Artificial Intelligence
Customizing and reusing models generated by Amazon SageMaker Autopilot
Amazon SageMaker Autopilot automatically trains and tunes the best machine learning (ML) models for classification or regression problems while allowing you to maintain full control and visibility. This not only allows data analysts, developers, and data scientists to train, tune, and deploy models with little to no code, but you can also review a generated notebook that outlines all the steps that Autopilot took to generate the model. In some cases, you might also want to customize pipelines generated by Autopilot with your own custom components.
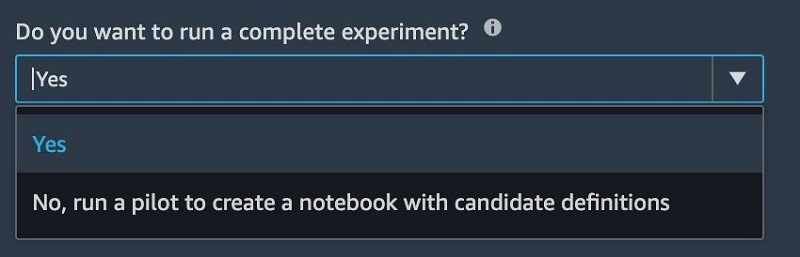
This post shows you how to create and use models with Autopilot in a couple of clicks, then outlines how to adapt the SageMaker Autopilot generated code with your own feature selectors and custom transformers to add domain-specific features. We also use the dry run capability of Autopilot, in which Autopilot only generates code for data preprocessors, algorithms, and algorithm parameter settings. This can be done by simply choosing the option run a pilot to create a notebook with candidate definitions.
Customizing Autopilot
Customizing Autopilot models is, in most cases, not necessary. Autopilot creates high-quality models that can be deployed without the need for customization. Autopilot automatically performs exploratory analysis of your data and decides which features may produce the best results. As such, it presents a low barrier of entry to ML for a wide range of users, from data analysts to developers, wishing to add AI/ML capabilities to their project.
However, more advanced users can take advantage of Autopilot’s transparent approach to AutoML to dramatically reduce the undifferentiated heavy lifting prevalent in ML projects. For example, you may want Autopilot to use custom feature transformations that your company uses, or custom imputation techniques that work better in the context of your data. You can preprocess your data before bringing it to SageMaker Autopilot, but that would involve going outside Autopilot and maintaining a separate preprocessing pipeline. Alternatively, you can use Autopilot’s data processing pipeline to direct Autopilot to use your custom transformations and imputations. The advantage to this approach is that you can focus on data collection, and let Autopilot do the heavy lifting to apply your desired feature transformations and imputations, and then find and deploy the best model.
Preparing your data and Autopilot job
Let’s start by creating an Autopilot experiment using the Forest Cover Type dataset.
- Download the dataset and upload it to Amazon Simple Storage Service (Amazon S3).
Make sure that you create your Amazon SageMaker Studio user in the same Region as the S3 bucket.
- Open SageMaker Studio.
- Create a job, providing the following information:
- Experiment name
- Training dataset location
- S3 bucket for saving Autopilot output data
- Type of ML problem
Your Autopilot job is now ready to run. Instead of running a complete experiment, we choose to let Autopilot generate a notebook with candidate definitions.

Inspecting the Autopilot-generated pipelines
SageMaker Autopilot automates the key tasks in an ML pipeline. It explores hundreds of models comprised of different features, algorithms, and hyperparameters to find the one that best fits your data. It also provides a leader board of 250 models so you can see how each model candidate performed and pick the best one to deploy. We explore this in more depth in the final section of this post.
When the experiment is complete, you can inspect your generated candidate pipelines. Candidate refers to the combination of data preprocessing steps and algorithm selection used to train the 250 models. The candidate generation notebook contains Python code that Autopilot used to generate these candidates.
- Choose Open candidate generation notebook.
- Open your notebook.
- Choose Import to import the notebook into your workspace.
- When prompted, choose Python 3 (Data Science) as the kernel.
- Inside the notebook, run all the cells in the SageMaker Setup
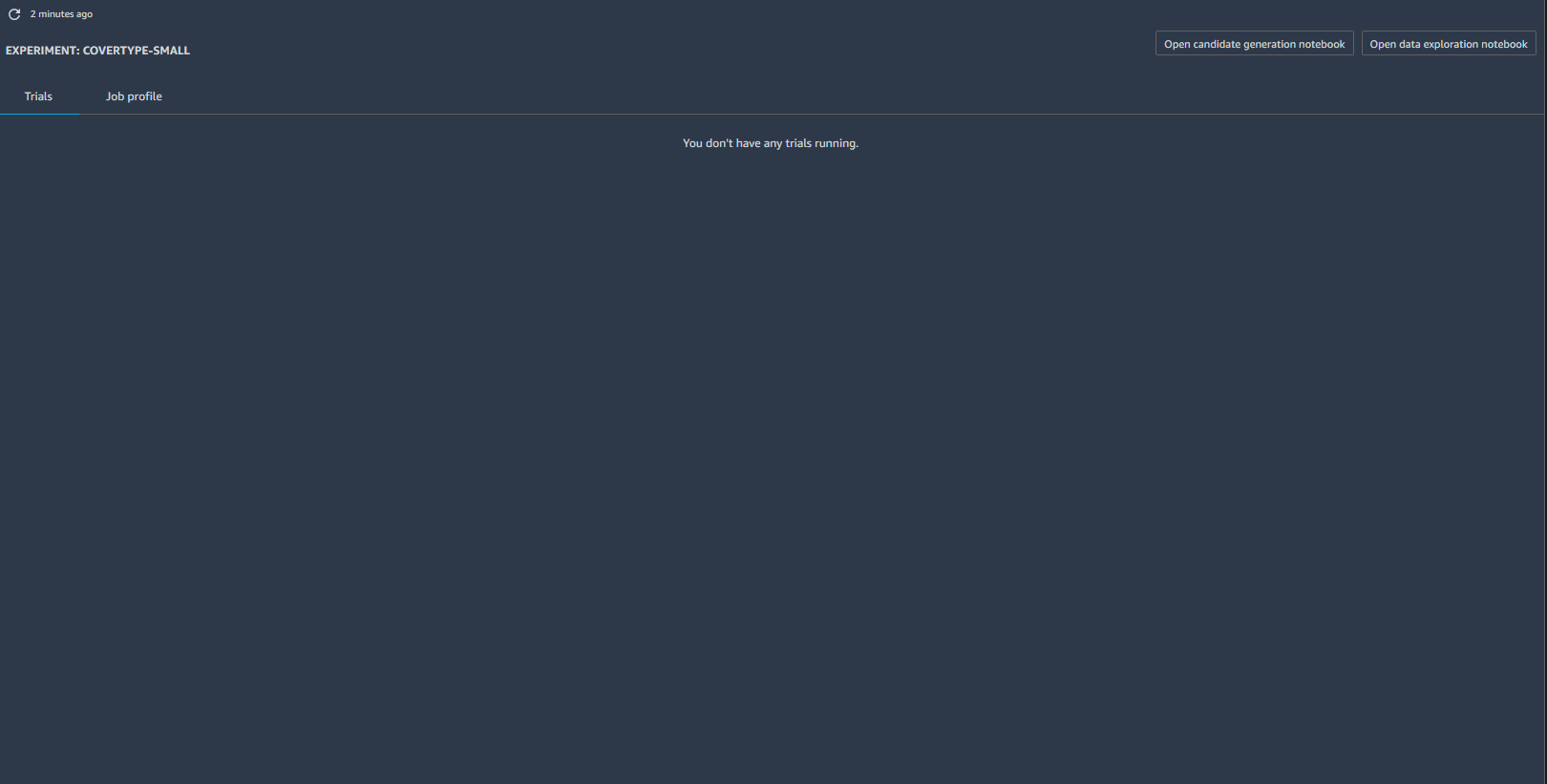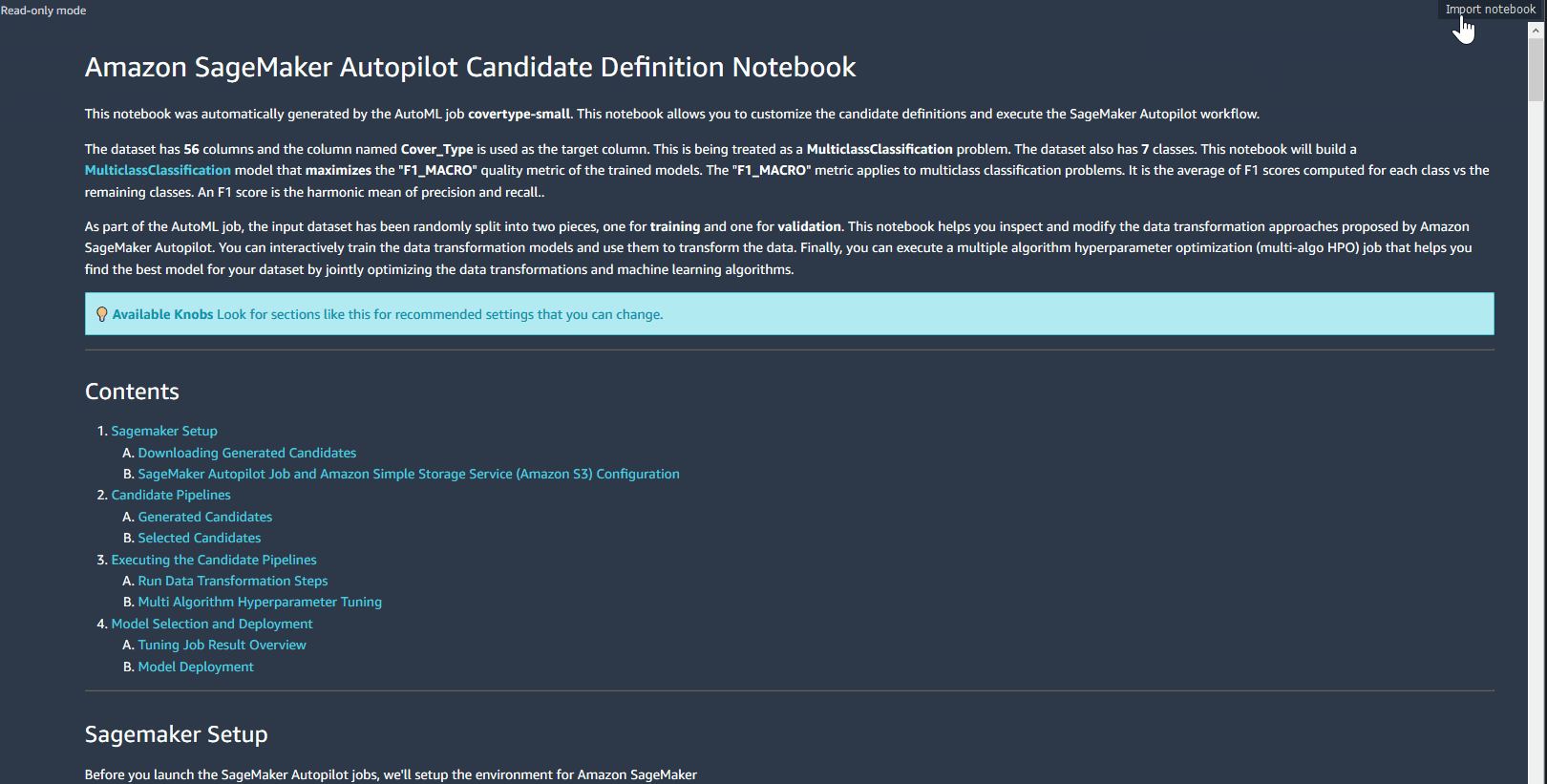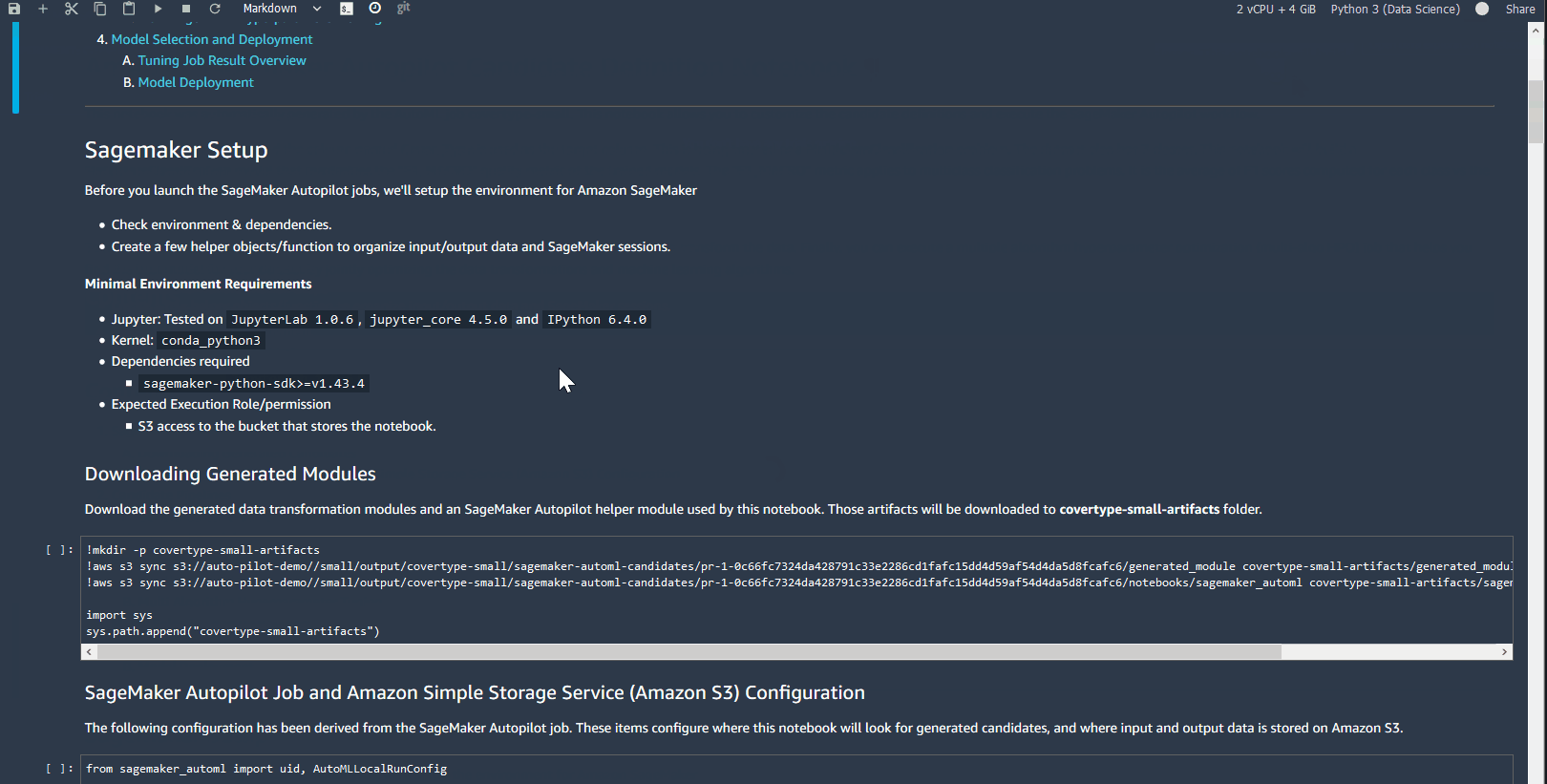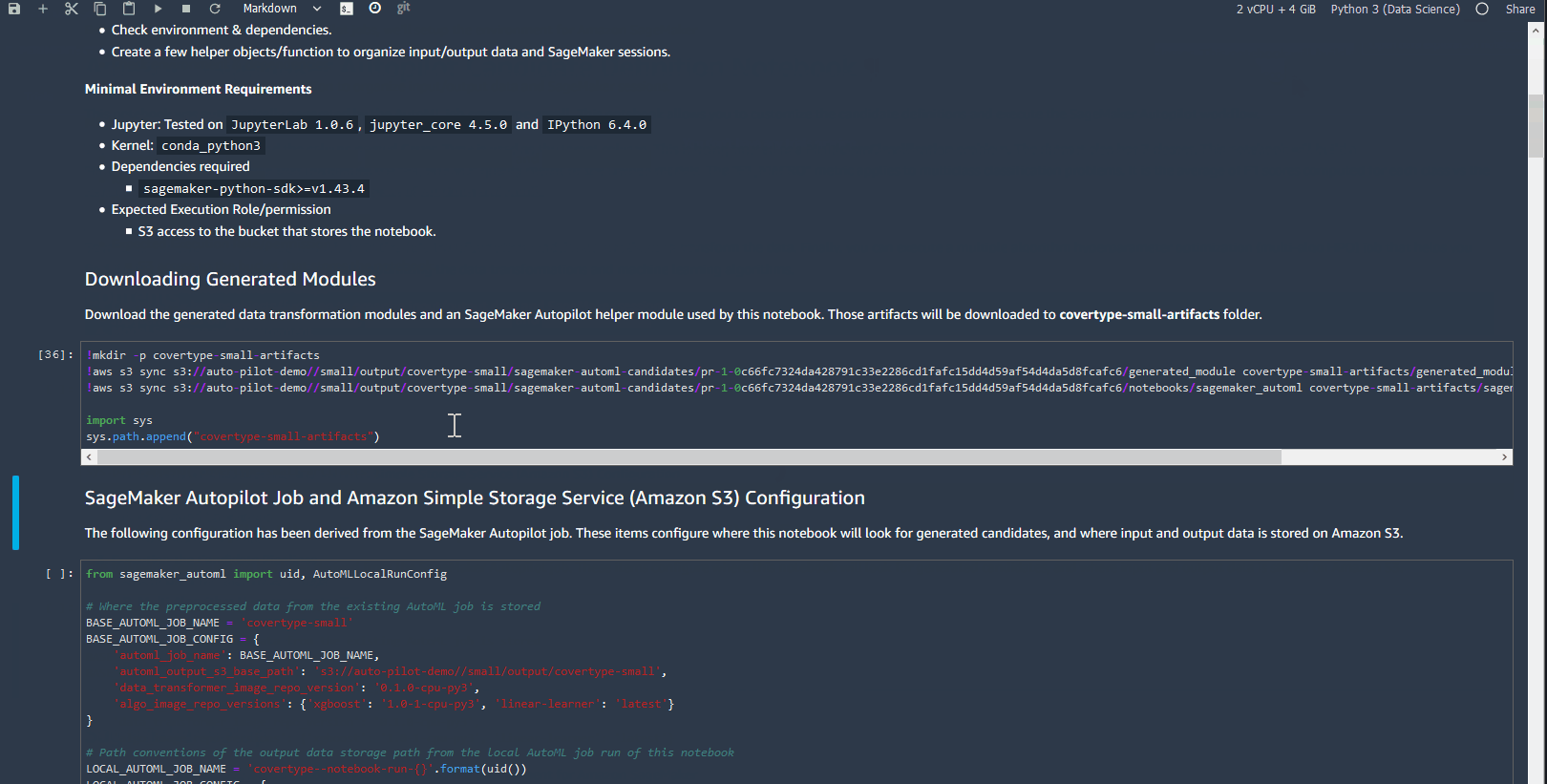
This copies the data preparation code that Autopilot generated into your workspace.
In your root SageMaker Studio directory, you should now see a folder with the name of your Autopilot experiment. The folder’s name should be <Your Experiment Name>–artifacts. That directory contains two sub-directories: generated_module and sagemaker_automl. The generated_module directory contains the data processing artifacts that Autopilot generated.
So far, the Autopilot job has analyzed the dataset and generated ML candidate pipelines that contain a set of feature transformers and an ML algorithm. Navigate down the generated_module folder to the candidate_data_processors directory, which contains 12 files:
- dpp0.py–dpp9.py – Data processing candidates that Autopilot generated
- trainer.py – Script that runs the data processing candidates
- sagemaker_serve.py – Script for running the preprocessing pipeline at inference time
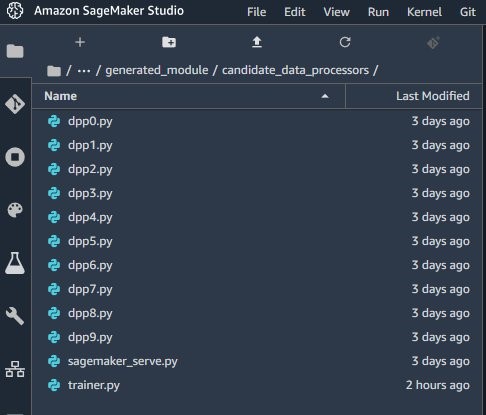
If you examine any of the dpp*.py files, you can observe that Autopilot generated code that builds sckit-learn pipelines, which you can easily extend with your own transformations. You can do this by either modifying the existing dpp*.py files directly or extending the pipelines after they’re instantiated in the trainer.py file, in which you define a transformer that can be called inside existing dpp*.py files. The second approach is recommended because it’s more maintainable and allows you to extend all the proposed processing pipelines at once as opposed to modifying each one individually.
Using specific transformers
You may wish to call a specific transformer from sckit-learn or use one implemented in the open-source package sagemaker-scikit-learn-extension. The latter provides a number of scikit-learn-compatible estimators and transformers that you can use. For instance, it implements the Weight of Evidence (WoE) encoder, an often-used encoding for categorical features in the context of binary classification.
To use additional transformers, first extend the import statements in the trainer.py file. For our use case, we add the following code:
If, upon modifying trainer.py, you encounter errors when running the notebook cell containing automl_interactive_runner.fit_data_transformers(...), you can get debugging information from Amazon CloudWatch under the log group /aws/sagemaker/TrainingJobs.
Implementing custom transformers
Going back to the forest cover type use case, we have features for the vertical and horizontal distance to hydrology. We want to extend this with an additional feature transform that calculates the straight line distance to hydrology. We can do this by adding an additional file into the candidate_data_processors directory where we define our custom transform. See the following code:
Inside the trainer.py file, we then import the additional_features module and add our HydrologyDistance transformer as a parallel pipeline to the existing generated ones.
In addition to our additional feature transformer, we also add a feature selector to our pipeline to select only the features with the highest importance as determined by a RandomForestClassifier:
Running inferences
Next we need to copy our additional_features.py file into the model directory to make it available at inference time. A serialize_code function is provided specifically for this. Modify the function as per the following example code to make sure that it’s included with the model artifact. The line of code that requires modification is highlighted.
Finally, we need to modify the model_fn function in sagemaker_serve.py to copy the additional_features.py file into the current working directory so that the scikit-learn pipeline can import the file at inference time:
When you finish all these steps, you can return to the candidate definition notebook and run the remaining cells. The additional transforms you defined are applied across all the selected data processing pipeline candidates and are also included in the inference pipeline.
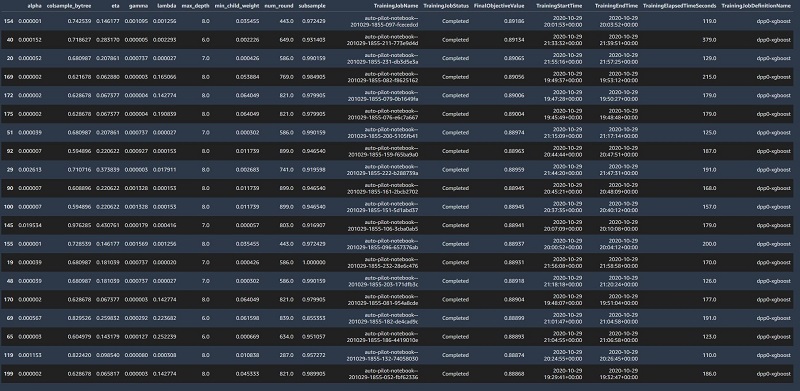
Deploying the best model
As Autopilot runs the candidate pipelines, it iterates over 250 combinations of processing pipelines, algorithm types, and model hyperparameters. When the process is complete, you can navigate to the final section of the notebook (Model Selection and Deployment) and view a leaderboard of the models Autopilot generated. Running the remaining notebook cells automatically deploys the model that produced the best results and exposes it as a RSET API endpoint.
Conclusions
In this post, we demonstrated how to customize an Autopilot training and inference pipeline with your own feature engineering code. We first let Autopilot generate candidate definitions without running the actual training and hyperparameter tuning. Then we implemented custom transformers that represent custom feature engineering that we want to bring to Autopilot. For more information about Autopilot, see Amazon SageMaker Autopilot.
About the Authors
 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Piali Das is a Senior Software Engineer in the AWS SageMaker Autopilot team. She previously contributed to building SageMaker Algorithms. She enjoys scientific programming in general and has developed an interest in machine learning and distributed systems.
Piali Das is a Senior Software Engineer in the AWS SageMaker Autopilot team. She previously contributed to building SageMaker Algorithms. She enjoys scientific programming in general and has developed an interest in machine learning and distributed systems.