Artificial Intelligence
Deploy multiple serving containers on a single instance using Amazon SageMaker multi-container endpoints
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models built on different frameworks. SageMaker real-time inference endpoints are fully managed and can serve predictions in real time with low latency.
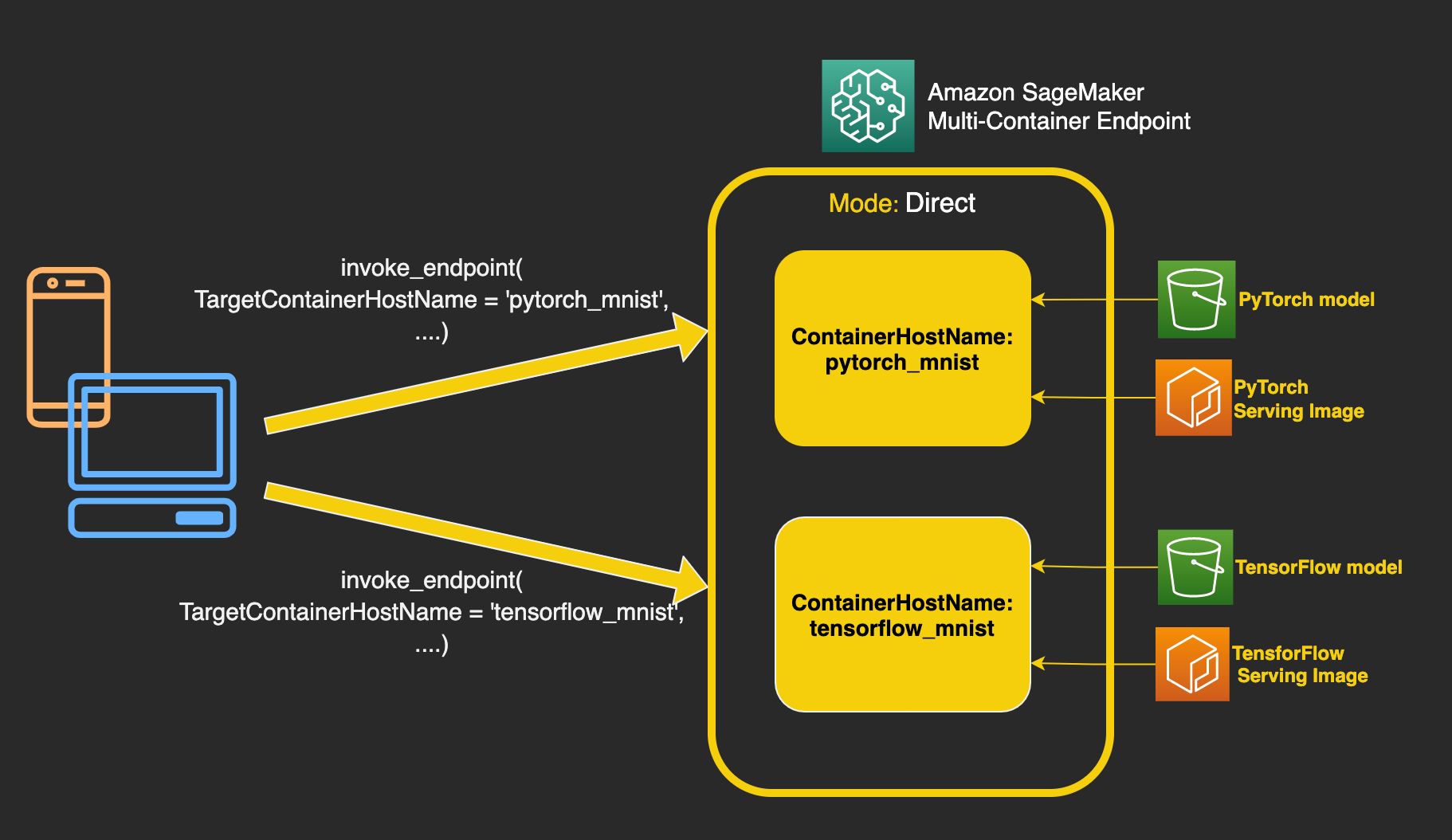
This post introduces SageMaker support for direct multi-container endpoints. This enables you to run up to 15 different ML containers on a single endpoint and invoke them independently, thereby saving up to 90% in costs. These ML containers can be running completely different ML frameworks and algorithms for model serving. In this post, we show how to serve TensorFlow and PyTorch models from the same endpoint by invoking different containers for each request and restricting access to each container.
SageMaker already supports deploying thousands of ML models and serving them using a single container and endpoint with multi-model endpoints. SageMaker also supports deploying multiple models built on different framework containers on a single instance, in a serial implementation fashion using inference pipelines.
Organizations are increasingly taking advantage of ML to solve various business problems and running different ML frameworks and algorithms for each use case. This pattern requires you to manage the challenges around deployment and cost for different serving stacks in production. These challenges become more pronounced when models are accessed infrequently but still require low-latency inference. SageMaker multi-container endpoints enable you to deploy up to 15 containers on a single endpoint and invoke them independently. This option is ideal when you have multiple models running on different serving stacks with similar resource needs, and when individual models don’t have sufficient traffic to utilize the full capacity of the endpoint instances.
Overview of SageMaker multi-container endpoints
SageMaker multi-container endpoints enable several inference containers, built on different serving stacks (such as ML framework, model server, and algorithm), to be run on the same endpoint and invoked independently for cost savings. This can be ideal when you have several different ML models that have different traffic patterns and similar resource needs.
Examples of when to utilize multi-container endpoints include, but are not limited to, the following:
- Hosting models across different frameworks (such as TensorFlow, PyTorch, and Sklearn) that don’t have sufficient traffic to saturate the full capacity of an instance
- Hosting models from the same framework with different ML algorithms (such as recommendations, forecasting, or classification) and handler functions
- Comparisons of similar architectures running on different framework versions (such as TensorFlow 1.x vs. TensorFlow 2.x) for scenarios like A/B testing
Requirements for deploying a multi-container endpoint
To launch a multi-container endpoint, you specify the list of containers along with the trained models that should be deployed on an endpoint. Direct inference mode informs SageMaker that the models are accessed independently. As of this writing, you’re limited to up to 15 containers on a multi-container endpoint and GPU inference is not supported due to resource contention. You can also run containers on multi-container endpoints sequentially as inference pipelines for each inference if you want to make preprocessing or postprocessing requests, or if you want to run a series of ML models in order. This capability is already supported as the default behavior of the multi-container endpoints and is selected by setting the inference mode to Serial.
After the models are trained, either through training on SageMaker or a bring-your-own strategy, you can deploy them on a multi-container endpoint using the SageMaker create_model, create_endpoint_config, and create_endpoint APIs. The create_endpoint_config and create_endpoint APIs work exactly the same way as they work for single model or container endpoints. The only change you need to make is in the usage of the create_model API. The following changes are required:
- Specify a dictionary of container definitions for the
Containersargument. This dictionary contains the container definitions of all the containers required to be hosted under the same endpoint. Each container definition must specify aContainerHostname. - Set the
Modeparameter ofInferenceExecutionConfigtoDirect, for direct invocation of each container, orSerial, for using containers in a sequential order (inference pipeline). The defaultModevalue isSerial.
Solution overview
In this post, we explain the usage of multi-container endpoints with the following steps:
- Train a TensorFlow and a PyTorch Model on the MNIST dataset.
- Prepare container definitions for TensorFlow and PyTorch serving.
- Create a multi-container endpoint.
- Invoke each container directly.
- Secure access to each container on a multi-container endpoint.
- View metrics for a multi-container endpoint
The complete code related to this post is available on the GitHub repo.
Dataset
The MNIST dataset contains images of handwritten digits from 0–9 and is a popular ML problem. The MNIST dataset contains 60,000 training images and 10,000 test images. This solution uses the MNIST dataset to train a TensorFlow and PyTorch model, which can classify a given image content as representing a digit between 0–9. The models give a probability score for each digit category (0–9) and the highest probability score is taken as the output.
Train TensorFlow and PyTorch models on the MNIST dataset
SageMaker provides built-in support for training models using TensorFlow and PyTorch. To learn how to train models on SageMaker, we recommend referring to the SageMaker documentation for training a PyTorch model and training a TensorFlow model, respectively. In this post, we use TensorFlow 2.3.1 and PyTorch 1.8.1 versions to train and host the models.
Prepare container definitions for TensorFlow and PyTorch serving
SageMaker has built-in support for serving these framework models, but under the hood TensorFlow uses TensorFlow Serving and PyTorch uses TorchServe. This requires launching separate containers to serve the two framework models. To use SageMaker pre-built Deep Learning Containers, see Available Deep Learning Containers Images. Alternatively, you can retrieve pre-built URIs through the SageMaker SDK. The following code snippet shows how to build the container definitions for TensorFlow and PyTorch serving containers.
- Create a container definition for TensorFlow:
Apart from ContainerHostName, specify the correct serving Image provided by SageMaker and also ModelDataUrl, which is an Amazon Simple Storage Service (Amazon S3) location where the model is present.
- Create the container definition for PyTorch:
For PyTorch container definition, an additional argument, Environment, is provided. It contains two keys:
- SAGEMAKER_PROGRAM – The name of the script containing the inference code required by the PyTorch model server
- SAGEMAKER_SUBMIT_DIRECTORY – The S3 URI of
tar.gzcontaining the model file (model.pth) and the inference script
Create a multi-container endpoint
The next step is to create a multi-container endpoint.
- Create a model using the
create_modelAPI:
Both the container definitions are specified under the Containers argument. Additionally, the InferenceExecutionConfig mode has been set to Direct.
- Create
endpoint_configurationusing thecreate_endpoint_configAPI. It specifies the sameModelNamecreated in the previous step:
- Create an endpoint using the
create_endpointAPI. It contains the same endpoint configuration created in the previous step:
Invoke each container directly
To invoke a multi-container endpoint with direct invocation mode, use invoke_endpoint from the SageMaker Runtime, passing a TargetContainerHostname argument that specifies the same ContainerHostname used while creating the container definition. The SageMaker Runtime InvokeEndpoint request supports X-Amzn-SageMaker-Target-Container-Hostname as a new header that takes the container hostname for invocation.
The following code snippet shows how to invoke the TensorFlow model on a small sample of MNIST data. Note the value of TargetContainerHostname:
Similarly, to invoke the PyTorch container, change the TargetContainerHostname to pytorch-mnist:
Apart from using different containers, each container invocation can also support a different MIME type.
For each invocation request to a multi-container endpoint set in direct invocation mode, only the container with TargetContainerHostname processes the request. Validation errors are raised if you specify a TargetContainerHostname that doesn’t exist inside the endpoint, or if you failed to specify a TargetContainerHostname parameter when invoking a multi-container endpoint.
Secure multi-container endpoints
For multi-container endpoints using direct invocation mode, multiple containers are co-located in a single instance by sharing memory and storage volume. You can provide users with the right access to the target containers. SageMaker uses AWS Identity and Access Management (IAM) roles to provide IAM identity-based policies that allow or deny actions.
By default, an IAM principal with InvokeEndpoint permissions on a multi-container endpoint using direct invocation mode can invoke any container inside the endpoint with the EndpointName you specify. If you need to restrict InvokeEndpoint access to a limited set of containers inside the endpoint you invoke, you can restrict InvokeEndpoint calls to specific containers by using the sagemaker:TargetContainerHostname IAM condition key, similar to restricting access to models when using multi-model endpoints.
The following policy allows InvokeEndpoint requests only when the value of the TargetContainerHostname field matches one of the specified regular expressions:
The following policy denies InvokeEndpont requests when the value of the TargetContainerHostname field matches one of the specified regular expressions of the Deny statement:
For information about SageMaker condition keys, see Condition Keys for Amazon SageMaker.
Monitor multi-container endpoints
For multi-container endpoints using direct invocation mode, SageMaker not only provides instance-level metrics as it does with other common endpoints, but also supports per-container metrics.
Per-container metrics for multi-container endpoints with direct invocation mode are located in Amazon CloudWatch metrics and are categorized into two namespaces: AWS/SageMaker and aws/sagemaker/Endpoints. The namespace of AWS/SageMaker includes invocation-related metrics, and the aws/sagemaker/Endpoints namespace includes per-container metrics of memory and CPU utilization.
The following screenshot of the AWS/SageMaker namespace shows per-container latency.

The following screenshot shows the aws/sagemaker/Endpoints namespace, which displays the CPU and memory utilization for each container.

For a full list of metrics, see Monitor Amazon SageMaker with Amazon CloudWatch.
Conclusion
SageMaker multi-container endpoints support deploying up to 15 containers on real-time endpoints and invoking them independently for low-latency inference and cost savings. The models can be completely heterogenous, with their own independent serving stack. You can either invoke these containers sequentially or independently for each request. Securely hosting multiple models, from different frameworks, on a single instance could save you up to 90% in cost.
To learn more, see Deploy multi-container endpoints and try out the example used in this post on the SageMaker GitHub examples repo.
About the Author
 Vikesh Pandey is a Machine Learning Specialist Specialist Solutions Architect at AWS, helping customers in the Nordics and wider EMEA region design and build ML solutions. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.
Vikesh Pandey is a Machine Learning Specialist Specialist Solutions Architect at AWS, helping customers in the Nordics and wider EMEA region design and build ML solutions. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.
 Sean Morgan is an AI/ML Solutions Architect at AWS. He previously worked in the semiconductor industry, using computer vision to improve product yield. He later transitioned to a DoD research lab where he specialized in adversarial ML defense and network security. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Addons.
Sean Morgan is an AI/ML Solutions Architect at AWS. He previously worked in the semiconductor industry, using computer vision to improve product yield. He later transitioned to a DoD research lab where he specialized in adversarial ML defense and network security. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Addons.