Artificial Intelligence
Cisco uses Amazon SageMaker and Kubeflow to create a hybrid machine learning workflow
This is a guest post from members of Cisco’s AI/ML best practices team, including Technical Product Manager Elvira Dzhuraeva, Distinguished Engineer Debo Dutta, and Principal Engineer Amit Saha.
Cisco is a large enterprise company that applies machine learning (ML) and artificial intelligence (AI) across many of its business units. The Cisco AI team in the office of the CTO is responsible for the company’s open source (OSS) AI/ML best practices across the business units that use AI and ML, and is also a major contributor to the Kubeflow open-source project and MLPerf/MLCommons. Our charter is to create artifacts and best practices in ML that both Cisco business units and our customers can use, and we share these solutions as reference architectures.
Due to business needs, such as localized data requirements, Cisco operates a hybrid cloud environment. Model training is done on our own Cisco UCS hardware, but many of our teams leverage the cloud for inference to take advantage of the scalability, geo redundancy, and resiliency. However, such implementations may be challenging to customers, because hybrid integration often requires deep expertise and knowledge to build and support consistent AI/ML workflows.
To address this, we built an ML pipeline using the Cisco Kubeflow starter pack for a hybrid cloud implementation that uses Amazon SageMaker to serve models in the cloud. By providing this reference architecture, we aim to help customers build seamless and consistent ML workloads across their complex infrastructure to satisfy whatever limitations they may face.
Kubeflow is a popular open-source library for ML orchestration on Kubernetes. If you operate in a hybrid cloud environment, you can install the Cisco Kubeflow starter pack to develop, build, train, and deploy ML models on-premises. The starter pack includes the latest version of Kubeflow and an application examples bundle.
Amazon SageMaker is a managed ML service that helps you prepare data, process data, train models, track model experiments, host models, and monitor endpoints. With SageMaker Components for Kubeflow Pipelines, you can orchestrate jobs from Kubeflow Pipelines, which we did for our hybrid ML project. This approach lets us seamlessly use Amazon SageMaker managed services for training and inference from our on-premises Kubeflow cluster. Using Amazon SageMaker provides our hosted models with enterprise features such as automatic scaling, multi-model endpoints, model monitoring, high availability, and security compliance.
To illustrate how our use case works, we recreate the scenario using the publicly available BLE RSSI Dataset for Indoor Localization and Navigation dataset, which contains Bluetooth Low Energy (BLE) Received Signal Strength Indication (RSSI) measurements. The pipeline trains and deploys a model to predict the location of Bluetooth devices. The following steps outline how a Kubernetes cluster can interact with Amazon SageMaker for a hybrid solution. The ML model, written in Apache MXNet, is trained using Kubeflow running on Cisco UCS servers to satisfy our localized data requirements and then deployed to AWS using Amazon SageMaker.
The created and trained model is uploaded to Amazon Simple Storage Service (Amazon S3) and uses Amazon SageMaker endpoints for serving. The following diagram shows our end-to-end workflow.
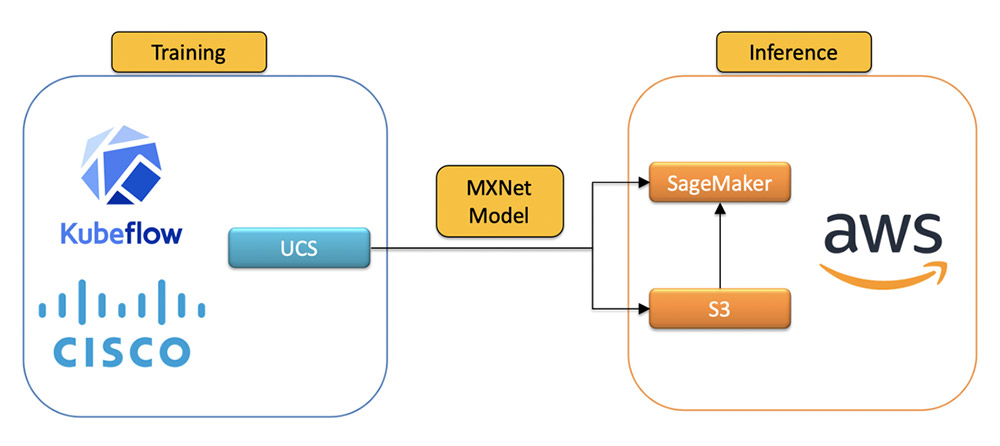
Development environment
To get started, if you don’t currently have Cisco hardware, you can set up Amazon Elastic Kubernetes Service (Amazon EKS) running with Kubeflow. For instructions, see Creating an Amazon EKS cluster and Deploying Kubeflow Pipelines.
If you have an existing UCS machine, the Cisco Kubeflow starter pack offers a quick Kubeflow setup on your Kubernetes cluster (v15.x or later). To install Kubeflow, set the INGRESS_IP variable with the machine’s IP address and run the kubeflowup.bash installation script. See the following code:
For more information about installation, see Installation Instructions on the GitHub repo.
Preparing the hybrid pipeline
For a seamless ML workflow between Cisco UCS and AWS, we created a hybrid pipeline using the Kubeflow Pipelines component and Amazon SageMaker Kubeflow components.
To start using the components you need to import Kubeflow Pipeline packages, including the AWS package:
For the full code to configure and get the pipeline running, see the GitHub repo.
The pipeline describes the workflow and how the components relate to each other in the form of a graph. The pipeline configuration includes the definition of the inputs (parameters) required to run the pipeline and the inputs and outputs of each component. The following screenshot shows the visual representation of the finished pipeline on the Kubeflow UI.
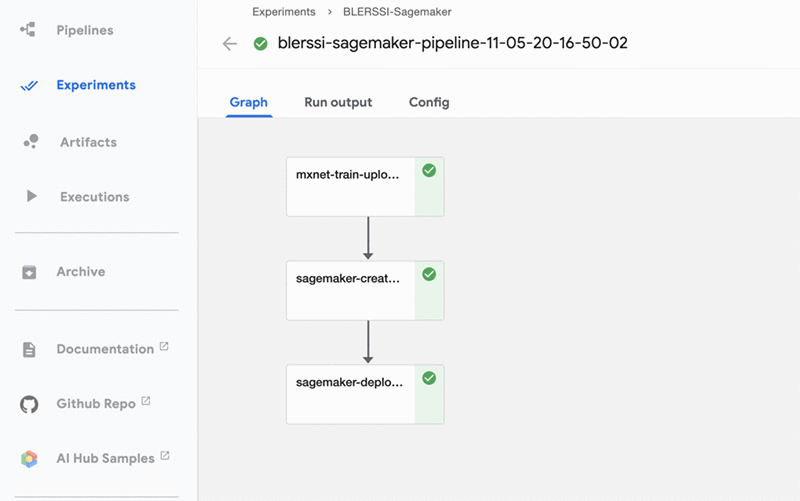
The pipeline runs the following three steps:
- Train the model
- Create the model resource
- Deploy the model
Training the model
You train the model with the BLE data locally, create an image, upload it to the S3 bucket, and register the model to Amazon SageMaker by applying the MXNet model configurations .yaml file.
When the trained model artifacts are uploaded to Amazon S3, Amazon SageMaker uses the model stored in Amazon S3 to deploy the model to a hosting endpoint. Amazon SageMaker endpoints make it easier for downstream applications to consume models and help the team monitor them with Amazon CloudWatch. See the following code:
Creating the model resource
When the MXNet model and artifacts are uploaded to Amazon S3, use the KF Pipeline CreateModel component to create an Amazon SageMaker model resource.
The Amazon SageMaker endpoint API is flexible and offers several options to deploy a trained model to an endpoint. For example, you can let the default Amazon SageMaker runtime manage the model deployment, health check, and model invocation. Amazon SageMaker also allows for customization to the runtime with custom containers and algorithms. For instructions, see Overview of containers for Amazon SageMaker.
For our use case, we wanted some degree of control over the model health check API and the model invocation API. We chose the custom override for the Amazon SageMaker runtime to deploy the trained model. The custom predictor allows for flexibility in how the incoming request is processed and passed along to the model for prediction. See the following code:
Deploying the model
You deploy the model to an Amazon SageMaker endpoint with the KF Pipeline CreateEndpoint component.
The custom container used for inference gives the team maximum flexibility to define custom health checks and invocations to the model. However, the custom container must follow the golden path for APIs prescribed by the Amazon SageMaker runtime. See the following code:
Running the pipeline
To run your pipeline, complete the following steps:
- Configure the Python code that defines the hybrid pipeline with Amazon SageMaker components:
For more information about configuration, see Pipelines Quickstart. For the full pipeline code, see the GitHub repo.
- Run the pipeline by feeding the following parameters to execute the pipeline:
At this point, the BLERSSI Amazon SageMaker pipeline starts executing. After all the components execute successfully, check the logs of the sagemaker-deploy component to verify that the endpoint is created. The following screenshot shows the logs of the last step with the URL to the deployed model.
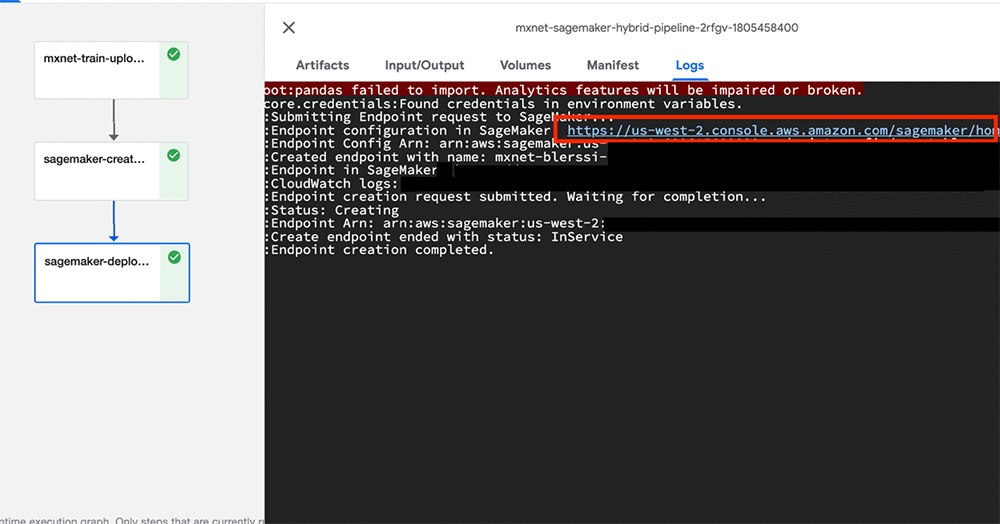
Validating the model
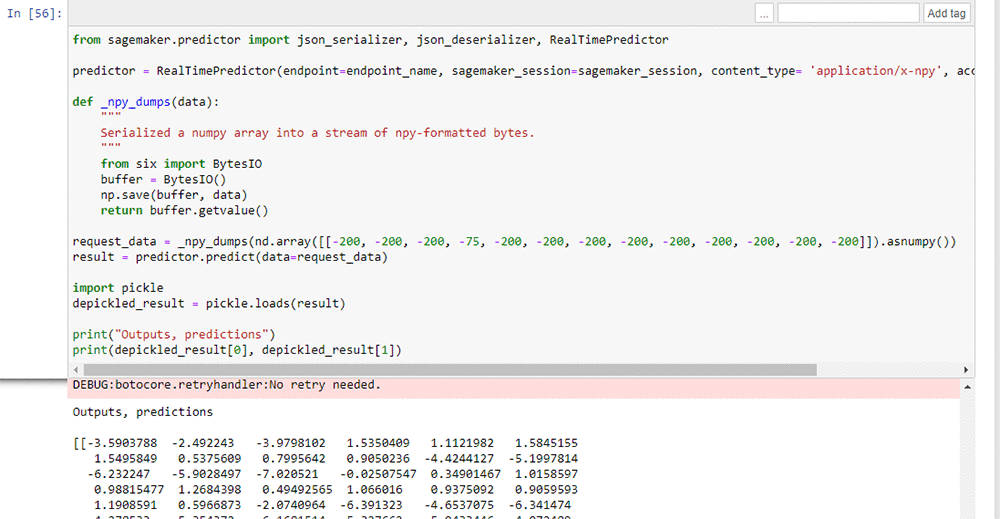
After the model is deployed in AWS, we validate it by submitting sample data to the model via an HTTP request using the endpoint name of the model deployed on AWS. The following screenshot shows a snippet from a sample Jupyter notebook that has a Python client and the corresponding output with location predictions.
Conclusion
Amazon SageMaker and Kubeflow Pipelines can easily integrate in one single hybrid pipeline. The complete set of blogs and tutorials for Amazon SageMaker makes it easy to create a hybrid pipeline via the Amazon SageMaker components for Kubeflow Pipelines. The API was exhaustive, covered all the key components we needed to use, and allowed for the development of custom algorithms and integration with the Cisco Kubeflow Starter Pack. By uploading a trained ML model to Amazon S3 to serve on AWS with Amazon SageMaker, we reduced the complexity and TCO of managing complex ML lifecycles by about 50%. We comply with the highest standards of enterprise policies in data privacy and serve models in a scalable fashion with redundancy on AWS all over the United States and the world.
About the Authors
Elvira Dzhuraeva is a Technical Product Manager at Cisco where she is responsible for cloud and on-premise machine learning and artificial intelligence strategy. She is also a Community Product Manager at Kubeflow and a member of MLPerf community.
Debo Dutta is a Distinguished Engineer at Cisco where he leads a technology group at the intersection of algorithms, systems and machine learning. While at Cisco, Debo is currently a visiting scholar at Stanford. He got his PhD in Computer Science from University of Southern California, and an undergraduate in Computer Science from IIT Kharagpur, India.
Amit Saha is a Principal Engineer at Cisco where he leads efforts in systems and machine learning. He is a visiting faculty at IIT Kharagpur. He has a PhD in Computer Science from Rice University, Houston and an undergraduate from IIT Kharagpur. He has served on several program committees for top Computer Science conferences.
 Phi Nguyen is a solution architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.
Phi Nguyen is a solution architect at AWS helping customers with their cloud journey with a special focus on data lake, analytics, semantics technologies and machine learning. In his spare time, you can find him biking to work, coaching his son’s soccer team or enjoying nature walk with his family.