Artificial Intelligence
Deploy Mistral AI’s Voxtral on Amazon SageMaker AI
Mistral AI’s Voxtral models combine text and audio processing capabilities in a single framework. The Voxtral family includes two distinct variants designed for different use cases and resource requirements. The Voxtral-Mini-3B-2507 is a compact 3-billion-parameter model optimized for efficient audio transcription and basic multimodal understanding, making it ideal for applications where speed and resource efficiency are priorities. The Voxtral-Small-24B-2507 is 24-billion-parameter model built on the Mistral Small 3 backbone that supports advanced chat capabilities, function calling directly from voice input, and complex audio-text intelligence, perfect for enterprise applications requiring nuanced understanding and multilingual audio processing. Both models support long-form audio context of up to 30–40 minutes, feature automatic language detection, and maintain a 32,000-token context length. They are released under the Apache 2.0 license, making them readily available for both commercial and research applications.
Voxtral models feature multimodal intelligence that processes spoken and written communication within a unified pipeline, alleviating the need for separate transcription and processing stages. The models demonstrate advanced audio understanding by extracting context and sentiment directly from audio inputs and can handle multiple audio files within single conversation threads. Voxtral Small includes function calling capabilities that convert audio inputs into executable tool calls. These capabilities enable applications such as contextual voice assistants, automated meeting transcription with insight extraction, intelligent call processing for customer service, accessibility tools, and multilingual communication systems for global organizations.
In this post, we demonstrate hosting Voxtral models on Amazon SageMaker AI endpoints using vLLM and the Bring Your Own Container (BYOC) approach. vLLM is a high-performance library for serving large language models (LLMs) that features paged attention for improved memory management and tensor parallelism for distributing models across multiple GPUs. The BYOC capability of SageMaker supports deployment with custom container images, providing precise version control for vLLM 0.10.0+ compatibility, optimization flexibility for Voxtral’s multimodal processing requirements (including specialized audio libraries and custom memory management), and support for both Voxtral-Mini and Voxtral-Small models through simple configuration updates.
Solution overview
In this solution, the SageMaker notebook environment serves as the central orchestration point for the entire deployment process. It manages the building and pushing of custom Docker images to Amazon Elastic Container Registry (Amazon ECR), handles model configuration and deployment workflows, and provides testing and validation capabilities to facilitate successful model deployment.
A key part of this solution is a custom Docker container that builds on the official vLLM server by adding specialized audio processing libraries (librosa, soundfile, pydub) and mistral_common for Voxtral tokenization, with everything set up to work seamlessly with the SageMaker BYOC approach. Amazon ECR provides secure storage and scalable distribution of this container image, integrating seamlessly with the SageMaker deployment mechanisms. The SageMaker inference endpoint serves as the production runtime where the Voxtral model is hosted, offering automatic scaling and load balancing with recommended instance types of ml.g6.4xlarge for Voxtral-Mini and ml.g6.12xlarge for Voxtral-Small deployments. Amazon Simple Storage Service (Amazon S3) completes the architecture by storing three critical files from our vLLM-BYOC implementation: the custom inference handler (model.py), model configuration (serving.properties), and dependencies (requirements.txt), creating a modular approach that separates configuration from container images to enable flexible model updates and configuration changes without container rebuilds, so teams can seamlessly switch between Voxtral-Mini and Voxtral-Small deployments by simply updating the serving.properties file.
The following diagram illustrates the solution architecture.
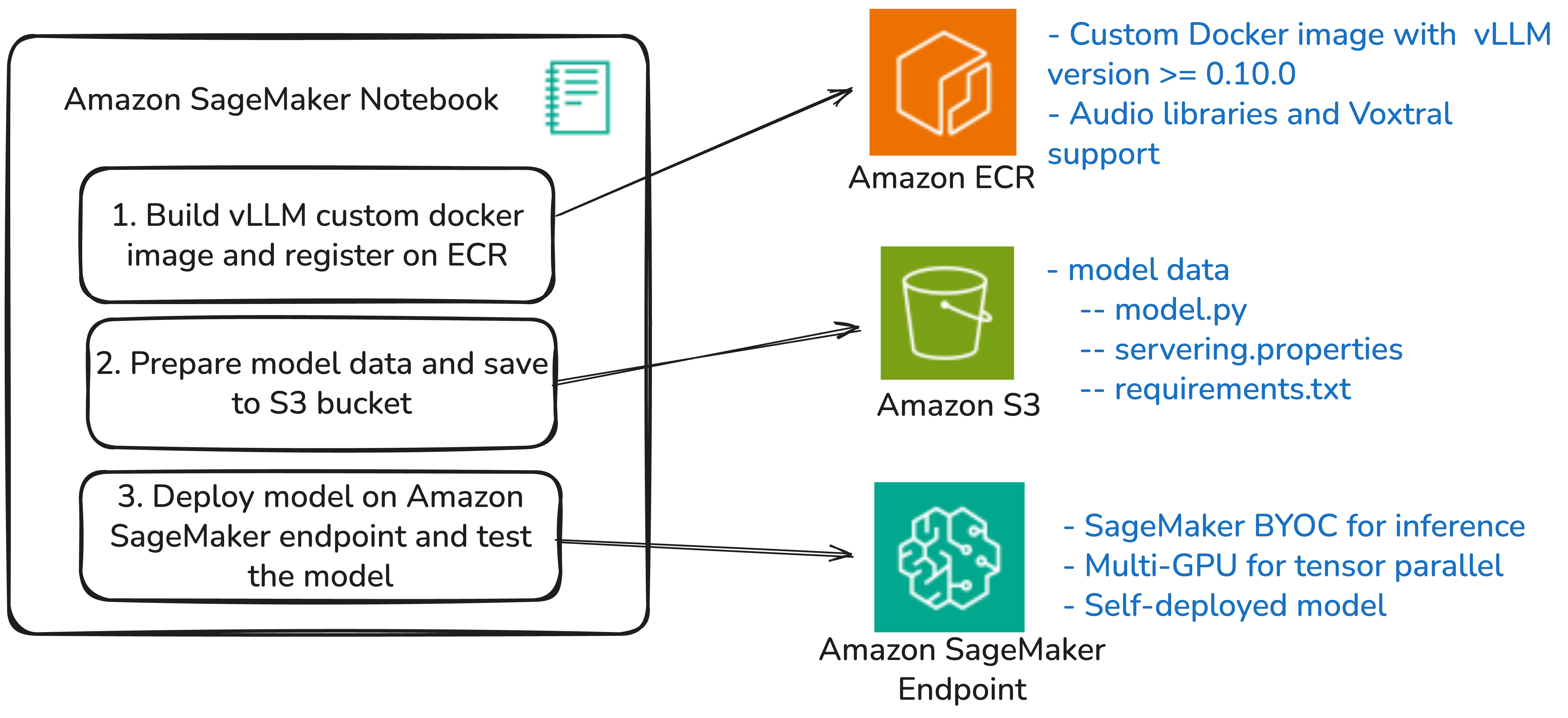
A three-step workflow diagram showing how to deploy Voxtral models on Amazon SageMaker using custom Docker containers, S3 storage, and multi-GPU endpoints.
The solution supports multiple use case patterns for different organizational needs. Text-only processing uses the standard chat completion API for traditional conversational AI where audio processing isn’t required. Transcription-only mode provides accurate audio file transcription, ideal for meeting notes or searchable audio archives. More sophisticated applications combine audio and text intelligence, where audio provides context while text delivers specific instructions, enabling voice-controlled applications with written clarifications. The advanced pattern involves function calling from audio inputs, where spoken commands directly trigger automated actions. For example, saying “Calculate the square root of 144” automatically executes the calculator tool and returns results, creating hands-free workflows.
This post also demonstrates integrating the Voxtral model deployed on SageMaker with Strands Agents to build agentic applications with minimal code.
The following sections provide a complete implementation guide to get your Voxtral model running on SageMaker endpoints.
Prerequisites
To get started, you must have the following prerequisites:
- The following software requirements:
- vLLM >= 0.10.0
- mistral_common >= 1.8.1
- AWS account setup, including:
- A SageMaker notebook using ml.m5.4xlarge with 100 GB storage.
- AWS Identity and Access Management (IAM) permissions. Add the EC2InstanceProfileForImageBuilderECRContainerBuilds policy to the SageMaker execution role.
- Service quotas: ml.g6.4xlarge (Voxtral-Mini) and ml.g6.12xlarge (Voxtral-Small) instances available. Refer to Requesting a quota increase to request a service quota increase in your account.
Deploy Voxtral models
Complete the following steps to quickly deploy and test Voxtral models:
- Download the code from the GitHub repo:
- Build your container:
- Configure your model in code/serving.properties:
- To deploy Voxtral-Mini, use the following code:
- To deploy Voxtral-Small, use the following code:
- Open and run Voxtral-vLLM-BYOC-SageMaker.ipynb to deploy your endpoint and test with text, audio, and function calling capabilities.
Docker container configuration
The GitHub repo contains the full Dockerfile. The following code snippet highlights the key parts:
This Dockerfile creates a specialized container that extends the official vLLM server with Voxtral-specific capabilities by adding essential audio processing libraries (
mistral_commonfor tokenization,librosa/soundfile/pydubfor audio handling) while configuring the proper SageMaker environment variables for model loading and caching. The approach separates infrastructure from business logic by keeping the container generic and allowing SageMaker to dynamically inject model-specific code (model.pyandserving.properties) from Amazon S3 at runtime, enabling flexible deployment of different Voxtral variants without requiring container rebuilds.Model configurations
The full model configurations are in the
serving.propertiesfile located in the code folder. The following code snippet highlights the key configurations:This configuration file provides Voxtral-specific optimizations that follow Mistral’s official recommendations for vLLM server deployment, setting up proper tokenization modes, audio processing parameters (supporting up to eight audio files per prompt with 30-minute transcription capability), and using the latest vLLM v0.10.0+ performance features like chunked prefill and prefix caching. The modular design supports seamless switching between Voxtral-Mini and Voxtral-Small by simply changing the
model_idandtensor_parallel_degreeparameters, while maintaining optimal memory utilization and enabling advanced caching mechanisms for improved inference performance.Custom inference handler
The full custom inference code is in the model.py file located in the code folder. The following code snippet highlights the key functions:
This custom inference handler creates a FastAPI-based server that directly integrates with the vLLM server for optimal Voxtral performance. The handler processes multimodal content including base64-encoded audio and audio URLs, dynamically loads model configurations from the
serving.propertiesfile, and supports advanced features like function calling for Voxtral-Small deployments.SageMaker deployment code
The Voxtral-vLLM-BYOC-SageMaker.ipynb notebook included in the
Voxtral-vllm-byocfolder orchestrates the entire deployment process for both Voxtral models:Model use cases
The Voxtral models support various text and speech-to-text use cases, and the Voxtral-Small model supports tool use with voice input. Refer to the GitHub repository for the complete code. In this section, we provide code snippets for different use cases that the model supports.
Text-only
The following code shows a basic text-based conversation with the model. The user sends a text query and receives a structured response:
Transcription-only
The following example focuses on speech-to-text transcription by setting temperature to 0 for deterministic output. The model processes an audio file URL or audio file converted to base64 code, then returns the transcribed text without additional interpretation:
Text and audio understanding
The following code combines both text instructions and audio input for multimodal processing. The model can follow specific text commands while analyzing the provided audio file in one inference pass, enabling more complex interactions like guided transcription or audio analysis tasks:
Tool use
The following code showcases function calling capabilities, where the model can interpret voice commands and execute predefined tools. The example demonstrates weather queries through voice input, with the model automatically calling the appropriate function and returning structured results:
Strands Agents integration
The following example shows how to integrate Voxtral with the Strands framework to create intelligent agents capable of using multiple tools. The agent can automatically select and execute appropriate tools (such as calculator, file operations, or shell commands from Strands prebuilt tools) based on user queries, enabling complex multi-step workflows through natural language interaction:
Clean up
When you finish experimenting with this example, delete the SageMaker endpoints that you created in the notebook to avoid unnecessary costs:
Conclusion
In this post, we demonstrated how to successfully self-host Mistral’s open source Voxtral models on SageMaker using the BYOC approach. We’ve created a production-ready system that uses the latest vLLM framework and official Voxtral optimizations for both Mini and Small model variants. The solution supports the full spectrum of Voxtral capabilities, including text-only conversations, audio transcription, sophisticated multimodal understanding, and function calling directly from voice input. With this flexible architecture, you can switch between Voxtral-Mini and Voxtral-Small models through simple configuration updates without requiring container rebuilds.
Take your multimodal AI applications to the next level by trying out the complete code from the GitHub repository to host the Voxtral model on SageMaker and start building your own voice-enabled applications. Explore Voxtral’s full potential by visiting Mistral’s official website to discover detailed capabilities, performance benchmarks, and technical specifications. Finally, explore the Strands Agents framework to seamlessly create agentic applications that can execute complex workflows.
About the authors
 Ying Hou, PhD, is a Sr. Specialist Solution Architect for GenAI at AWS, where she collaborates with model providers to onboard the latest and most intelligent AI models onto AWS platforms. With deep expertise in Gen AI, ASR, computer vision, NLP, and time-series forecasting models, she works closely with customers to design and build cutting-edge ML and GenAI applications.
Ying Hou, PhD, is a Sr. Specialist Solution Architect for GenAI at AWS, where she collaborates with model providers to onboard the latest and most intelligent AI models onto AWS platforms. With deep expertise in Gen AI, ASR, computer vision, NLP, and time-series forecasting models, she works closely with customers to design and build cutting-edge ML and GenAI applications.