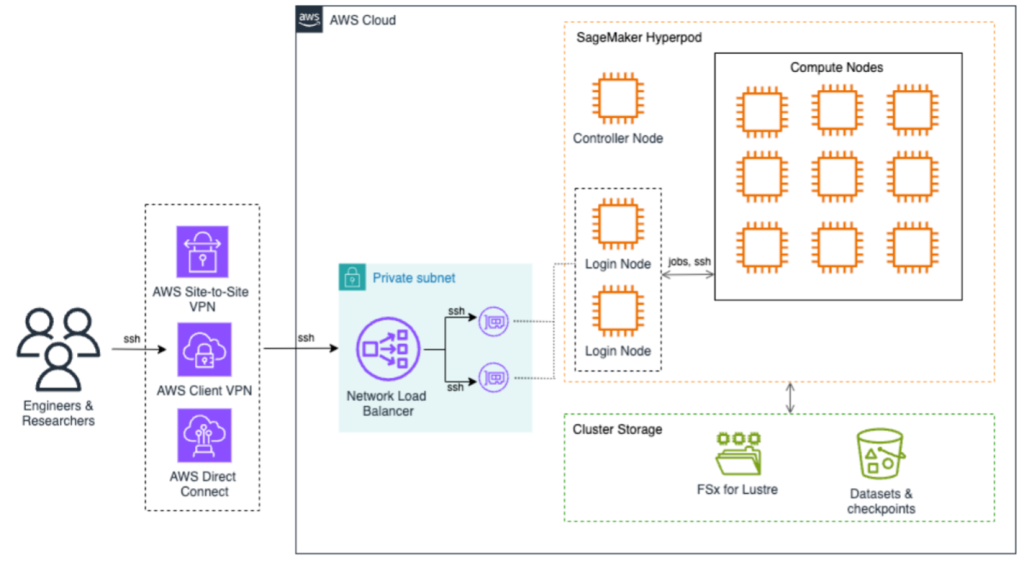
Accelerating HPC and AI research in universities with Amazon SageMaker HyperPod
In this post, we demonstrate how a research university implemented SageMaker HyperPod to accelerate AI research by using dynamic SLURM partitions, fine-grained GPU resource management, budget-aware compute cost tracking, and multi-login node load balancing—all integrated seamlessly into the SageMaker HyperPod environment.

Train and deploy models on Amazon SageMaker HyperPod using the new HyperPod CLI and SDK
In this post, we demonstrate how to use the new Amazon SageMaker HyperPod CLI and SDK to streamline the process of training and deploying large AI models through practical examples of distributed training using Fully Sharded Data Parallel (FSDP) and model deployment for inference. The tools provide simplified workflows through straightforward commands for common tasks, while offering flexible development options through the SDK for more complex requirements, along with comprehensive observability features and production-ready deployment capabilities.
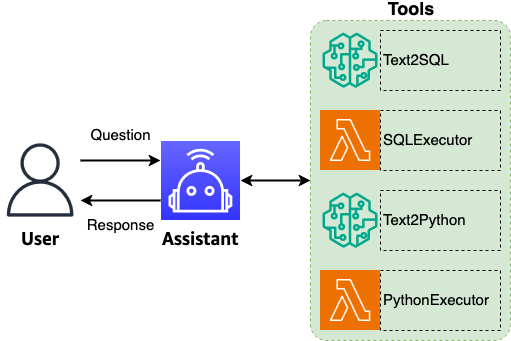
Natural language-based database analytics with Amazon Nova
In this post, we explore how natural language database analytics can revolutionize the way organizations interact with their structured data through the power of large language model (LLM) agents. Natural language interfaces to databases have long been a goal in data management. Agents enhance database analytics by breaking down complex queries into explicit, verifiable reasoning steps and enabling self-correction through validation loops that can catch errors, analyze failures, and refine queries until they accurately match user intent and schema requirements.

Document intelligence evolved: Building and evaluating KIE solutions that scale
In this blog post, we demonstrate an end-to-end approach for building and evaluating a KIE solution using Amazon Nova models available through Amazon Bedrock. This end-to-end approach encompasses three critical phases: data readiness (understanding and preparing your documents), solution development (implementing extraction logic with appropriate models), and performance measurement (evaluating accuracy, efficiency, and cost-effectiveness). We illustrate this comprehensive approach using the FATURA dataset—a collection of diverse invoice documents that serves as a representative proxy for real-world enterprise data.

Announcing the new cluster creation experience for Amazon SageMaker HyperPod
With the new cluster creation experience, you can create your SageMaker HyperPod clusters, including the required prerequisite AWS resources, in one click, with prescriptive default values automatically applied. In this post, we explore the new cluster creation experience for Amazon SageMaker HyperPod.

Introducing auto scaling on Amazon SageMaker HyperPod
In this post, we announce that Amazon SageMaker HyperPod now supports managed node automatic scaling with Karpenter, enabling efficient scaling of SageMaker HyperPod clusters to meet inference and training demands. We dive into the benefits of Karpenter and provide details on enabling and configuring Karpenter in SageMaker HyperPod EKS clusters.
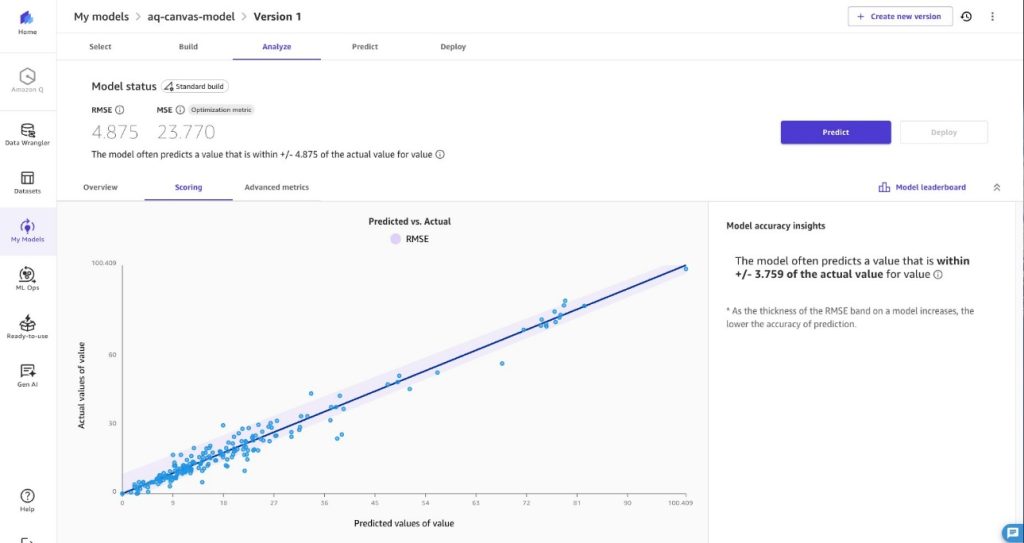
Empowering air quality research with secure, ML-driven predictive analytics
In this post, we provide a data imputation solution using Amazon SageMaker AI, AWS Lambda, and AWS Step Functions. This solution is designed for environmental analysts, public health officials, and business intelligence professionals who need reliable PM2.5 data for trend analysis, reporting, and decision-making. We sourced our sample training dataset from openAFRICA. Our solution predicts PM2.5 values using time-series forecasting.
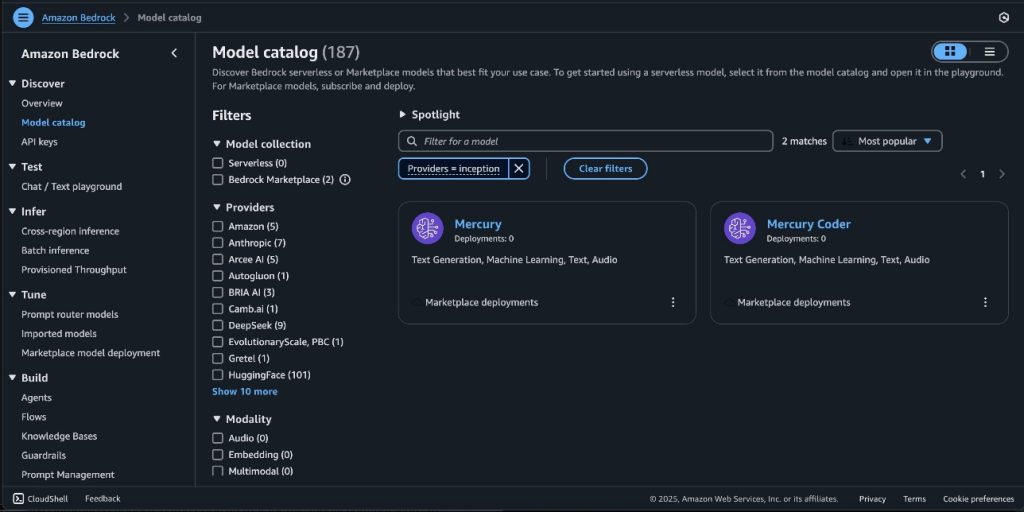
Mercury foundation models from Inception Labs are now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
In this post, we announce that Mercury and Mercury Coder foundation models from Inception Labs are now available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. We demonstrate how to deploy these ultra-fast diffusion-based language models that can generate up to 1,100 tokens per second on NVIDIA H100 GPUs, and showcase their capabilities in code generation and tool use scenarios.