Artificial Intelligence
How Foxconn built an end-to-end forecasting solution in two months with Amazon Forecast
This is a guest post by Foxconn. The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
In their own words, “Established in Taiwan in 1974, Hon Hai Technology Group (Foxconn) is the world’s largest electronics manufacturer. Foxconn is also the leading technological solution provider and it continuously leverages its expertise in software and hardware to integrate its unique manufacturing systems with emerging technologies.”
At Foxconn, we manufacture some of the most widely used electronics worldwide. Our effectiveness comes from our ability to plan our production and staffing levels weeks in advance, while maintaining the ability to respond to short-term changes. For years, Foxconn has relied on predictable demand in order to properly plan and allocate resources within our factories. However, as the COVID-19 pandemic began, the demand for our products became more volatile. This increased uncertainty impacted our ability to forecast demand and estimate our future staffing needs.
This highlighted a crucial need for us to develop an improved forecasting solution that could be implemented right away. With Amazon Forecast and AWS, our team was able to build a custom forecasting application in only two months. With limited data science experience internally, we collaborated with the Machine Learning Solutions Lab at AWS to identify a solution using Forecast. The service makes AI-powered forecasting algorithms available to non-expert practitioners. Now we have a state-of-the-art solution that has improved demand forecasting accuracy by 8%, saving an estimated $553,000 annually. In this post, I show you how easy it was to use AWS services to build an application that fit our needs.
Forecasting challenges at Foxconn
Our factory in Mexico assembles and ships electronics equipment to all regions in North and South America. Each product has their own seasonal variations and requires different levels of complexity and skill to build. Having individual forecasts for each product is important to understand the mix of skills we need in our workforce. Forecasting short-term demand allows us to staff for daily and weekly production requirements. Long-term forecasts are used to inform hiring decisions aimed at meeting demand in the upcoming months.
If demand forecasts are inaccurate, it can impact our business in several ways, but the most critical impact for us is staffing our factories. Underestimating demand can result in understaffing and require overtime to meet production targets. Overestimating can lead to overstaffing, which is very costly because workers are underutilized. Both over and underestimating present different costs, and balancing these costs is crucial to our business.
Prior to this effort, we relied on forecasts provided by our customers in order to make these staffing decisions. With the COVID-19 pandemic, our demand became more erratic. This unpredictability caused over and underestimating demand to became more common and staffing related costs to increase. It became clear that we needed to find a better approach to forecasting.
Processing and modeling
Initially, we explored traditional forecasting methods such as ARIMA on our local machines. However, these approaches took a long time to develop, test, and tune for each product. It also required us to maintain a model for each individual product. From this experience, we learned that the new forecasting solution had to be fast, accurate, easy to manage, and scalable. Our team reached out to data scientists at the Amazon Machine Learning (ML) Solutions Lab, who advised and guided us through the process of building our solution around Forecast.
For this solution, we used a 3-year history of daily sales across nine different product categories. We chose these nine categories because they had a long history for the model to train on and exhibited different seasonal buying patterns. To begin, we uploaded the data from our on-premise servers into an Amazon Simple Storage Service (Amazon S3) bucket. After that, we preprocessed the data by removing known anomalies and organizing the data in a format compatible with Forecast. Our final dataset consisted of three columns: timestamp, item_id, and demand.
For model training, we decided to use the AutoML functionality in Forecast. The AutoML tool tries to fit several different algorithms to the data and tunes each one to obtain the highest accuracy. The AutoML feature was vital for a team like ours with limited background in time-series modeling. It only took a few hours for Forecast to train a predictor. After the service identifies the most effective algorithm, it further tunes that algorithm through hyperparameter optimization (HPO) to get the final predictor. This AutoML capability eliminated weeks of development time that the team would have spent researching, training, and evaluating various algorithms.
Forecast evaluation
After the AutoML finished training, it output results for a number of key performance metrics, including root mean squared error (RMSE) and weighted quantile loss (wQL). We chose to focus on wQL, which provides probabilistic estimates by evaluating the accuracy of the model’s predictions for different quantiles. A model with low wQL scores was important for our business because we face different costs associated with underestimating and overestimating demand. Based on our evaluations, the best model for our use case was CNN-QR.
We applied an additional evaluation step using a held-out test set. We combined the estimated forecast with internal business logic to evaluate how we would have planned staffing using the new forecast. The results were a resounding success. The new solution improved our forecast accuracy by 8%, saving an estimated $553,000 per year.
Application architecture
At Foxconn, much of our data resides on premises, so our application is a hybrid solution. The application loads the data to AWS from the on-premises server, builds the forecasts, and allows our team evaluate the output on a client-side GUI.
To ingest the data into AWS, we have a program running on premises that queries the latest data from the on-premises database on a weekly basis. It uploads the data to an S3 bucket via an SFTP server managed by AWS Transfer Family. This upload triggers an AWS Lambda function that performs the data preprocessing and loads the prepared data back into Amazon S3. The preprocessed data being written to the S3 bucket triggers two Lambda functions. The first loads the data from Amazon S3 into an OLTP database. The second starts the Forecast training on the processed data. After the forecast is trained, the results are loaded into a separate S3 bucket and also into the OLTP database. The following diagram illustrates this architecture.
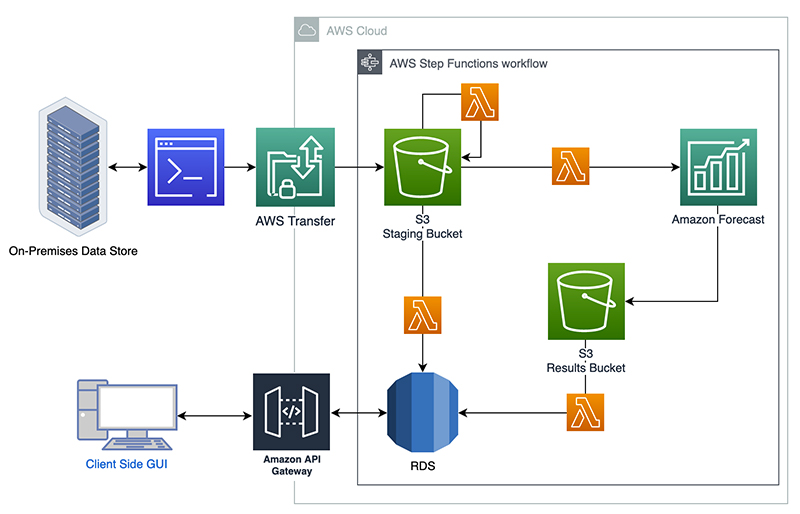
Finally, we wanted a way for customers to review the forecast outputs and provide their own feedback into the system. The team put together a GUI that uses Amazon API Gateway to allow users to visualize and interact with the forecast results in the database. The GUI allows the customer to review the latest forecast and choose a target production for upcoming weeks. The targets are uploaded back to the OLTP and used in further planning efforts.
Summary and next steps
In this post, we showed how a team new to AWS and data science built a custom forecasting solution with Forecast in 2 months. The application improved our forecast accuracy by 8%, saving an estimated $553,000 annually for our Mexico facility alone. Using Forecast also gave us the flexibility to scale out if we add new product categories in the future.
We’re thrilled to see the high performance of the Forecast solution using only the historical demand data. This is the first step in a larger plan to expand our use of ML for supply chain management and production planning.
Over the coming months, the team will migrate other planning data and workloads to the cloud. We’ll use the demand forecast in conjunction with inventory, backlog, and worker data to create an optimization solution for labor planning and allocation. These solutions will make the improved forecast even more impactful by allowing us to better plan production levels and resource needs.
If you’d like help accelerating the use of ML in your products and services, please contact the Amazon ML Solutions Lab program. To learn more about how to use Amazon Forecast, check out the service documentation.
About the Authors
 Azim Siddique serves as Technical Advisor and CoE Architect at Foxconn. He provides architectural direction for the Digital Transformation program, conducts PoCs with emerging technologies, and guides engineering teams to deliver business value by leveraging digital technologies at scale.
Azim Siddique serves as Technical Advisor and CoE Architect at Foxconn. He provides architectural direction for the Digital Transformation program, conducts PoCs with emerging technologies, and guides engineering teams to deliver business value by leveraging digital technologies at scale.
 Felice Chuang is a Data Architect at Foxconn. She uses her diverse skillset to implement end-to-end architecture and design for big data, data governance, and business intelligence applications. She supports analytic workloads and conducts PoCs for Digital Transformation programs.
Felice Chuang is a Data Architect at Foxconn. She uses her diverse skillset to implement end-to-end architecture and design for big data, data governance, and business intelligence applications. She supports analytic workloads and conducts PoCs for Digital Transformation programs.
 Yash Shah is a data scientist in the Amazon ML Solutions Lab, where he works on a range of machine learning use cases from healthcare to manufacturing and retail. He has a formal background in Human Factors and Statistics, and was previously part of the Amazon SCOT team designing products to guide 3P sellers with efficient inventory management.
Yash Shah is a data scientist in the Amazon ML Solutions Lab, where he works on a range of machine learning use cases from healthcare to manufacturing and retail. He has a formal background in Human Factors and Statistics, and was previously part of the Amazon SCOT team designing products to guide 3P sellers with efficient inventory management.
 Dan Volk is a Data Scientist at Amazon ML Solutions Lab, where he helps AWS customers across various industries accelerate their AI and cloud adoption. Dan has worked in several fields including manufacturing, aerospace, and sports and holds a Masters in Data Science from UC Berkeley.
Dan Volk is a Data Scientist at Amazon ML Solutions Lab, where he helps AWS customers across various industries accelerate their AI and cloud adoption. Dan has worked in several fields including manufacturing, aerospace, and sports and holds a Masters in Data Science from UC Berkeley.
 Xin Chen is a senior manager at Amazon ML Solutions Lab, where he leads Automotive Vertical and helps AWS customers across different industries identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin obtained his Ph.D. in Computer Science and Engineering from the University of Notre Dame.
Xin Chen is a senior manager at Amazon ML Solutions Lab, where he leads Automotive Vertical and helps AWS customers across different industries identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin obtained his Ph.D. in Computer Science and Engineering from the University of Notre Dame.