Artificial Intelligence
Using Amazon SageMaker with Amazon Augmented AI for human review of Tabular data and ML predictions
Tabular data is a primary method to store data across multiple industries, including financial, healthcare, manufacturing, and many more. A large number of machine learning (ML) use cases deal with traditional structured or tabular data. For example, a fraud detection use case might be tabular inputs like a customer’s account history or payment details to detect if a transaction is fraudulent. Other use cases could include customer churn detection or product demand forecasting. When using ML for tabular data use cases, you can now build in human reviews to aid in managing sensitive workflows that require human judgment.
A human in the loop workflow for such a use case might entail a human reviewer seeing all or some of the numerical features that the ML model uses as input in a static tabular format commonly known as dataframes, or several rows of model output that they may wish to modify dynamically. In the former case, developers building the worker UI for this use case might need to ingest a table directly into the UI as a static, immutable object. In the latter use case, you can ingest the table dynamically, in which the table is generated as part of the UI and a reviewer can modify it.
In this post, you use Amazon SageMaker to build, train, and deploy an ML model for tabular data, and use Amazon Augmented AI (Amazon A2I) to build and render a custom worker template that allows reviewers to view a static or dynamic table. Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly. Amazon SageMaker removes the heavy lifting from each step of the ML process to make it easier to develop high-quality models. Amazon A2I is a fully managed service that helps customers build human review workflows to review and validate the predictions of ML models. Amazon A2I removes the heavy lifting associated with building these human review workflows.
Other common use cases that may require human workflows are content moderation in image and video, and extracting text and entities from documents. Although you can use ML models to identify inappropriate content or extract entities, humans are often required to validate the model predictions based on the use case and the business context. Amazon A2I helps you quickly author and create these human workflows.
You can also use Amazon A2I to send a random sample of ML predictions to human reviewers. You can use these results to inform stakeholders about the model’s performance and to audit model predictions.
Prerequisites
This post requires you to create the following prerequisites:
- IAM role – To create a human review workflow, you need to provide an AWS Identity and Access Management (IAM) role that grants Amazon A2I permission to access Amazon Simple Storage Service (Amazon S3) for writing the results of the human review. This role also needs an attached trust policy to give Amazon SageMaker permission to assume the role. This allows Amazon A2I to perform actions per the permissions attached to the role. For example policies that you can modify and attach to the role you use to create a flow definition, see Enable Flow Definition Creation.
- Amazon SageMaker notebook instance – For instructions on creating an Amazon SageMaker notebook instance, see Create a Notebook Instance.
- S3 bucket –Create an S3 bucket to store the outputs of your human workflow. Record the ARN of the bucket—you need it in the accompanying Jupyter notebook.
- Private workforce – A work team is a group of people that you select to review your documents. You can choose to create a work team from a workforce, which is made up of workers engaged through Amazon Mechanical Turk, vendor-managed workers, or your own private workers that you invite to work on your tasks. Whichever workforce type you choose, Amazon A2I takes care of sending tasks to workers. For this blog you create a work team using a private workforce and add yourself to the team to preview the Amazon A2I workflow. For instructions, see Create a Private Workforce. Record the ARN of this work team—you need it in the accompanying Jupyter notebook.
- Jupyter notebook – This post uses a Jupyter notebook available on GitHub. For this blog, you use the UCI breast cancer detection dataset that is available within scikit-learn [1]. This dataset uses medical diagnostic data to predict a benign or malignant cancer outcome.
Training and deploying your model on Amazon SageMaker
The key steps for training and deployment include the following:
- Import the necessary libraries and load the dataset.
- Split the dataset into training and test datasets, and train an ML model. For this blog, you train a model using Amazon SageMaker’s built-in XGBoost algorithm to predict a binary outcome.
- Create an endpoint to generate sample inferences on the test data.
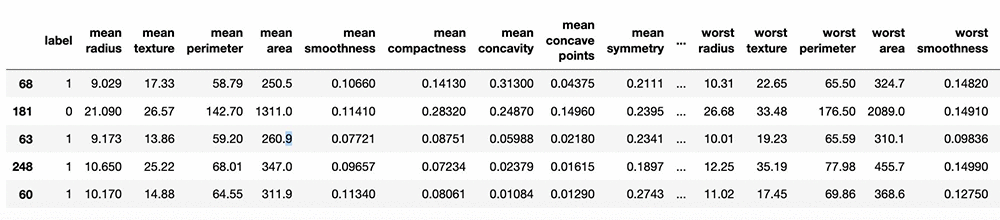
You import the data using the scikit-learn built-in utility for importing datasets and generate a training and test dataset for training your model and generating predictions. Scikit-learn provides a utility to split a dataset into train and test sets based on a fixed ratio (80:20 is typical in many data science applications) and a random state to ensure reproducibility. The dataset looks like the table in the following screenshot.
To train the model, you use the built-in XGBoost algorithm, which is a highly efficient and scalable gradient boosting tree algorithm for supervised learning. For more information, see how XGBoost works.
Follow the steps in the notebook to train the model. After you train the model, Amazon SageMaker fully manages the deployment and hosting of the model endpoint, as shown in the notebook. Amazon SageMaker builds an HTTPs endpoint for your trained model and can automatically scale if needed to serve traffic at inference time. After deploying the model, you can generate predictions. See the following code cell in accompanying notebook:
The cell’s output is an array of predictions: 1 or 0 for a malignant or benign prediction.
You’re now ready to incorporate the model outputs into the human loop workflow.
Creating the worker task templates, human review workflow, and human loops
The accompanying Jupyter notebook contains the following steps:
- Create a worker task template to create a worker UI. The worker UI displays your input data, such as documents or images, and instructions to workers. It also provides interactive tools that the worker uses to complete your tasks. For more information, see Create a Worker UI.
- Create a human review workflow, also referred to as a flow definition. You use the flow definition to configure your human work team and provide information about how to accomplish the human review task. You can use a single flow definition to create multiple human loops. For more information, see Create a Flow Definition.
- Create a human loop to start your human review workflow and send data for human review. For this blog, you use a custom task type and start a human loop using the Amazon A2I Runtime API. When you call
StartHumanLoopin your custom application, a task is sent to human reviewers.
Now let’s discuss how you can include tabular data in the worker task UI in more detail.
Including tables into the worker task UI
Amazon A2I uses Liquid for automating templates. Liquid is an open-source inline markup language that allows the inclusion of text within curly braces to create filters and instructions to control the flow.
For this blog, you want your reviewers to be able to look at the test data features to decide whether the model outputs are accurate. Now you’re ready to author your template. The template consists of two parts: a static table containing the test dataset features and a dynamic table containing your predictions that you can allow the user to modify.
You use the following template:
The task.input.table field allows you to ingest a static table into the worker task UI. The skip_autoescape filter allows the pandas table to be rendered as HTML. For more information, see Create Custom Worker Templates.
The task.input.Pairs field allows you to generate a table dynamically within the worker task UI. Because this table contains your predictions and requires human input, you can include both the radio button and text fields for the workers to agree or disagree with the model’s prediction, change the model prediction if needed, and provide a potential reason why they changed the prediction. This may be useful particularly in a regulated environment where compliance and regulations often limit the kinds of features that you can use in ML models to avoid potential model bias.
You also need to use the pandas utility, which allows you to convert a dataframe to HTML format. In the following example code snippet, you load in the first five rows of test data for your human reviewers to look at. For the dynamic part of the table, create a list with a row identifier and the actual model predictions from earlier.
You’re now ready to create the worker task template and human review workflow. See the following code snippet:
Start the human loop with the following code snippet:
Because you use a private workforce in this blog, the workers can open the link they received when you created the work team to visualize the generated UI.
Completing the human review
The following screenshot shows the worker UI.
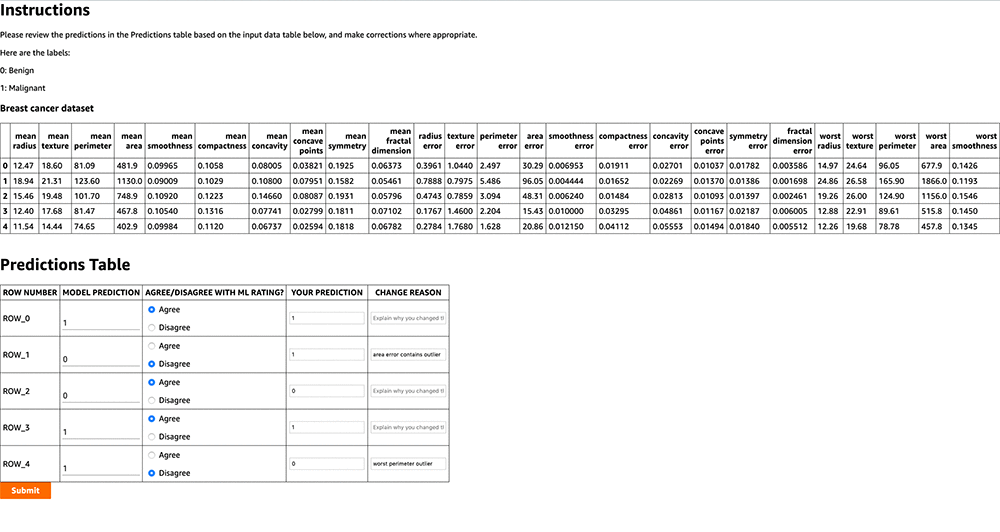
The top table is the pandas dataframe included as an HTML, and the Predictions Table is dynamically generated for all or a subset of the rows in your dataset. The Model Prediction field consists of the model inferences based on the corresponding row in the preceding test dataset. When the UI is generated, the User Rating opinion (Agree or Disagree), Your Prediction, and Change Reason fields are blank.
A worker selects the radio button to validate the model prediction as shown in the output, and provides their modified prediction. Optionally, workers can also enter the reason for their change (as shown in the preceding screenshot). This could help the data science team with any downstream model retraining. For example, if the worker rates a model as a false positive and provides a reason (such as one of the features could be an outlier), data scientists can remove this data point during model retraining to prevent the model overfitting to outliers.
After the worker rates the new predictions and submits their answers, you can visualize the outputs directly in Amazon S3. You can also visualize the results directly in your Amazon SageMaker notebook environment.
Looking at human-reviewed results
After you submit your review, the results are written back to the Amazon S3 output location you specified in your human review workflow. The following are written to a JSON file in this location:
- The human review response
- Input content to
StartHumanLoopAPI - Associated metadata
You can use this information to track and correlate ML output with human-reviewed output. See the following code snippet:
The ‘humanAnswers’ key provides insight into any changes the human reviewers made. See the following code snippet:
You can parse this JSON document to extract relevant outputs. You can also use these outputs from the human reviewers in the training dataset to retrain the model and improve its performance over time.
Cleaning up
To avoid incurring future charges, delete resources such as the Amazon SageMaker endpoint, notebook instance, and the model artifacts in Amazon S3 when not in use.
Conclusion
This post demonstrated two use cases for ingesting tabular data into human review workflows with Amazon A2I, covering both immutable and dynamic tables. This post has merely scratched the surface of what Amazon A2I can do. Amazon A2I is available in 12 Regions. For more information, see Region Table.
For video presentations, sample Jupyter notebooks, or information about use cases like document processing, content moderation, sentiment analysis, text translation, and others, see Amazon A2I Resources.
References
[1] Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
About the authors
 Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
 Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He is focusing on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.
Anuj Gupta is Senior Product Manager for Amazon Augmented AI. He is focusing on delivering products that make it easier for customers to adopt machine learning. In his spare time, he enjoys road trips and watching Formula 1.
 Sam Henry is the Software Development Manager for Amazon Augmented AI. He has spent the last 7 years at AWS developing products that combine human intelligence with machine learning, starting with Amazon Mechanical Turk. In his spare time, he enjoys studying history and birdwatching.
Sam Henry is the Software Development Manager for Amazon Augmented AI. He has spent the last 7 years at AWS developing products that combine human intelligence with machine learning, starting with Amazon Mechanical Turk. In his spare time, he enjoys studying history and birdwatching.