Artificial Intelligence

Amazon Bedrock Prompt Management is now available in GA
Today we are announcing the general availability of Amazon Bedrock Prompt Management, with new features that provide enhanced options for configuring your prompts and enabling seamless integration for invoking them in your generative AI applications.

How Zalando optimized large-scale inference and streamlined ML operations on Amazon SageMaker
This post is cowritten with Mones Raslan, Ravi Sharma and Adele Gouttes from Zalando. Zalando SE is one of Europe’s largest ecommerce fashion retailers with around 50 million active customers. Zalando faces the challenge of regular (weekly or daily) discount steering for more than 1 million products, also referred to as markdown pricing. Markdown pricing is […]

Unleashing Stability AI’s most advanced text-to-image models for media, marketing and advertising: Revolutionizing creative workflows
To stay competitive, media, advertising, and entertainment enterprises need to stay abreast of recent dramatic technological developments. Generative AI has emerged as a game-changer, offering unprecedented opportunities for creative professionals to push boundaries and unlock new realms of possibility. At the forefront of this revolution is Stability AI’s family of cutting-edge text-to-image AI models. These […]

Build a multi-tenant generative AI environment for your enterprise on AWS
While organizations continue to discover the powerful applications of generative AI, adoption is often slowed down by team silos and bespoke workflows. To move faster, enterprises need robust operating models and a holistic approach that simplifies the generative AI lifecycle. In the first part of the series, we showed how AI administrators can build a […]

Enhance customer support with Amazon Bedrock Agents by integrating enterprise data APIs
Generative AI has transformed customer support, offering businesses the ability to respond faster, more accurately, and with greater personalization. AI agents, powered by large language models (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data […]

Unleash the power of generative AI with Amazon Q Business: How CCoEs can scale cloud governance best practices and drive innovation
In this post, we share how Hearst, one of the nation’s largest global, diversified information, services, and media companies, overcame these challenges by creating a self-service generative AI conversational assistant for business units seeking guidance from their CCoE.

Integrate foundation models into your code with Amazon Bedrock
The rise of large language models (LLMs) and foundation models (FMs) has revolutionized the field of natural language processing (NLP) and artificial intelligence (AI). These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is […]
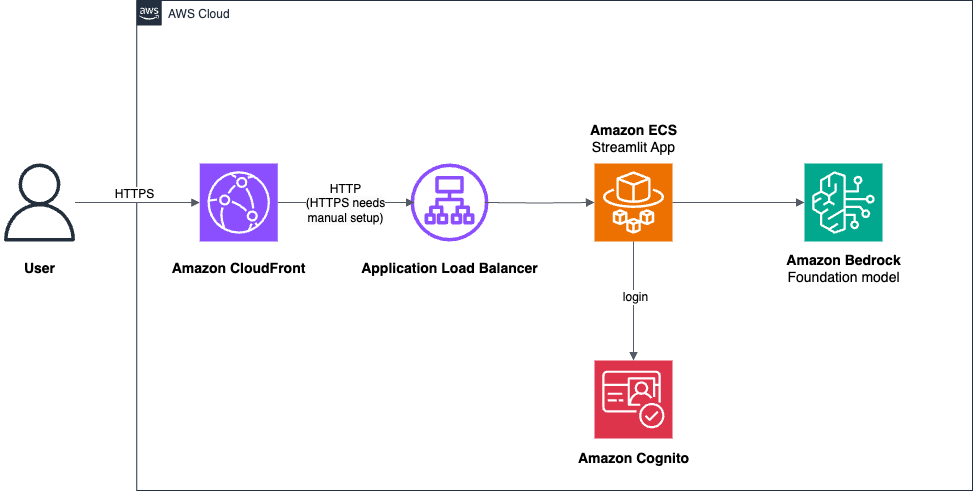
Build and deploy a UI for your generative AI applications with AWS and Python
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. In this post, we explore a practical solution that uses Streamlit, a Python library for building interactive data applications, and AWS services like Amazon Elastic Container Service (Amazon ECS), Amazon Cognito, and the AWS Cloud Development Kit (AWS CDK) to create a user-friendly generative AI application with authentication and deployment.

Unearth insights from audio transcripts generated by Amazon Transcribe using Amazon Bedrock
In this post, we examine how to create business value through speech analytics with some examples focused on the following: 1) automatically summarizing, categorizing, and analyzing marketing content such as podcasts, recorded interviews, or videos, and creating new marketing materials based on those assets, 2) automatically extracting key points, summaries, and sentiment from a recorded meeting (such as an earnings call), and 3) transcribing and analyzing contact center calls to improve customer experience.

Best practices and lessons for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock
In this post, we explore the best practices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation.