Artificial Intelligence
How Popsa used Amazon Nova to inspire customers with personalised title suggestions
This post was co-written with Bradley Grantham and Hugo Dugdale from Popsa.
Popsa is a technology company that helps users rediscover and relive the meaningful memories hidden in their photo libraries. Available across more than 50 countries and 12 languages, we use design automation and AI to transform everyday photos into personal, shareable experiences, including beautifully printed Photo Books.
In 2016, we released PrintAI, a pioneering algorithm to take complete control of creating a varied and interesting design from a user’s photos. Our customers could use the algorithm to create Photo Books that appeared professionally designed, in less than 5 minutes.
A core philosophy of our business is that technology should do the heavy lifting for our users, so automation has always been an intrinsic part of our product. In the current Generative AI age, we can develop even more ways to elevate our customers’ experience, without making our software more complicated to use.
In this post, we share how we applied Amazon Bedrock and the Amazon Nova family of models to reimagine our Title Suggestion feature. By combining metadata, computer vision, and retrieval-augmented generative AI, we now automatically generate creative, brand-aligned titles and subtitles across 12 languages. Using the unified API of Amazon Bedrock, Anthropic’s Claude 3 Haiku, and Amazon Nova Lite and Pro, we improved quality, reduced cost, and cut response times. This resulted in higher customer satisfaction, measurable uplifts in engagement and purchase rates, and over 5.5 million personalised titles generated in 2025.
Generating title suggestions with Amazon Bedrock
When a customer receives their Photo Book, the first thing they see is the front cover, with a prominent title and subtitle. A high-quality title and subtitle elevate a Photo Book’s design, however most customers aren’t professional copywriters and many of them settle for simple titles like “France 2024”, “Photos from Spain” or even, “Photos”.
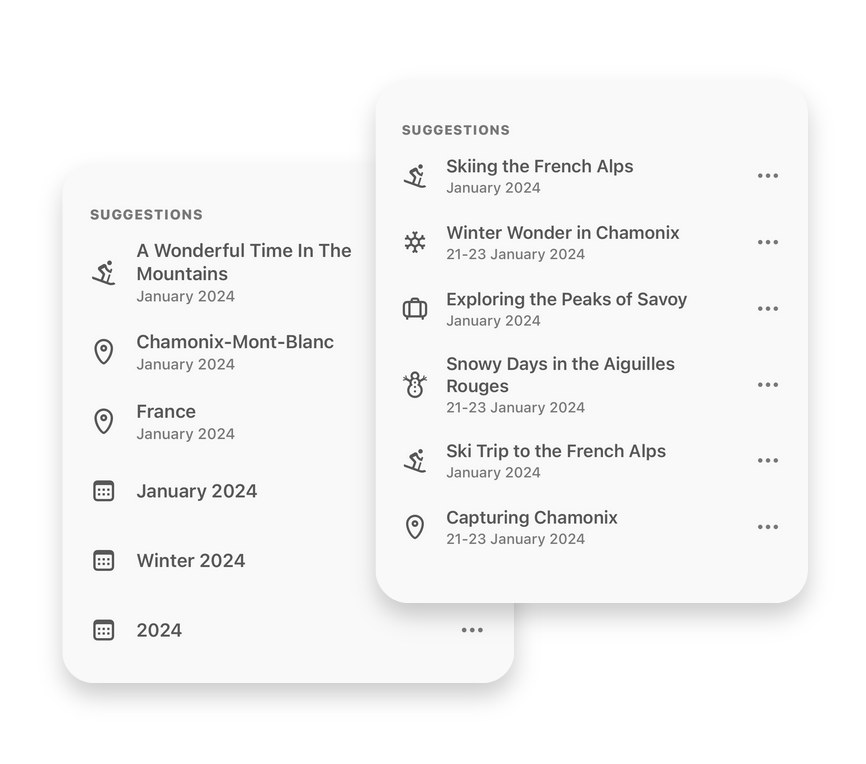
To help users elevate their photos, we developed and launched a feature called Title Suggestion, which has been available to our users since 2021.
When users select photos for a Photo Book design, our mobile app reads metadata—such as timestamps and geocoordinates—from the images and runs on-device convolutional neural networks to extract relevant features. For example, whether the image contains a beach, a barbecue, or a pet.
To use this data, we created an algorithm called Title Suggestion Graph. This algorithm used the metadata and data of the selected photos to build a list of possible titles, following a set of rules and templates to arrive at a set of suitable suggestions. For example:
If all photos in the design were taken on the same day
then suggest “On this Day” as a title with a subtitle of the specific date
In June 2024, we identified an opportunity to improve Title Suggestion by applying generative AI, with the aim of inspiring our users with more creative titles. We began by clearly defining the problem and establishing evaluation metrics.Our solution had to meet strict requirements:
- Character limit
- Both the title and subtitle must not exceed 36 characters due to layout restrictions affecting how the text would be displayed on a front cover.
- Title category
- Each title–subtitle pair must also have an associated category that determines the icon displayed alongside the pair to users. Imagined or incorrect categories would prevent an icon from being rendered.
- JSON format
- Finally, all outputs must be valid JSON with keys `title`, `subtitle` and `category`. This helped with consistent parsing, validation, and rendering in the app.
These rules helped with evaluation because they could be defined in code, so we built a dataset of over 100 example Photo Books and defined our metrics in an evaluation pipeline:
- % of title/subtitle suggestions within the character limit
- % of valid title categories
- % of responses in the correct JSON format
In addition to these strict rules, we needed our solution to satisfy some broader guidelines:
- Theme consistency
- Categories should match the content (for example, skiing icons wouldn’t be appropriate if the design subject was a beach holiday)
- Brand style
- Suggestions should reflect Popsa’s tone and brand identity
- Title-subtitle cohesion
- Pairs should complement each other; they shouldn’t be repetitive or disjointed.
- Multilingual quality
- Suggestions needed to be high quality in all 12 languages we support.
We decided to use an LLM-as-a-judge to evaluate performance against these guidelines. This helped us to rapidly test different models, prompts, and methods to identify the most reliable approach. After narrowing to two or three options, we conducted extensive internal testing.
Our top results came from Retrieval-based few-shot prompting. We created a database of example Photo Books and acceptable title suggestions. For a new Photo Book, we retrieved a few similar Photo Book designs and a random selection of their suggested titles.
Using Amazon Bedrock and Anthropic’s Claude 3 Haiku, we seeded the conversation with these examples as <user> – <assistant> messages before appending the user’s new design document as the final <user> message. This allowed the large language model (LLM) to emulate prior responses while naturally following the rules that we defined.
Our full architecture for this solution can be seen in the following diagram:
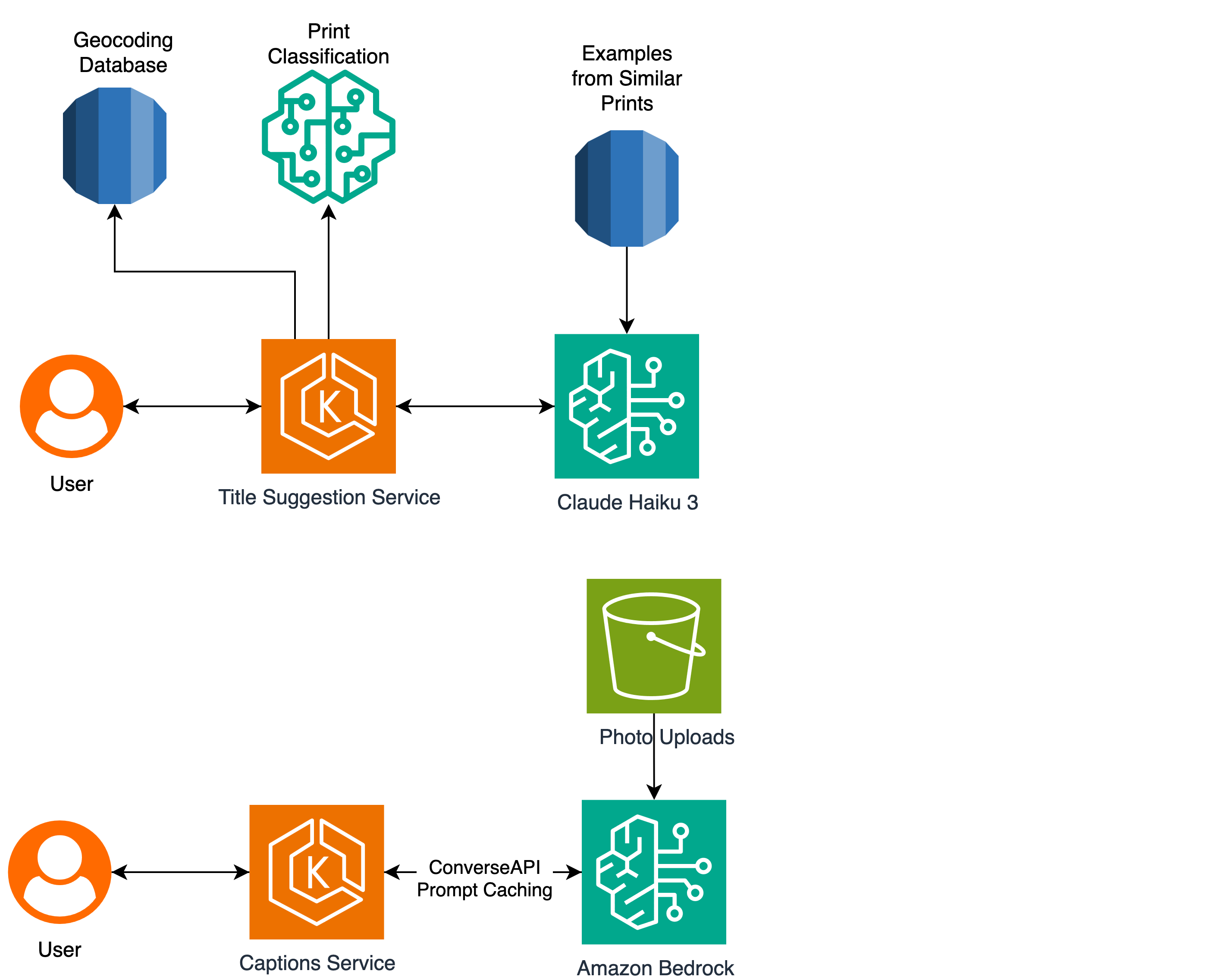
When our Title Suggestion Service receives a request, it first decrypts and processes the user’s design to extract the timestamps. Then, it performs a reverse geocoding operation on any latitudes and longitudes included in the design, and then classifies the subject of the design based on object landmarks.
This generates a description like “A skiing photobook with 21 photos taken in the Alps between 21st January 2025 and 23rd January 2025”. We then pass this description to our retrieval-based few-shot prompting component to produce a final set of user-facing suggestions.
Comparisons to our previous graph-based method show better results:
To quantify improvements, we relied on a feedback loop, where customers rated suggestions as positive, neutral, or negative. We also conducted multivariate testing with hundreds of thousands of users. Feedback strongly favored generative AI titles, and key metrics like Design Created and Purchase also improved. After several months, we rolled the feature out to 100% of our users.
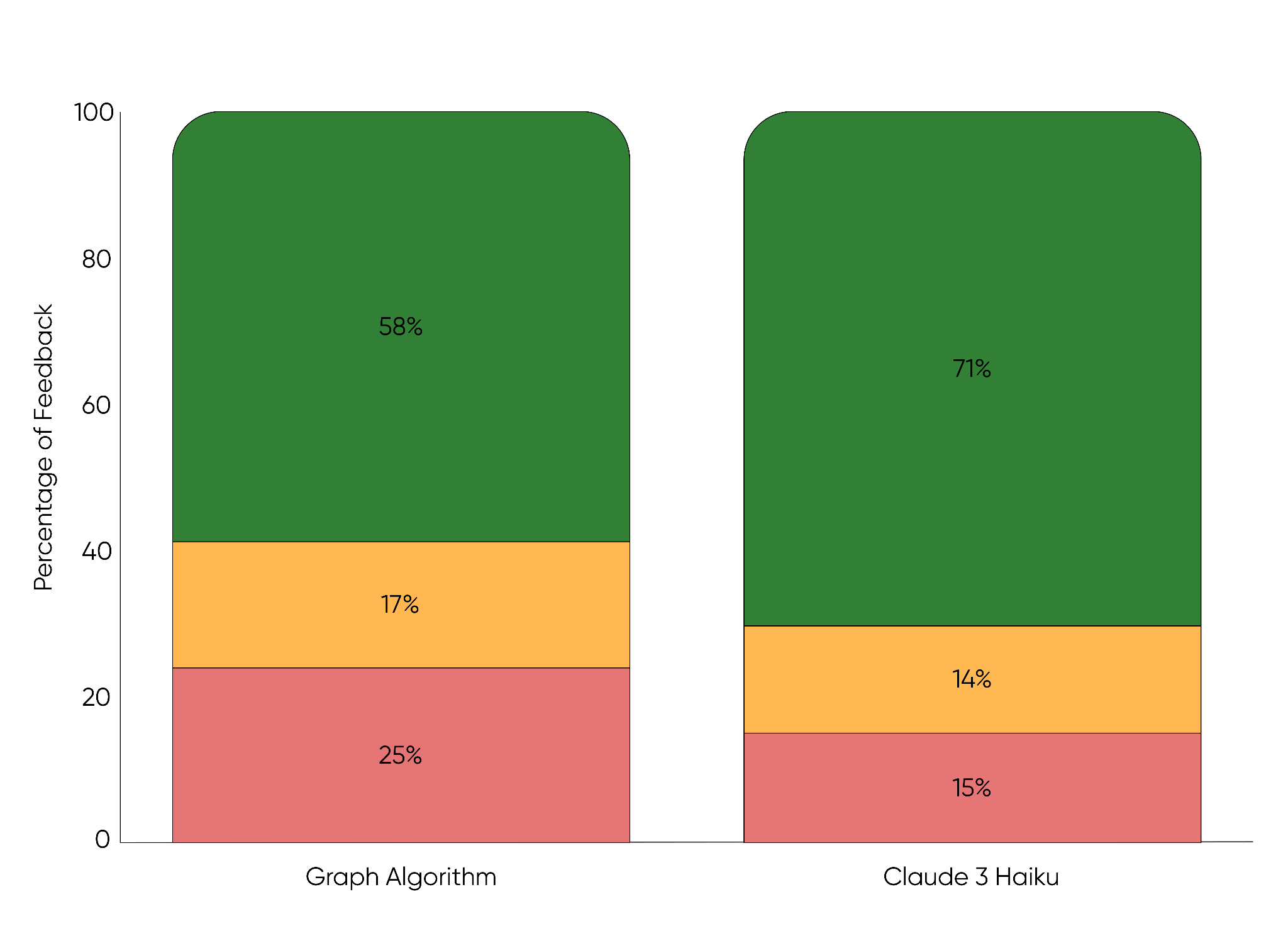
By moving from the Graph Algorithm to Claude 3 Haiku for generating title suggestions, we increased positive user feedback by 13% (from 58% to 71%).
Improving customer satisfaction and reducing cost with Amazon Nova
Since the generative AI based re-launch of Title Suggestions in 2024, LLM technology has improved significantly in performance, cost, and speed. The unified API of Amazon Bedrock has helped us to compare and test new models by flipping model IDs and shipping experiments in hours instead of weeks. We recently tested the Amazon Nova family (Micro, Lite, and Pro) which support more than 200 languages at low latency.
In early 2025, we ran a multivariate A/B test comparing Claude 3 Haiku and Nova models, tracking guardrail metrics and gathering direct user preferences through our in-app feedback feature.
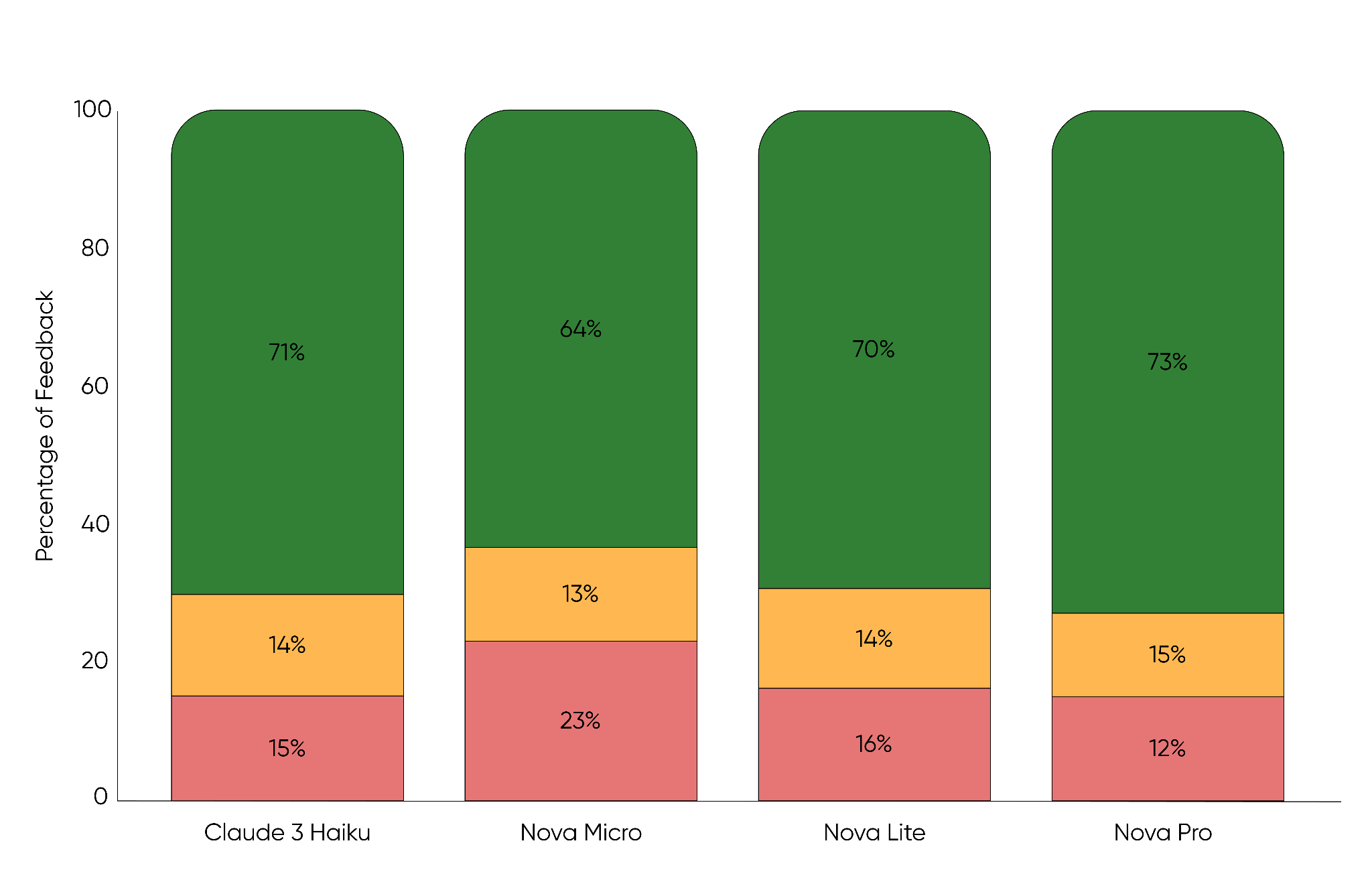
Testing various models for title generation showed that while Claude 3 Haiku (71% positive) performed well, Nova Pro achieved the highest user satisfaction at 73% positive feedback with the lowest negative feedback at 12%.
While Nova Micro-outperformed our legacy Graph method, it lagged in user satisfaction compared to the other LLMs and were set aside. Among the remaining models, we focused not only on quality, but also on cost, latency and throughput, as shown in the following table. These comparisons made it clear that Nova Lite offered near-identical quality to Claude Haiku at lower cost and faster response times.
| Model | Price per 1,000 input tokens | Price per 1,000 output tokens | Response Time (Seconds To Output 500 Tokens) |
| Claude 3 Haiku | $0.00025 | $0.00125 | 6.8 |
| Amazon Nova Lite | $0.000069 | $0.000276 | 2.4 |
| Amazon Nova Pro | $0.00092 | $0.00368 | 3.4 |
*pricing taken from the Amazon Bedrock pricing page
*performance metrics taken from Artificial Analysis
Reducing Time to First Suggestion with the ConverseStream API
One of the key latency metrics that we track is Time to First Suggestion (TTFS), which measures how quickly the first valid suggestion appears after a user request. Even if more options are being generated in the background, lowering TTFS makes the feature feel more responsive, so suggestions are visible before the user moves on.
To improve our TTFS, we migrated from the InvokeModel API of Amazon Bedrock to the ConverseStream API, to stream tokens as they are generated.Because our services require valid title-subtitle-category triplets, we extended the FastAPI to parse streams in real time, returning the first suggestion immediately upon validation. Additional suggestions continue streaming in the background, but the client already has something ready to display.
This shift dramatically reduced TTFS to under one second for the first polished suggestion, instead of waiting for an entire batch of suggestions to complete.
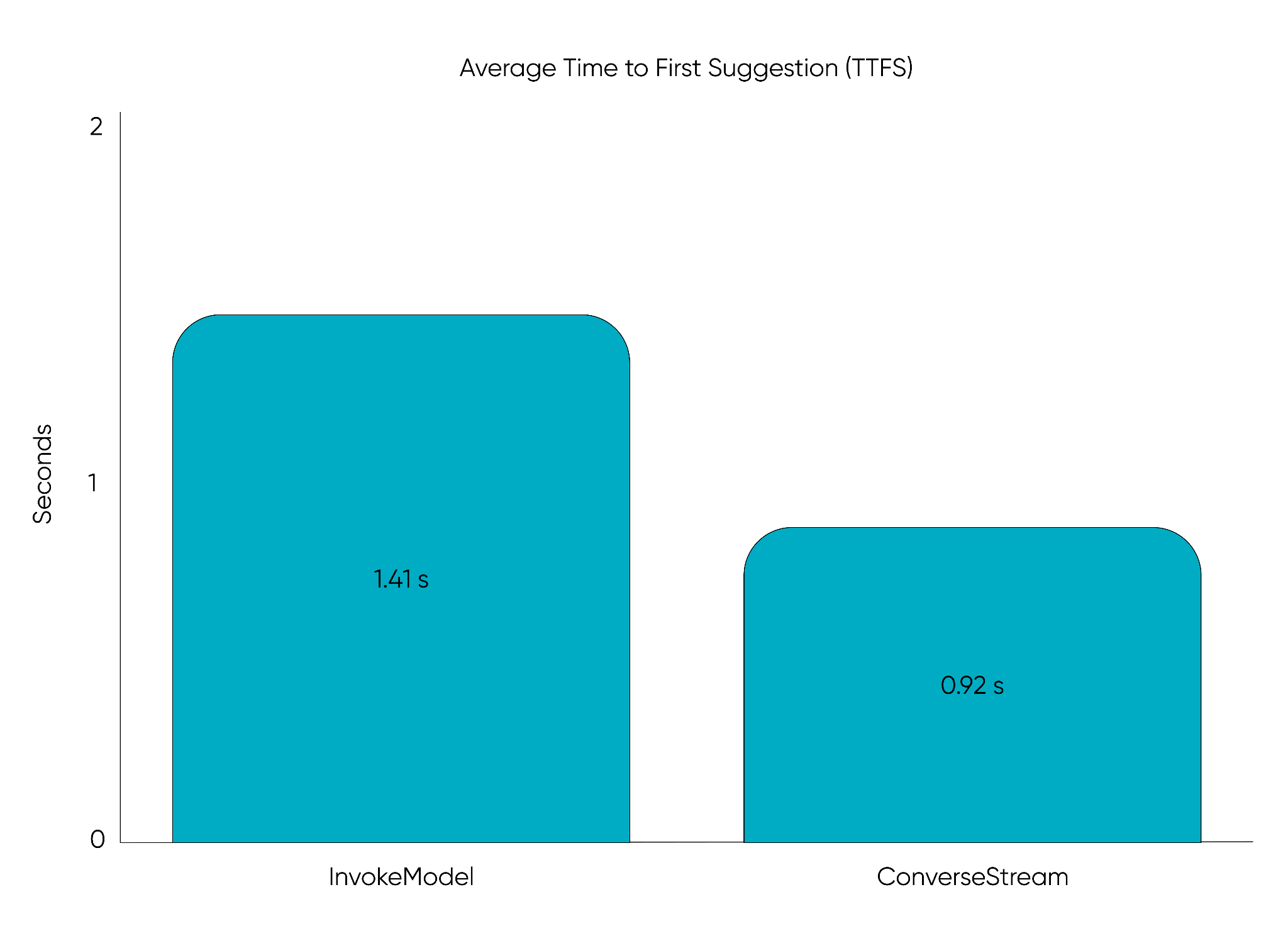
By migrating to the ConverseStream API, we reduced the average time to first suggestion from 1.41 seconds to 0.92 seconds, delivering title suggestions 35% faster to users.
What’s next
In 2025, our Title Suggestion feature has generated over 5.5 million titles, providing insights into what resonates, what doesn’t, and how people interact with our suggestions. That feedback loop will continue to drive evolution of the feature.
Looking ahead, we plan to use larger models like Nova Pro for a portion of our user base, to capture creativity and nuance while still operating cost-effectively at scale. The data that we gather from these experiments will help us to fine-tune smaller models, helping them inherit the strengths of their larger counterparts without compromising latency or affordability.
Future work includes tool integrations that give the LLM richer context about each Photo Book, from event details to seasonal cues, with the aim of generating more personalised, thematic, and brand-aligned titles.
These developments continue our mission: enabling anyone, no matter their skill level, to quickly turn their photos into meaningful, creative, and treasured keepsakes.