Artificial Intelligence
Predict residential real estate prices at ImmoScout24 with Amazon SageMaker
| February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that AWS Data Pipeline service is in maintenance mode and we are not planning to expand the service to new regions. For information about migrating from AWS Data Pipeline, please refer to the AWS Data Pipeline migration documentation. |
This is a guest post by Oliver Frost, data scientist at ImmoScout24, in partnership with Lukas Müller, AWS Solutions Architect.
In 2010, ImmoScout24 released a price index for residential real estate in Germany: the IMX. It was based on ImmoScout24 listings. Besides the price, listings typically contain a lot of specific information such as the construction year, the plot size, or the number of rooms. This information allowed us to build a so-called hedonic price index, which considers the particular features of a real estate property.
When we released the IMX, our goal was to establish it as the standard index for real estate prices in Germany. However, it struggled to capture the price increase in the German property market since the financial crisis of 2008. In addition, like a stock market index, it was an abstract figure that can’t be interpreted directly. The IMX was therefore difficult to grasp for non-experts.
At ImmoScout24, our mission is to make complex decisions easy, and we realized that we needed a new concept to fulfill it. Instead of another index, we decided to build a market report that everyone can easily understand: the WohnBarometer. It’s based on our listings data and takes object properties into account. The key difference from the IMX is that the WohnBarometer shows rent and sale prices in Euro per square meter for specific residential real estate types over time. The figures therefore can be directly interpreted and allow our customers to answer questions such as “Do I pay too much rent?” or “Is the apartment I am about to buy reasonably priced?” or “Which city in my region is the most promising one for investing?” Currently, the WohnBarometer is reported for Germany as a whole, the seven biggest cities, and alternating local markets.
The following graph shows an example of the WohnBarometer, with sale prices for Berlin and the development per quarter.
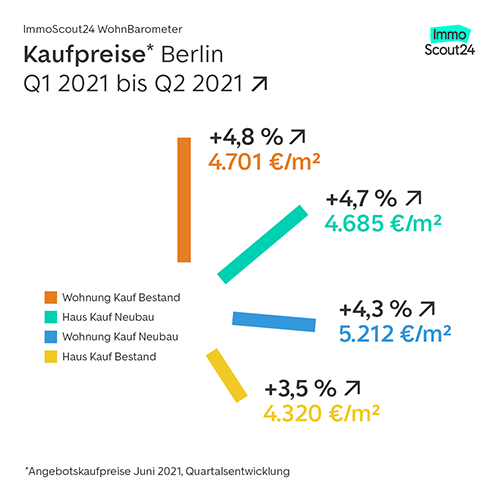
This post discusses how ImmoScout24 used Amazon SageMaker to create the model for the WohnBarometer in order to make it relevant for our customers. It discusses the underlying data model, hyperparameter tuning, and technical setup. This post also shows how SageMaker supported one data scientist to complete the WohnBarometer within 2 months. It took a whole team 2 years to develop the first version of the IMX. Such an investment was not an option for the WohnBarometer.
About ImmoScout24
ImmoScout24 is the leading online platform for residential and commercial real estate in Germany. For over 20 years, ImmoScout24 has been revolutionizing the real estate market and supports over 20 million users each month on its online marketplace or in its app to find new homes or commercial spaces. That’s why 99% of our target customer group know ImmoScout24. With its digital solutions, the online marketplace coordinates and brings owners, realtors, tenants, and buyers together successfully. ImmoScout24 is working towards the goal of digitizing the process of real estate transactions and thereby making complex decisions easy. Since 2012, ImmoScout24 has also been active in the Austrian real estate market, reaching around 3 million users monthly.
From on-premises to AWS Data Pipeline to SageMaker
In this section, we discuss the previous setup and its challenges, and why we decided to use SageMaker for our new model.
The previous setup
When the first version of the IMX was published in 2010, the cloud was still a mystery to most businesses, including ImmoScout24. The field of machine learning (ML) was in its infancy and only a handful of experts knew how to code a model (for the sake of illustration, the first public release of Scikit-Learn was in February 2010). It’s no surprise that the development of the IMX took more than 2 years and cost a seven-figure sum.
In 2015, ImmoScout24 started its AWS migration, and rebuilt IMX on AWS infrastructure. With the data in our Amazon Simple Storage Service (Amazon S3) data lake, both the data preprocessing and the model training were now done on Amazon EMR clusters orchestrated by AWS Data Pipeline. While the former was a PySpark ETL application, the latter was several Python scripts using classical ML packages (such as Scikit-Learn).
Issues with this setup
Although this setup proved quite stable, troubleshooting the infrastructure or improving the model wasn’t easy. A key problem with the model was its complexity, because some components had begun a life on their own: in the end, the code of the outlier detection was almost twice as long the code of the core IMX model itself.
The core model, in fact, wasn’t one model, but hundreds: one model per residential real estate type and region, with the definition varying from a single neighborhood in a big city to several villages in rural areas. We had, for example, one model for apartments for sale in the middle of Berlin and one model for houses for sale in a suburb of Munich. Because setting up the training of all these models took a lot of time, we omitted the hyperparameter tuning, which likely led to the models underperforming.
Why we decided on SageMaker
Given these issues and our ambition of having a market report with practical benefits, we had to decide between rewriting large parts of the existing code or starting from scratch. As you can infer from this post, we opted for the latter. But why SageMaker?
Most of our time spent on the IMX went into troubleshooting the infrastructure, not improving the model. For the new market report, we wanted to flip this around, with the focus on the statistical performance of the model. We also wanted to have the flexibility to quickly replace individual components of the model, such as the optimization of the hyperparameters. What if a new superior boosting algorithm comes around (think about how XGBoost hit the stage in 2014)? Of course, we want to adopt it as one of the first!
In SageMaker, the major components of the classical ML workflow—preprocessing, training, hyperparameter tuning, and inference—are neatly separated on the API level and also on the AWS Management Console. Modifying them individually isn’t difficult.
The new model
In this section, we discuss the components of the new model, including its input data, algorithm, hyperparameter tuning, and technical setup.
Input data
The WohnBarometer is based on a sliding window of 5 years of ImmoScout24 listings of residential real estate located in Germany. After we remove outliers and fraudulent listings, we’re left with approximately 4 million listings that are split into train (60 %), validation (20 %), and test data (20 %). The relationship between listings and objects is not necessarily 1:1; over the course of 5 years, it’s likely that the same object is inserted multiple times (by multiple people).
We use 13 listing attributes, such as the location of the property (WGS84 coordinates), the real estate type (house or apartment, sale or rent), its age (years), its size (square meter) or it’s condition (for example, new or refurbished). Given that each listing typically comes with dozens of attributes, the question arises: which to include in the model? On the one hand, we used domain knowledge; for example, it’s well known that location is a key factor, and in almost all markets new property is more expensive than existing ones. On the other hand, we relied on our experiences with the IMX and similar models. There we learned that including dozens of attributes doesn’t significantly improve the model.
Depending on the real estate type of the listing, the target variable of our model is either the rent per square meter or the sale price per square meter (we explain later why this choice wasn’t ideal). Unlike the IMX, the WohnBarometer is therefore a number that can be directly interpreted and acted upon by our customers.
Model description
When using SageMaker, you can choose between different strategies of implementing your algorithm:
- Use one of SageMaker’s built-in algorithms. There are almost 20 and they cover all major ML problem types.
- Customize a pre-made Docker image based on a standard ML framework (such as Scikit-Learn or PyTorch).
- Build your own algorithm and deploy it as a Docker image.
For the WohnBarometer, we wanted a solution that is easy to maintain and allows us to focus on improving the model itself, not the underlying infrastructure. Therefore, we decided on the first option: use a fully-managed algorithm with proper documentation and fast support if needed. Next, we needed to pick the algorithm itself. Again, the decision wasn’t difficult: we went for the XGBoost algorithm because it’s one of the most renowned ML algorithms for regression type problems, and we have already successfully used it in several projects.
Hyperparameter tuning
Most ML algorithms come with a myriad of parameters to tweak. Boosting algorithms, for example, have many parameters specifying how exactly the trees are built: Do the trees have at maximum 20 or 30 leaves? Is each tree based on all rows and columns or only samples? How heavily to prune the trees? Finding the optimal values of those parameters (as measured by an evaluation metric of your choice), the so-called hyperparameter tuning, is critical to building a powerful ML model.
A key question in hyperparameter tuning is which parameters to tune and how to set the search ranges. You might ask, why not check all possible combinations? Although in theory this sounds like a good idea, it would result in an enormous hyperparameter space with way too many points to evaluate them all at a reasonable price. That is why ML practitioners typically select a small number of hyperparameters known to have a strong impact on the performance of the chosen algorithm.
After the hyperparameter space is defined, the next task is to find the best combination of values in it. The following techniques are commonly employed:
- Grid search – Divide the space in a discrete grid and then evaluate all points in the grid with cross-validation.
- Random search – Randomly draw combinations from the space. With this approach, you’ll most likely miss the best combination, but it serves as a good benchmark.
- Bayesian optimization – Build a probabilistic model of the objective function and use this model to generate new combinations. The model is updated after each combination, leading quickly to good results.
In recent years, thanks to cheap compute power, Bayesian optimization has become the gold standard in hyperparameter tuning, and is the default setting in SageMaker.
Technical setup
As with many other AWS services, you can create SageMaker jobs on the console, with the AWS Command Line Interface (AWS CLI), or via code. We chose the third option, the SageMaker Python SDK to be precise, because it allows for a highly automated setup: the WohnBarometer lives in a Python software project that is command-line executable. For example, all steps of the ML pipeline such as the preprocessing or the model training can be triggered via Bash commands. Those Bash commands, in turn, are orchestrated with a Jenkins pipeline powered by AWS Fargate.
Let’s look at the steps and the underlying infrastructure:
- Preprocessing – The preprocessing is done with the built-in Scikit-Learn library in SageMaker. Because it involves joining data frames with millions of rows, we need an ml.m5.24xlarge machine here, the largest you can get in the ml.m family. Alternatively, we could have used multiple smaller machines with a distributed framework like Dask, but we wanted to keep it as simple as possible.
- Training – We use the default SageMaker XGBoost algorithm. The training is done with two ml.m5.12xlarge machines. It’s worth mentioning that our train.py containing the code of the model training and the hyperparameter tuning has less than 100 rows.
- Hyperparameter tuning – Following the principle of less is more, we only tune 11 hyperparameters (for example, the number of boosting rounds and the learning rate), which gives us time to carefully choose their ranges and inspect how they interact with each other. With only a few hyperparameters, each training job runs relatively fast; in our case the jobs take between 10–20 minutes. With a maximal number of 30 training jobs and 2 concurrent jobs, the total training time is around 3 hours.
- Inference – SageMaker offers multiple options to serve your model. We use batch transform jobs because we only need the WohnBarometer numbers once a quarter. We didn’t use an endpoint because it would be idle most of the time. Each batch job (approximately 6.8 million rows) is served by a single ml.m5.4xlarge machine in less than 10 minutes.
We can easily debug these steps on the SageMaker console. If, for example, a training job is taking longer than expected, we navigate to the Training page, locate the training job in question, and review Amazon CloudWatch metrics of the underlying machines.
The following architecture diagram shows the infrastructure of the WohnBarometer:

Challenges and learnings
In the beginning everything went smoothly: within a few days we set up the software project and trained a miniature version of our model in SageMaker. We had high hopes for the first run on the full dataset and the hyperparameter tuning in place. Unfortunately, the results weren’t satisfying. We had the following key issues:
- The predictions of the model were too low, both for rent and sale objects. For Berlin, for example, the sale prices predicted for our reference objects were roughly 50% below the market prices.
- According to the model, there was no significant price difference between new and existing buildings. The truth is that new buildings are almost always significantly more expensive than existing buildings.
- The effect of the location on the price wasn’t captured correctly. We know, for example, that apartments for sale in Frankfurt am Main, are, on average, more expensive than in Berlin (although Berlin is catching up); our model, however, predicted it the other way round.
What was the problem and how did we solve it?
Sampling of the features
At first glance, it looks like the issues aren’t related, but indeed they are. By default, XGBoost builds each tree with a random sample of the features. Let’s say a model has 10 features F1, F2, … F10, then the algorithm might use F1, F4, and F7 for one tree, and F3, F4, and F8 for another. While in general this behavior effectively prevents overfitting, it can be problematic if the number of features is small and some of them have a big effect on the target variable. In this case, many trees will miss the crucial features.
XGBoost’s sampling of our 13 features led to many trees including neither of the crucial features—real estate type, location, and new or existing buildings—and as a consequence caused these issues. Luckily, there is a parameter to control the sampling: colsample_bytree (in fact, there are two more parameters to control the sampling, but we didn’t touch them). When we checked our code, we saw that colsample_bytree was set to 0.5, a value we carried over from past projects. As soon as we set it to the default value of 1, the preceding issues were gone.
One model vs. multiple models
Unlike the IMX, the WohnBarometer model really is only one model. Although this minimizes the maintenance effort, it’s not ideal from a statistical point of view. Because our training data contains both sale and rent objects, the spread in the target variable is huge: it ranges from below 5 Euro for some rent apartments to well above 10,000 Euro for houses for sale in first-class locations. The big challenge for the model is to understand that an error of 5 Euro is fantastic for sale objects, but disastrous for rent objects.
In hindsight, knowing how easy it is to maintain multiple models in SageMaker, we would have built at least two models: one for rent and one for sale objects. This would make it easier to capture the peculiarities of both markets. For example, the price of unrented apartments for sale is typically 20–30% higher than for rented apartments for sale. Therefore, encoding this information as a dummy variable in the sale model makes a lot of sense; for the rent model on the other hand, you could leave it out.
Conclusion
Did the WohnBarometer meet the goal of being relevant to our customers? Taking media coverage as an indication, the answer is a clear yes: as of November 2021, more than 700 newspaper articles and TV or radio reports on the WohnBarometer have been published. The list includes national newspapers such as Frankfurter Allgemeine Zeitung, Tagesspiegel, and Handelsblatt, and local newspapers that often ask for WohnBarometer figures for their region. Because we calculate the figures for all regions of Germany anyway, we’re happy to take such requests. With the old IMX, this level of granularity wasn’t possible.
The WohnBarometer outperforms the IMX in regards to statical performance, in particular when it comes to the costs: the IMX was generated by an EMR cluster with 10 task nodes running almost half a day. In contrast, all WohnBarometer steps take less than 5 hours using medium-sized machines. This results in cost savings of almost 75%.
Thanks to SageMaker, we were able to bring a complex ML model in production with one data scientist in less than 2 months. This is remarkable. 10 years earlier, when ImmoScout24 built the IMX, reaching the same milestone took more than 2 years and involved a whole team.
How could we be so efficient? SageMaker allowed us to focus on the model instead of the infrastructure, and SageMaker promotes a microservice architecture that is easy to maintain. If we got stuck with something, we could call on AWS support. In the past, when one of our IMX data pipelines failed, we would sometimes spend days to debug it. Since we started publishing WohnBarometer figures in April 2021, the SageMaker infrastructure hasn’t failed a single time.
To learn more about the WohnBarometer, check out WohnBarometer and WohnBarometer: Angebotsmieten stiegen 2021 bundesweit wieder stärker an. To learn more about using the SageMaker Scikit-Learn library for preprocessing, see Preprocess input data before making predictions using Amazon SageMaker inference pipelines and Scikit-learn. Please send us feedback, either on the AWS forum for Amazon SageMaker, or through your AWS support contacts.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
Oliver Frost joined ImmoScout24 in 2017 as a business analyst. Two years later, he became a data scientist in a team whose job it is to turn ImmoScout24 data into veritable data products. Before building the WohnBarometer model, he ran smaller SageMaker projects. Oliver holds several AWS certificates, including the Machine Learning Specialty.
Lukas Müller is a Solutions Architect at AWS. He works with customers in the sports, media, and entertainment industries. He is always looking for ways to combine technical enablement with cultural and organizational enablement to help customers achieve business value with cloud technologies.