Artificial Intelligence
Scale training and inference of thousands of ML models with Amazon SageMaker
As machine learning (ML) becomes increasingly prevalent in a wide range of industries, organizations are finding the need to train and serve large numbers of ML models to meet the diverse needs of their customers. For software as a service (SaaS) providers in particular, the ability to train and serve thousands of models efficiently and cost-effectively is crucial for staying competitive in a rapidly evolving market.
Training and serving thousands of models requires a robust and scalable infrastructure, which is where Amazon SageMaker can help. SageMaker is a fully managed platform that enables developers and data scientists to build, train, and deploy ML models quickly, while also offering the cost-saving benefits of using the AWS Cloud infrastructure.
In this post, we explore how you can use SageMaker features, including Amazon SageMaker Processing, SageMaker training jobs, and SageMaker multi-model endpoints (MMEs), to train and serve thousands of models in a cost-effective way. To get started with the described solution, you can refer to the accompanying notebook on GitHub.
Use case: Energy forecasting
For this post, we assume the role of an ISV company that helps their customers become more sustainable by tracking their energy consumption and providing forecasts. Our company has 1,000 customers who want to better understand their energy usage and make informed decisions about how to reduce their environmental impact. To do this, we use a synthetic dataset and train an ML model based on Prophet for each customer to make energy consumption forecasts. With SageMaker, we can efficiently train and serve these 1,000 models, providing our customers with accurate and actionable insights into their energy usage.
There are three features in the generated dataset:
- customer_id – This is an integer identifier for each customer, ranging from 0–999.
- timestamp – This is a date/time value that indicates the time at which the energy consumption was measured. The timestamps are randomly generated between the start and end dates specified in the code.
- consumption – This is a float value that indicates the energy consumption, measured in some arbitrary unit. The consumption values are randomly generated between 0–1,000 with sinusoidal seasonality.
Solution overview
To efficiently train and serve thousands of ML models, we can use the following SageMaker features:
- SageMaker Processing – SageMaker Processing is a fully managed data preparation service that enables you to perform data processing and model evaluation tasks on your input data. You can use SageMaker Processing to transform raw data into the format needed for training and inference, as well as to run batch and online evaluations of your models.
- SageMaker training jobs – You can use SageMaker training jobs to train models on a variety of algorithms and input data types, and specify the compute resources needed for training.
- SageMaker MMEs – Multi-model endpoints enable you to host multiple models on a single endpoint, which makes it easy to serve predictions from multiple models using a single API. SageMaker MMEs can save time and resources by reducing the number of endpoints needed to serve predictions from multiple models. MMEs support hosting of both CPU- and GPU-backed models. Note that in our scenario, we use 1,000 models, but this is not a limitation of the service itself.
The following diagram illustrates the solution architecture.
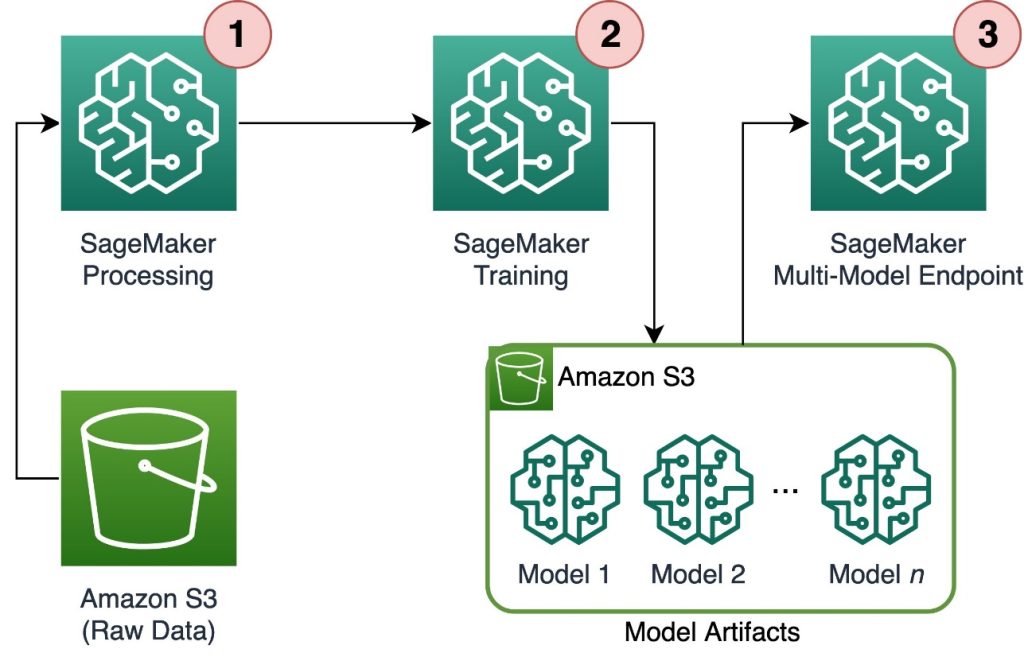
The workflow includes the following steps:
- We use SageMaker Processing to preprocess data and create a single CSV file per customer and store it in Amazon Simple Storage Service (Amazon S3).
- The SageMaker training job is configured to read the output of the SageMaker Processing job and distribute it in a round-robin fashion to the training instances. Note that this can also be achieved with Amazon SageMaker Pipelines.
- The model artifacts are stored in Amazon S3 by the training job, and are served directly from the SageMaker MME.
Scale training to thousands of models
Scaling the training of thousands of models is possible via the distribution parameter of the TrainingInput class in the SageMaker Python SDK, which allows you to specify how data is distributed across multiple training instances for a training job. There are three options for the distribution parameter: FullyReplicated, ShardedByS3Key, and ShardedByRecord. The ShardedByS3Key option means that the training data is sharded by S3 object key, with each training instance receiving a unique subset of the data, avoiding duplication. After the data is copied by SageMaker to the training containers, we can read the folder and files structure to train a unique model per customer file. The following is an example code snippet:
Every SageMaker training job stores the model saved in the /opt/ml/model folder of the training container before archiving it in a model.tar.gz file, and then uploads it to Amazon S3 upon training job completion. Power users can also automate this process with SageMaker Pipelines. When storing multiple models via the same training job, SageMaker creates a single model.tar.gz file containing all the trained models. This would then mean that, in order to serve the model, we would need to unpack the archive first. To avoid this, we use checkpoints to save the state of individual models. SageMaker provides the functionality to copy checkpoints created during the training job to Amazon S3. Here, the checkpoints need to be saved in a pre-specified location, with the default being /opt/ml/checkpoints. These checkpoints can be used to resume training at a later moment or as a model to deploy on an endpoint. For a high-level summary of how the SageMaker training platform manages storage paths for training datasets, model artifacts, checkpoints, and outputs between AWS Cloud storage and training jobs in SageMaker, refer to Amazon SageMaker Training Storage Folders for Training Datasets, Checkpoints, Model Artifacts, and Outputs.
The following code uses a fictitious model.save() function inside the train.py script containing the training logic:
Scale inference to thousands of models with SageMaker MMEs
SageMaker MMEs allow you to serve multiple models at the same time by creating an endpoint configuration that includes a list of all the models to serve, and then creating an endpoint using that endpoint configuration. There is no need to re-deploy the endpoint every time you add a new model because the endpoint will automatically serve all models stored in the specified S3 paths. This is achieved with Multi Model Server (MMS), an open-source framework for serving ML models that can be installed in containers to provide the front end that fulfills the requirements for the new MME container APIs. In addition, you can use other model servers including TorchServe and Triton. MMS can be installed in your custom container via the SageMaker Inference Toolkit. To learn more about how to configure your Dockerfile to include MMS and use it to serve your models, refer to Build Your Own Container for SageMaker Multi-Model Endpoints.
The following code snippet shows how to create an MME using the SageMaker Python SDK:
When the MME is live, we can invoke it to generate predictions. Invocations can be done in any AWS SDK as well as with the SageMaker Python SDK, as shown in the following code snippet:
When calling a model, the model is initially loaded from Amazon S3 on the instance, which can result in a cold start when calling a new model. Frequently used models are cached in memory and on disk to provide low-latency inference.
Conclusion
SageMaker is a powerful and cost-effective platform for training and serving thousands of ML models. Its features, including SageMaker Processing, training jobs, and MMEs, enable organizations to efficiently train and serve thousands of models at scale, while also benefiting from the cost-saving advantages of using the AWS Cloud infrastructure. To learn more about how to use SageMaker for training and serving thousands of models, refer to Process data, Train a Model with Amazon SageMaker and Host multiple models in one container behind one endpoint.
About the Authors
 Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
 Maurits de Groot is a Solutions Architect at Amazon Web Services, based out of Amsterdam. He likes to work on machine learning-related topics and has a predilection for startups. In his spare time, he enjoys skiing and playing squash.
Maurits de Groot is a Solutions Architect at Amazon Web Services, based out of Amsterdam. He likes to work on machine learning-related topics and has a predilection for startups. In his spare time, he enjoys skiing and playing squash.