Artificial Intelligence
Simplify iterative machine learning model development by adding features to existing feature groups in Amazon SageMaker Feature Store
Feature engineering is one of the most challenging aspects of the machine learning (ML) lifecycle and a phase where the most amount of time is spent—data scientists and ML engineers spend 60–70% of their time on feature engineering. AWS introduced Amazon SageMaker Feature Store during AWS re:Invent 2020, which is a purpose-built, fully managed, centralized store for features and associated metadata. Features are signals extracted from data to train ML models. The advantage of Feature Store is that the feature engineering logic is authored one time, and the features generated are stored on a central platform. The central store of features can be used for training and inference and be reused across different data engineering teams.
Features in a feature store are stored in a collection called feature group. A feature group is analogous to a database table schema where columns represent features and rows represent individual records. Feature groups have been immutable since Feature Store was introduced. If we had to add features to an existing feature group, the process was cumbersome—we had to create a new feature group, backfill the new feature group with historical data, and modify downstream systems to use this new feature group. ML development is an iterative process of trial and error where we may identify new features continuously that can improve model performance. It’s evident that not being able to add features to feature groups can lead to a complex ML model development lifecycle.
Feature Store recently introduced the ability to add new features to existing feature groups. A feature group schema evolves over time as a result of new business requirements or because new features have been identified that yield better model performance. Data scientists and ML engineers need to easily add features to an existing feature group. This ability reduces the overhead associated with creating and maintaining multiple feature groups and therefore lends itself to iterative ML model development. Model training and inference can take advantage of new features using the same feature group by making minimal changes.
In this post, we demonstrate how to add features to a feature group using the newly released UpdateFeatureGroup API.
Overview of solution
Feature Store acts as a single source of truth for feature engineered data that is used in ML training and inference. When we store features in Feature Store, we store them in feature groups.
We can enable feature groups for offline only mode, online only mode, or online and offline modes.
An online store is a low-latency data store and always has the latest snapshot of the data. An offline store has a historical set of records persisted in Amazon Simple Storage Service (Amazon S3). Feature Store automatically creates an AWS Glue Data Catalog for the offline store, which enables us to run SQL queries against the offline data using Amazon Athena.
The following diagram illustrates the process of feature creation and ingestion into Feature Store.
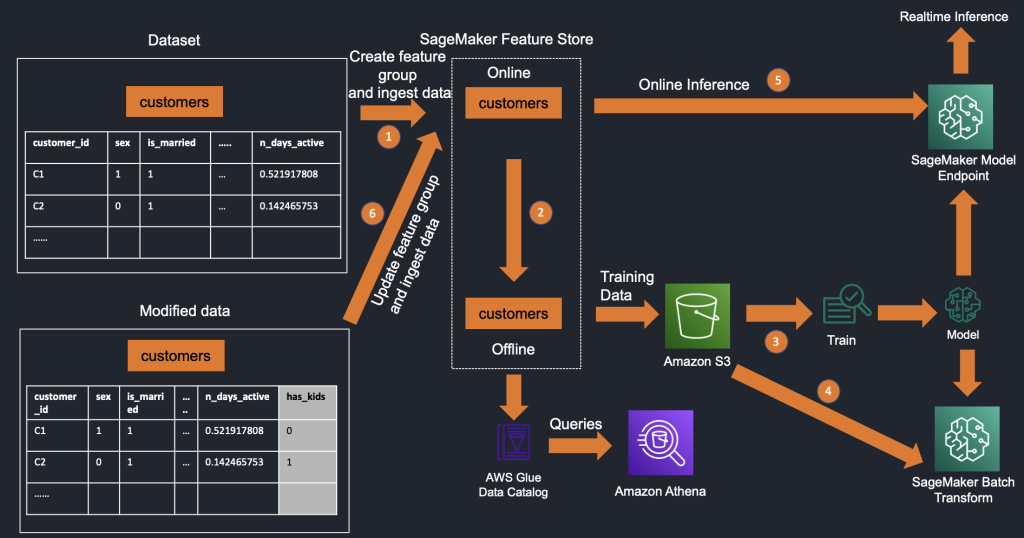
The workflow contains the following steps:
- Define a feature group and create the feature group in Feature Store.
- Ingest data into the feature group, which writes to the online store immediately and then to the offline store.
- Use the offline store data stored in Amazon S3 for training one or more models.
- Use the offline store for batch inference.
- Use the online store supporting low-latency reads for real-time inference.
- To update the feature group to add a new feature, we use the new Amazon SageMaker
UpdateFeatureGroupAPI. This also updates the underlying AWS Glue Data Catalog. After the schema has been updated, we can ingest data into this updated feature group and use the updated offline and online store for inference and model training.
Dataset
To demonstrate this new functionality, we use a synthetically generated customer dataset. The dataset has unique IDs for customer, sex, marital status, age range, and how long since they have been actively purchasing.

Let’s assume a scenario where a business is trying to predict the propensity of a customer purchasing a certain product, and data scientists have developed a model to predict this intended outcome. Let’s also assume that the data scientists have identified a new signal for the customer that could potentially improve model performance and better predict the outcome. We work through this use case to understand how to update feature group definition to add the new feature, ingest data into this new feature, and finally explore the online and offline feature store to verify the changes.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account.
- A SageMaker Jupyter notebook instance. Access the code from the Amazon SageMaker Feature Store Update Feature Group GitHub repository and upload it to your notebook instance.
- You can also run the notebook in the Amazon SageMaker Studio environment, which is an IDE for ML development. You can clone the GitHub repo via a terminal inside the Studio environment using the following command:
Add features to a feature group
In this post, we walk through the update_feature_group.ipynb notebook, in which we create a feature group, ingest an initial dataset, update the feature group to add a new feature, and re-ingest data that includes the new feature. At the end, we verify the online and offline store for the updates. The fully functional notebook and sample data can be found in the GitHub repository. Let’s explore some of the key parts of the notebook here.
- We create a feature group to store the feature-engineered customer data using the
FeatureGroup.createAPI of the SageMaker SDK.
- We create a Pandas DataFrame with the initial CSV data. We use the current time as the timestamp for the
event_timefeature. This corresponds to the time when the event occurred, which implies when the record is added or updated in the feature group. - We ingest the DataFrame into the feature group using the SageMaker SDK
FeatureGroup.ingestAPI. This is a small dataset and therefore can be loaded into a Pandas DataFrame. When we work with large amounts of data and millions of rows, there are other scalable mechanisms to ingest data into Feature Store, such as batch ingestion with Apache Spark.
- We can verify that data has been ingested into the feature group by running Athena queries in the notebook or running queries on the Athena console.
- After we verify that the offline feature store has the initial data, we add the new feature
has_kidsto the feature group using the Boto3 update_feature_group APIThe Data Catalog gets automatically updated as part of this API call. The API supports adding multiple features at a time by specifying them in the
FeatureAdditionsdictionary.
- We verify that feature has been added by checking the updated feature group definition
The
LastUpdateStatusin thedescribe_feature_groupAPI response initially shows the statusInProgress. After the operation is successful, theLastUpdateStatusstatus changes toSuccessful. If for any reason the operation encounters an error, thelastUpdateStatusstatus shows asFailed, with the detailed error message inFailureReason.

When theupdate_feature_groupAPI is invoked, the control plane reflects the schema change immediately, but the data plane takes up to 5 minutes to update its feature group schema. We must ensure that enough time is given for the update operation before proceeding to data ingestion.
- We prepare data for the
has_kidsfeature by generating random 1s and 0s to indicate whether a customer has kids or not.
- We ingest the DataFrame that has the newly added column into the feature group using the SageMaker SDK
FeatureGroup.ingestAPI
- Next, we verify the feature record in the online store for a single customer using the Boto3
get_recordAPI.
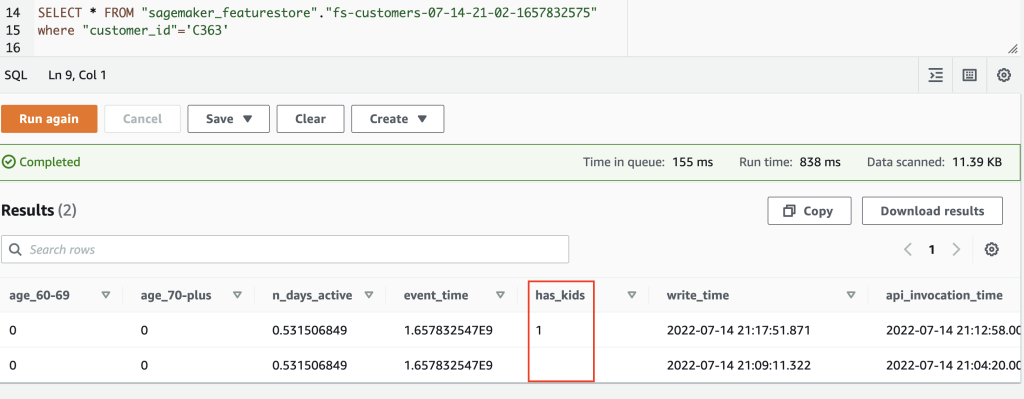
- Let’s query the same customer record on the Athena console to verify the offline data store. The data is appended to the offline store to maintain historical writes and updates. Therefore, we see two records here: a newer record that has the feature updated to value 1, and an older record that doesn’t have this feature and therefore shows the value as empty. The offline store persistence happens in batches within 15 minutes, so this step could take time.
Now that we have this feature added to our feature group, we can extract this new feature into our training dataset and retrain models. The goal of the post is to highlight the ease of modifying a feature group, ingesting data into the new feature, and then using the updated data in the feature group for model training and inference.
Clean up
Don’t forget to clean up the resources created as part of this post to avoid incurring ongoing charges.
- Delete the S3 objects in the offline store:
- Delete the feature group:
- Stop the SageMaker Jupyter notebook instance. For instructions, refer to Clean Up.
Conclusion
Feature Store is a fully managed, purpose-built repository to store, share, and manage features for ML models. Being able to add features to existing feature groups simplifies iterative model development and alleviates the challenges we see in creating and maintaining multiple feature groups.
In this post, we showed you how to add features to existing feature groups via the newly released SageMaker UpdateFeatureGroup API. The steps shown in this post are available as a Jupyter notebook in the GitHub repository. Give it a try and let us know your feedback in the comments.
Further reading
If you’re interested in exploring the complete scenario mentioned earlier in this post of predicting a customer ordering a certain product, check out the following notebook, which modifies the feature group, ingests data, and trains an XGBoost model with the data from the updated offline store. This notebook is part of a comprehensive workshop developed to demonstrate Feature Store functionality.
References
More information is available at the following resources:
- Create, Store, and Share Features with Amazon SageMaker Feature Store
- Amazon Athena User Guide
- Get Started with Amazon SageMaker Notebook Instances
- UpdateFeatureGroup API
- SageMaker Boto3 update_feature_group API
- Getting started with Amazon SageMaker Feature Store
About the authors
 Chaitra Mathur is a Principal Solutions Architect at AWS. She guides customers and partners in building highly scalable, reliable, secure, and cost-effective solutions on AWS. She is passionate about Machine Learning and helps customers translate their ML needs into solutions using AWS AI/ML services. She holds 5 certifications including the ML Specialty certification. In her spare time, she enjoys reading, yoga, and spending time with her daughters.
Chaitra Mathur is a Principal Solutions Architect at AWS. She guides customers and partners in building highly scalable, reliable, secure, and cost-effective solutions on AWS. She is passionate about Machine Learning and helps customers translate their ML needs into solutions using AWS AI/ML services. She holds 5 certifications including the ML Specialty certification. In her spare time, she enjoys reading, yoga, and spending time with her daughters.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
 Charu Sareen is a Sr. Product Manager for Amazon SageMaker Feature Store. Prior to AWS, she was leading growth and monetization strategy for SaaS services at VMware. She is a data and machine learning enthusiast and has over a decade of experience spanning product management, data engineering, and advanced analytics. She has a bachelor’s degree in Information Technology from National Institute of Technology, India and an MBA from University of Michigan, Ross School of Business.
Charu Sareen is a Sr. Product Manager for Amazon SageMaker Feature Store. Prior to AWS, she was leading growth and monetization strategy for SaaS services at VMware. She is a data and machine learning enthusiast and has over a decade of experience spanning product management, data engineering, and advanced analytics. She has a bachelor’s degree in Information Technology from National Institute of Technology, India and an MBA from University of Michigan, Ross School of Business.
 Frank McQuillan is Principal Product Manager for Amazon SageMaker Feature Store. For the last 10 years he has worked in product management in data, analytics and AI/ML. Prior to that, he worked in engineering roles in robotics, flight simulation, and online advertising technology. He has a master’s degree from the University of Toronto and a bachelor’s degree from the University of Waterloo, both in Mechanical Engineering.
Frank McQuillan is Principal Product Manager for Amazon SageMaker Feature Store. For the last 10 years he has worked in product management in data, analytics and AI/ML. Prior to that, he worked in engineering roles in robotics, flight simulation, and online advertising technology. He has a master’s degree from the University of Toronto and a bachelor’s degree from the University of Waterloo, both in Mechanical Engineering.