Artificial Intelligence
Creating a multi-department enterprise search using custom attributes in Amazon Kendra
An enterprise typically houses multiple departments such as engineering, finance, legal, and marketing, creating a growing number of documents and content that employees need to access. Creating a search experience that intuitively delivers the right information according to an employee’s role, and the department is critical to driving productivity and ensuring security.
Amazon Kendra is a highly accurate and easy-to-use enterprise search service powered by machine learning. Amazon Kendra delivers powerful natural language search capabilities to your websites and applications. These capabilities help your end-users easily find the information they need within the vast amount of content spread across your company.
With Amazon Kendra, you can index the content from multiple departments and data sources into one Amazon Kendra index. To tailor the search experience by user role and department, you can add metadata to your documents and FAQs using Kendra’s built-in attributes and custom attributes and apply user context filters.
For search queries issued from a specific department’s webpage, you can set Kendra to only return content from that department filtered by the employee’s access level. For example, an associate role may only access a subset of restricted documents. In contrast, the department manager might have access to all the documents.
This post provides a solution to indexing content from multiple departments into one Amazon Kendra index. To manage content access, the organization can create restrictions based on an employee’s role and department or provide page-level filtering of search results. It demonstrates how content is filtered based on the web page location and individual user groups.
Solution architecture
The following architecture is comprised of two primary components: document ingestion into Amazon Kendra and document query using Amazon API Gateway.

The preceding diagram depicts a fictitious enterprise environment with two departments: Marketing and Legal. Each department has its own webpage on their internal website. Every department has two employee groups: associates and managers. Managers are entitled to see all the documents, but associates can only see a subset.
When employees from Marketing issue a search query on their department page, they only see the documents they are entitled to within their department (pink documents without the key). In contrast, the Marketing Manager sees all Marketing documents (all pink documents).
When employees from Legal search on a Marketing department page, they don’t see any documents. When all employees search on the internal website’s main page, they see the public documents common to all departments (yellow).
The following table shows the types of documents an employee gets for the various query combinations of webpage, department, and access roles.

Ingesting documents into Amazon Kendra
The document ingestion step consists of ingesting content and metadata from different departments’ specific S3 buckets, indexed by Amazon Kendra. Content can comprise structured data like FAQs and unstructured content like HTML, Microsoft PowerPoint, Microsoft Word, plain text, and PDF documents. For ingesting FAQ documents into Amazon Kendra, you can provide the questions, answers, and optional custom and access control attributes either in a CSV or JSON format.
You can add metadata to your documents and FAQs using the built-in attributes in Amazon Kendra, custom attributes, and user context filters. You can filter content using a combination of these custom attributes and user context filters. For this post, we index each document and FAQ with:
- Built-in attribute
_categoryto represent the web page. - User context filter attribute for the employee access level.
- Custom attribute
departmentrepresenting the employee department.
The following code is an example of the FAQ document for the Marketing webpage:
The following code is an example of the metadata document for the Legal webpage:
Document search by department
The search capability is exposed to the client application using an API Gateway endpoint. The API accepts an optional path parameter for the webpage on which the query was issued. If the query comes from the Marketing-specific page, the query looks like /search/dept/marketing. For a comprehensive website search covering all the departments, you will leave out the path parameter. The query looks like /search. Every API request also has two header values: EMP_ROLE, representing the employee access level, and EMP_DEPT, representing the department name. In this post, we don’t describe how to authenticate users. We assume that you populate these two header values after authenticating the user with Amazon Cognito or your custom solutions.
The AWS Lambda function that serves the API Gateway parses the path parameters and headers and issues an Amazon Kendra query call with AttributeFilters set to the category name from the path parameter (if present), the employee access level, and department from the headers. Amazon Kendra returns the FAQs and documents for that particular category and filters them by the employee access level and department. The Lambda function constructs a response with these search results and sends the FAQ and document search results back to the client application.
Deploying the AWS CloudFormation template
- You can deploy this architecture using the provided AWS CloudFormation template in
us-east-1. Please click to get started.
![]()
- Choose Next.
- Provide a stack name and choose Next.
- In the Capabilities and transforms section, select all three check-boxes to provide acknowledgment to AWS CloudFormation to create IAM resources and expand the template.

- Choose Create stack.
This process might take 15 minutes or more to complete and creates the following resources:
- An Amazon Kendra index
- Three S3 buckets representing the departments: Legal, Marketing, and Public
- Three Amazon Kendra data sources that connect to the S3 buckets
- A Lambda function and an API Gateway endpoint that is called by the client application
After the CloudFormation template finishes deploying the above infrastructure, you will see the following Outputs.

API Key and Usage Plan
- The KendraQueryAPI will require an API key. The CloudFormation output
ApiGWKeyrefers to the name of the API key. Currently, this API key is associated with a usage plan that allows 2000 requests per month. - Click the link in the Value column corresponding to the Key
ApiGWKey. This will open the API Keys section of the API Gateway console. - Click Show next to the API key.
- Copy the API key. We will use this when testing the API.

- You can manage the usage plan by following the instructions on, Create, configure, and test usage plans with the API Gateway console.
- You can also add fine-grained authentication and authorization to your APIs. For more information on securing your APIs, you can follow instructions on Controlling and managing access to a REST API in API Gateway.
Uploading sample documents and FAQ
Add your documents and FAQs file to their corresponding S3 buckets. We’ve also provided you with some sample document files and sample FAQs file to download.
Upload all the document files whose file name prefix corresponds to the S3 buckets created as part of the CloudFormation. For example, all Marketing documents and their corresponding metadata files go into the kendra-blog-data-source-marketing-[STACK_NAME] bucket. Upload the FAQ document into to the kendra-blog-faqs-[STACK_NAME]bucket.
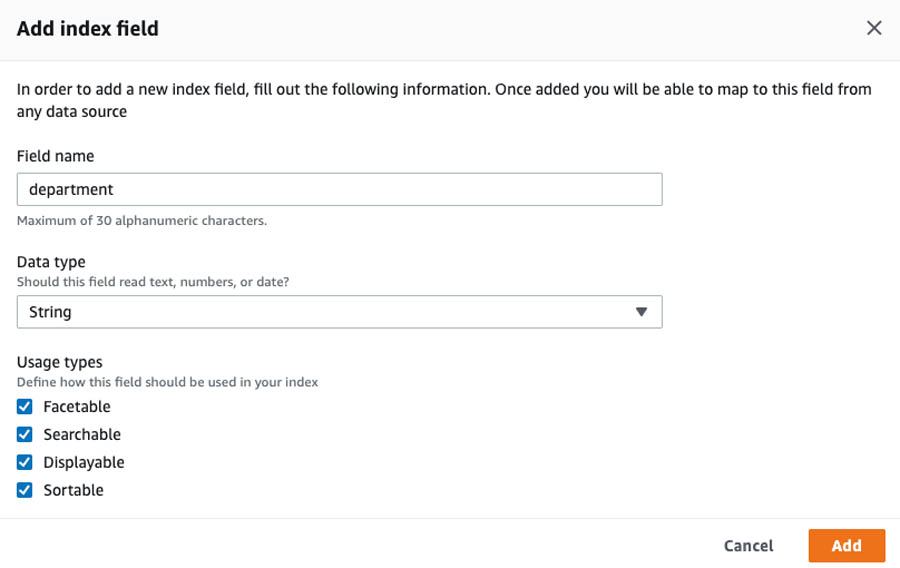
Creating the facet definition for custom attributes
In this step, you add a facet definition to the index.
- On the Amazon Kendra console, choose the index created in the previous step.
- Choose Facet definition.
- Choose the Add
- For Field name, enter
department. - For Data type, choose String.
- For Usage types, select Facetable, Searchable, Displayable, and Sortable.
- Choose Add.
- On the Amazon Kendra console, choose the newly created index.
- Choose Data sources.
- Sync
kendra-blog-data-source-legal-[STACK_NAME],kendra-blog-data-source-marketing-[STACK_NAME], andkendra-blog-data-source-public-[STACK_NAME]by selecting the data source name and choosing Sync now. You can sync multiple data sources simultaneously.
This should start the indexing process of the documents in the S3 buckets.
Adding FAQ documents
After you create your index, you can add your FAQ data.
- On the Amazon Kendra console, choose the new index.
- Choose FAQs.
- Choose Add FAQ.
- For FAQ name, enter a name, such as
demo-faqs-with-metadata. - For FAQ file format, choose JSON file.
- For S3, browse Amazon S3 to find
kendra-blog-faqs-[STACK_NAME], and choose thefaqs.jsonfile. - For IAM role, choose Create a new role to allow Amazon Kendra to access your S3 bucket.
- For Role name, enter a name, such as
AmazonKendra-blog-faq-role. - Choose Add.

Testing the solution
You can test the various combinations of page and user-level attributes on the API Gateway console. You can refer to Test a method with API Gateway console to learn about how to test your API using the API Gateway console.
The following screenshot is an example of testing the scenario where an associate from the Marketing department searches on the department-specific page.
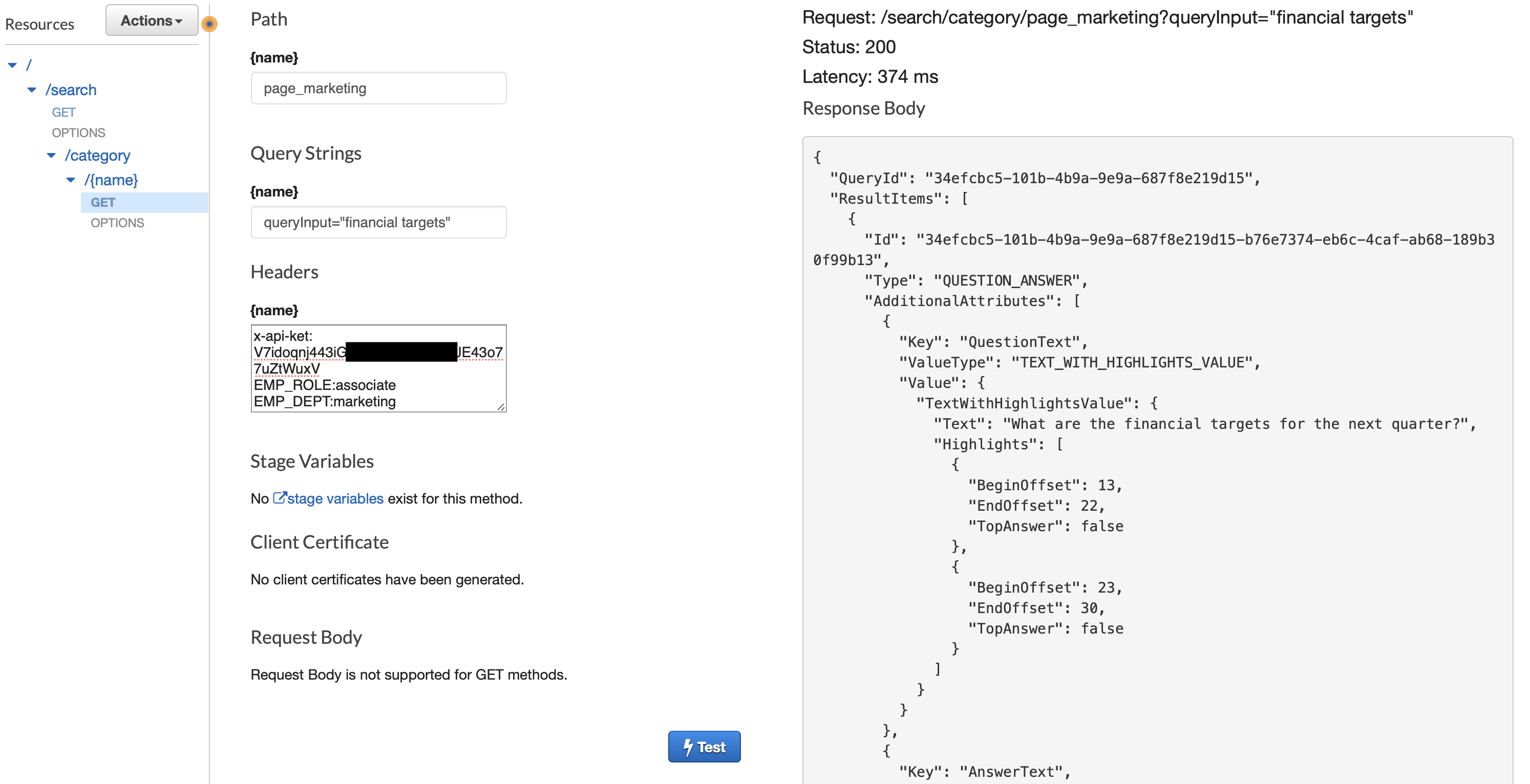
You will have to pass the following parameters while testing the above scenario.
- Path:
page_marketing - Query String:
queryInput="financial targets" - Headers:
x-api-key: << Your API Key copied earlier from the CloudFormation step >>EMP_ROLE:associateEMP_DEPT:marketing
You will see a JSON response with a FAQ result matching the above conditions.
You can keep the queryInput="financial targets" but change the EMP_ROLE from associate to manager, and you should see a different answer.
Cleaning up
To remove all resources created throughout this process and prevent additional costs, complete the following steps:
- Delete all the files from the S3 buckets.
- On the AWS CloudFormation console, delete the stack you created. This removes the resources the CloudFormation template created.
Conclusion
In this post, you learned how to use Amazon Kendra to deploy a cognitive search service across multiple departments in your organization and filter documents using custom attributes and user context filters. To enable, Amazon Kendra you don’t need to have any previous ML or AI experience. Use Amazon Kendra to provide your employees with faster access to information that is spread across your organization.
About the Authors
 Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with AI/ML strategy, architecture, and develop products with a purpose. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with AI/ML strategy, architecture, and develop products with a purpose. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
 Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.
Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.