Artificial Intelligence
How Thomson Reuters accelerated research and development of natural language processing solutions with Amazon SageMaker
This post is co-written by John Duprey and Filippo Pompili from Thomson Reuters.
Thomson Reuters (TR) is one of the world’s most trusted providers of answers, helping professionals make confident decisions and run better businesses. Teams of experts from TR bring together information, innovation, and confident insights to unravel complex situations, and their worldwide network of journalists and editors keeps customers up to speed on global developments. TR has over 150 years of rich, human-annotated data on law, tax, news, and other segments. TR’s data is the crown jewel of the business. It’s one of the aspects that distinguishes TR from its competitors.
In 2018, a team of research scientists from the Center for AI and Cognitive Computing at TR started an experimental project at the forefront of natural language understanding. The project is based on the latest scientific discoveries that brought wide disruptions in the field of machine reading comprehension (MRC) and aims to develop technologies that you can use to solve numerous tasks, including text classification and natural language question answering.
In this post, we discuss how TR used Amazon SageMaker to accelerate their research and development efforts, and did so with significant cost savings and flexibility. We explain how the team experimented with many variants of BERT to produce a powerful question-answering capability. Lastly, we describe TR’s Secure Content Workspace (SCW), which provided the team with easy and secure access to Amazon SageMaker resources and TR proprietary data.
Customer challenge
The research and development team at TR needed to iterate quickly and securely. Team members already had significant expertise developing question-answering solutions, both via dedicated feature engineering for shallow algorithms and with featureless neural-based solutions. They played a key role in developing the technology powering Westlaw Edge (legal) and Checkpoint Edge (tax), two well-received products from TR. These projects each required 15–18 months of intense research and development efforts and have reached remarkable performance levels. For MRC, the research team decided to experiment with BERT and several of its variants on two sets of TR’s data, one from the legal domain and another from the tax domain.
The legal training corpus was composed of tens of thousands of editorially reviewed questions. Each question was compared against several potential answers in the form of short, on-point, text summaries. These summaries were highly curated editorial material that was extracted from legal cases across many decades—resulting in a candidate training set of several hundred thousand question-answer (QA) pairs, drawn from tens of millions of text summaries. The tax corpus, comprised of more than 60,000 editorially curated documents on US federal tax law, contained thousands of questions and tens of thousands of QA pairs.
Model pretraining and fine-tuning against these datasets would be impossible without state-of-art compute power. Procuring these compute resources typically required a big upfront investment with long lead times. For research ideas that might or might not become a product, it was hard to justify such a significant cost for experimentation.
Why AWS and Amazon SageMaker?
TR chose Amazon SageMaker as the machine learning (ML) service for this project. Amazon SageMaker is a fully managed service to build, train, tune, and deploy ML models at scale. One of the key factors in TR’s decision to choose Amazon SageMaker was the benefit of a managed service with pay-as-you-go billing. Amazon SageMaker lets TR decide how many experiments to run, and helps control the cost of training. More importantly, when a training job completes, the team is no longer charged for the GPU instances they were using. This resulted in substantial cost savings compared to managing their own training resources, which would have resulted in low server utilization. The research team could spin up as many instances as required and let the framework take care of shutting down long-running experiments when they were done. This enabled rapid prototyping at scale.
In addition, Amazon SageMaker has a built-in capability to use managed Spot Instances, which reduced the cost of training in some cases by more than 50%. For some large natural language processing (NLP) experiments using models like BERT on vast proprietary datasets, training time is measured in days, if not weeks, and the hardware involved is expensive GPUs. A single experiment can cost a few thousand dollars. Managed Spot Training with Amazon SageMaker helped TR reduce training costs by 40–50% on average. In comparison to self-managed training, Amazon SageMaker also comes with a full set of built-in security capabilities. This saved the team countless hours of coding that would have been necessary on a self-managed ML infrastructure.
After they launched the training jobs, TR could easily monitor them on the Amazon SageMaker console. The logging and hardware utilization metering facilities allowed the team to have a quick overview of their jobs’ status. For example, they could ensure the training loss was evolving as expected and see how well the allocated GPUs were utilized.
Amazon SageMaker provided TR easy access to state-of-the-art underlying GPU infrastructure without having to provision their own infrastructure or shoulder the burden of managing a set of servers, their security posture, and their patching levels. As faster and cheaper GPU instances become available going forward, TR can use them to reduce cost and training times with a simple configuration change to use the new type. On this project, the team was able to easily experiment with instances from the P2, P3, and G4 family based on their specific needs. AWS also gave TR a broad set of ML services, cost-effective pricing options, granular security controls, and technical support.
Solution overview
Customers operate in complex arenas that move society forward—law, tax, compliance, government, and media—and face increasing complexity as regulation and technology disrupts every industry. TR helps them reinvent the way they work. Using MRC, TR expects to offer natural language searches that outperform previous models that relied on manual feature engineering.
The BERT-based MRC models that the TR research team is developing run on text datasets exceeding several tens of GBs of compressed data. The deep learning frameworks of choice for TR are TensorFlow and PyTorch. The team uses GPU instances for time-consuming neural network training jobs, with runtimes ranging from tens of minutes to several days.
The MRC team has experimented with many variants of BERT. Initially starting from the base model, with 12 layers of stacked transformer encoders and 12 attention heads for 100 million parameters, up to the large model with 24 layers, 16 heads, and 300 million parameters. The availability of V100 GPUs with the largest amount of 32 GB of RAM was instrumental in training the largest model variants. The team formulated the question-answering problem as a binary classification task. Each QA pair is graded by a pool of subject matter experts (SMEs) assigning one of four different grades: A, C, D, and F, where A is for perfect answers and F for completely wrong errors. The grades of each QA pair are converted to numbers, averaged across graders, and binarized.
Because each question-answering system is domain-specific, the research team used transfer learning and domain-adaptation techniques to enable this capability across different sub-domains (for example, law isn’t a single domain). TR used Amazon SageMaker for both language model pretraining and fine-tuning of their BERT models. When compared to the available on-premises hardware, the Amazon SageMaker P3 instance shrunk the training time from many hours to less than 1 hour for fine-tuning jobs. The pretraining of BERT on the domain-specific corpus was reduced from an estimated several weeks to only a few days. Without the dramatic time savings and cost savings provided by Amazon SageMaker, the TR research team would likely not have completed the extensive experimentation required for this project. With Amazon SageMaker, they made breakthroughs that drove key improvements to their applications, enabling faster and more accurate searches by their users.
For inference, TR used the Amazon SageMaker batch transform function for model scoring on vast amounts of test samples. When testing of model performance was satisfactory, Amazon SageMaker managed hosting enabled real-time inference. TR is taking the results of the research and development effort and moving it to production, where they expect to use Amazon SageMaker endpoints to handle millions of requests per day on highly specialized professional domains.
Secure, easy, and continuous access to the vast amounts of proprietary data
Protecting TR’s intellectual property is very important to the long-term success of the business. Because of this, TR has clear, ever-evolving standards around security and ways of working in the cloud that must be followed to protect their assets.
This raises some key questions for TR’s scientists. How can they create an instance of an Amazon SageMaker notebook (or launch a training job) that’s secure and compliant with TR’s standards? How can a scientist get secure access to TR’s data within Amazon SageMaker? TR needed to ensure scientists could do this consistently, securely, and with minimal effort.
Enter Secure Content Workspaces. SCW is a web-based tool developed by TR’s research and development team and answers these questions. The following diagram shows SCW in the context of TR’s research effort described earlier.
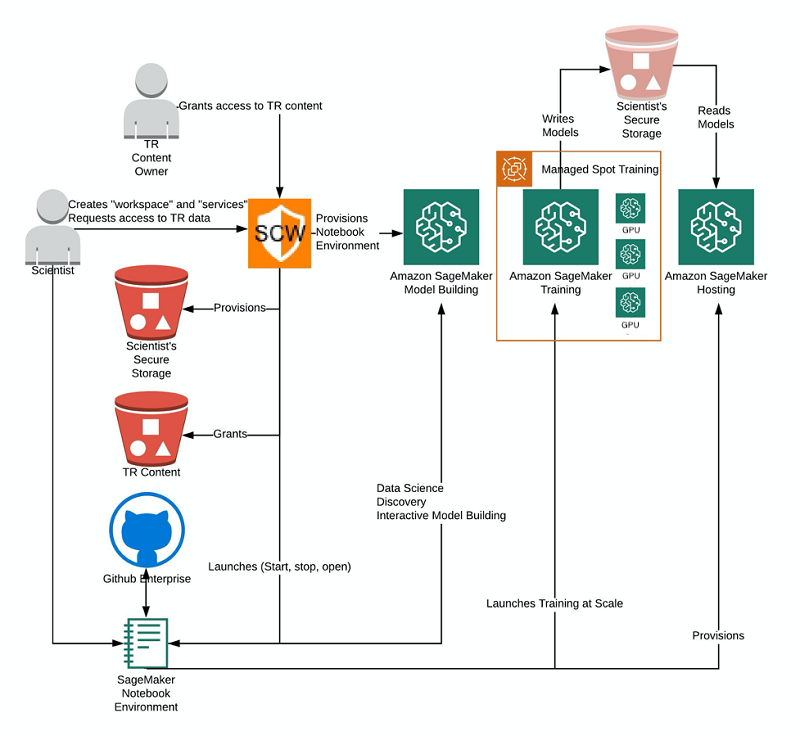
SCW enables secure and controlled access to TR’s data. It also provisions services, like Amazon SageMaker, in ways that are compliant with TR’s standards. With the help of SCW, scientists can work in the cloud with peace of mind knowing they comply with security protocols. SCW lets them focus on what they’re good at—solving hard problems with artificial intelligence (AI).
Conclusion
Thomson Reuters is fully committed to the research and development of state-of-the-art AI capabilities to aid their customers’ work. The MRC research was the latest in these endeavors. Initial results indicate broad applications across TR’s product line—especially for natural language question answering. Whereas past solutions involved extensive feature engineering and complex systems, this new research shows simpler ML solutions are possible. The entire scientific community is very active in this space, and TR is proud to be a part of it.
This research would not have been possible without the significant computational power offered by GPUs and the ability to scale it on demand. The Amazon SageMaker suite of capabilities provided TR with the raw horsepower and necessary frameworks to build, train, and host models for testing. TR built SCW to support cloud-based research and development, like MRC. SCW sets up scientists’ working environment in the cloud and ensures compliance with all of TR’s security standards and recommendations. It made using tools like Amazon SageMaker with TR’s data safe.
Moving forward, the TR research team is looking at introducing a much wider range of AI/ML features based on these powerful deep learning architectures, using Amazon SageMaker and SCW. Examples of such advanced capabilities include on-the-fly answer generation, long text summarization, and fully interactive, conversational, question answering. These capabilities will enable a comprehensive assistive AI system that can guide users toward the best solution for all their information needs.
About the Authors
 Mark Roy is a Machine Learning Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Mark loves to play, coach, and follow basketball.
Mark Roy is a Machine Learning Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Mark loves to play, coach, and follow basketball.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Noble Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Noble Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 John Duprey is senior director of engineering for the Center for AI and Cognitive Computing (C3) at Thomson Reuters. John and the engineering team work alongside scientists and product technology teams to develop AI-based solutions to Thomson Reuters customers’ most challenging problems.
John Duprey is senior director of engineering for the Center for AI and Cognitive Computing (C3) at Thomson Reuters. John and the engineering team work alongside scientists and product technology teams to develop AI-based solutions to Thomson Reuters customers’ most challenging problems.
 Filippo Pompili is Sr NLP Research Scientist at the Center for AI and Cognitive Computing (C3) at Thomson Reuters. Filippo has expertise in machine reading comprehension, information retrieval, and neural language modeling. He actively works on bringing state-of-the-art machine learning discoveries into Thomson Reuters’ most advanced products.
Filippo Pompili is Sr NLP Research Scientist at the Center for AI and Cognitive Computing (C3) at Thomson Reuters. Filippo has expertise in machine reading comprehension, information retrieval, and neural language modeling. He actively works on bringing state-of-the-art machine learning discoveries into Thomson Reuters’ most advanced products.