AWS Startups Blog
Digital Insight Scales Up or Down Rapidly for Their Bursty Inference Workloads
Guest post by Toby Miller, Technical Architect at Digital Insight and Sinan Erdem Startups Solutions Architect, AWS
At Digital Insight, we have built a platform for automated due diligence research. A client would typically need to assemble a holistic profile to aid a hiring or investment decision. It might be a legal requirement that they discover anything that could prohibit them from going through with the decision. Traditionally, this work would be done by an analyst, poring over search engine results, companies records, sanctions lists, and anything else they can find, looking for information about their subject. Our platform revolutionizes this work by automating it entirely. After entering a name and a piece of context, our system will produce a report in five minutes that describes the subject (and only the subject, no matter how common their name!) in the detail needed to make these decisions. It is cheap, fast, exhaustive, and unbiased, which makes it the perfect way to do due diligence.
The Problem
However, the technical challenge that sits underneath is enormous. The amount of data that must be collected and analyzed to create each report is vast (much greater than a human would ever be able to explore alone), and the compute resources required to do this must be provisioned in seconds in order to meet our five-minute goal. For that reason, the platform was built from the ground up to use AWS serverless infrastructure, specifically AWS Lambda, Amazon SQS, and Amazon DynamoDB. We often say that this startup would not have been viable before the advent of Lambda, as the cost of having all the resources we would need provisioned continuously would have been prohibitively expensive.
As we have developed the platform further, we have gradually encountered things that we could not do in Lambda. In this post, I will discuss a large piece of our infrastructure that has been plagued by this problem, although AWS Lambda Container Image Support, announced at re:Invent 2020, may put this to bed once and for all.
Much of the data we work with is structured, but any open-source research analyst would tell you that most insights are available through comprehension of articles and other unstructured writings, found generally through search engines. To be able to work with this data, we built a natural language processing (NLP) system called the Free Text Analyzer (FTA), and we use it to process every bit of text we find. I won’t go into too much detail of what it does internally except to say that it uses many different NLP tools in the course of its work, with new ones being added all the time. The reason we can’t run it in Lambda is the size of the models required by these tools, which would put the deployment package size well into the 10s of GBs, all of which would need to be loaded into memory before FTA could begin its work.
Our Architecture
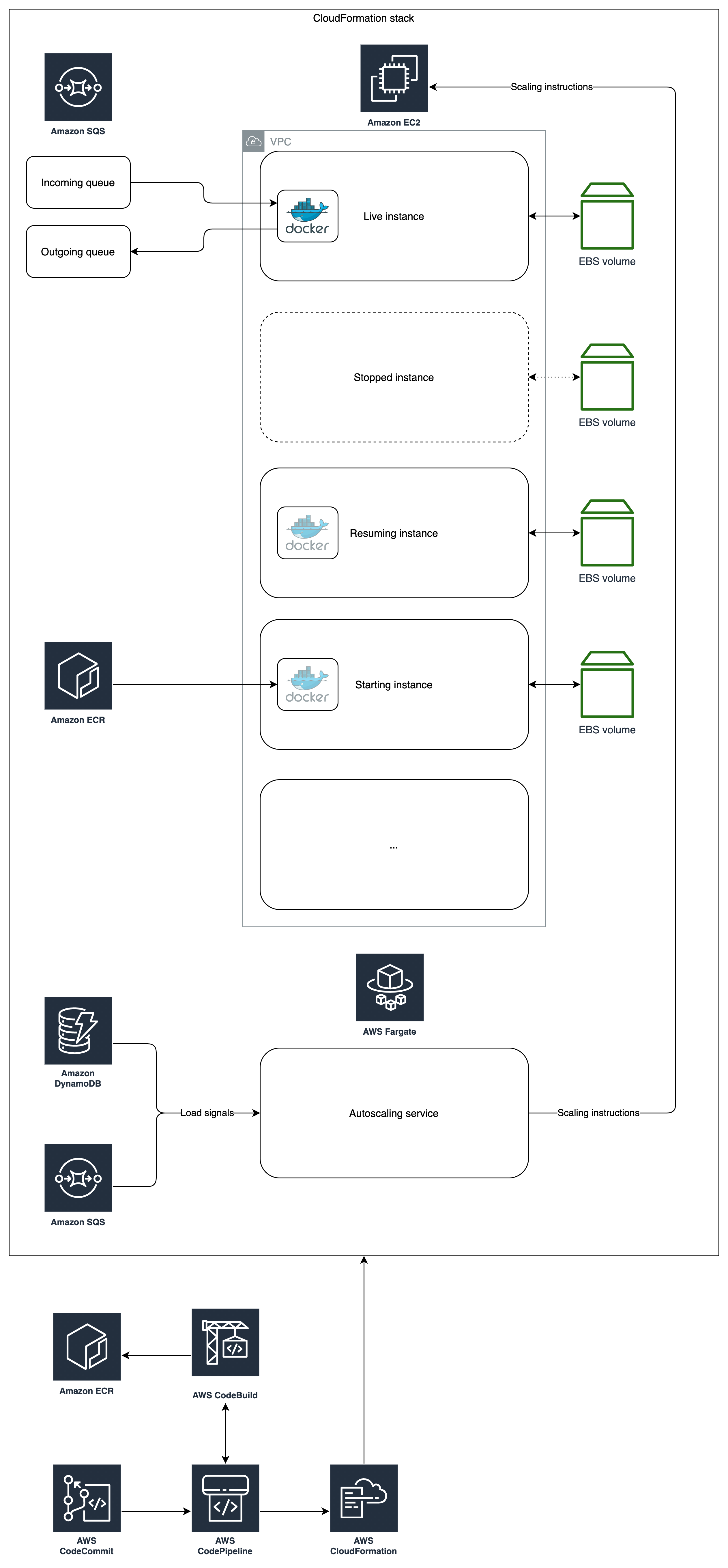
Our first attempt to deploy this behemoth was in AWS Fargate in Amazon Elastic Container Service (Amazon ECS). It seemed simple enough — we produce an enormous docker image in Amazon Elastic Container Registry (Amazon ECR), and tell Fargate to match the capacity to the number of jobs waiting to be processed by an SQS queue. Unfortunately, the process of pulling the container would generally take four or more minutes: fine for a conventional autoscaling microservice, but far too slow for us. Amazon ECR is backed by Amazon Simple Storage Service (Amazon S3), and there are some other combinations available here, such as launching a light docker image that pulls the models it needs from Amazon S3 at launch time. None of these options gave us the performance we needed, not least because S3 performance suffers if you pull the same object from multiple places at the same time: necessary to launch a cluster.
So we thought again. The main problem, it seemed, was that we weren’t in control of the hosting of the data, so we moved a layer back, to Amazon EC2 and AWS Auto Scaling. With this, we thought we would be able to host the large models on a networked machine, or split up in S3 for speed, or anywhere else, and cut the transfer time dramatically. Again it proved too slow, but for different reasons: every step of the journey from a job on an SQS queue to a running docker container of FTA added a 10-20s delay. The Amazon CloudWatch detailed metric we were running to watch the SQS queue size had a delay; the autoscaling group in EC2 had a delay in its response to the metric; starting an EC2 instance had a delay to launch into the AMI (even a light one); pulling the docker image, no matter how fast the network, would always take an irritatingly large amount of time; and then the launch of FTA could only go as fast as data could be loaded from disk into memory. Some of these steps could be optimized, but the bottom-line was never going to be less than two minutes or so, which was close to viable, but not quite there. The best cases here also involved standing costs for machines holding the images ready to distribute, which were small, but still a sting in the tail from a solution that was only nearly fast enough.
With the help of the AWS Solutions Architecture team, we realized that the answer could lie in stopping and restarting EC2 instances. We hadn’t considered it before because AWS Auto Scaling doesn’t permit it but if we were prepared to build our own autoscaling system, we could do what we liked.
The idea was that at launch, an instance would pull the docker image from ECR as normal (taking as many minutes as it needs), and once fully launched, our autoscaling service would notice that it was healthy, and allow it to shut down, with all its state kept safe in an Amazon Elastic Block Store (Amazon EBS) disk. We would have a pool of these stopped instances, and the moment there was a hint that some FTA resource might be required, we could start them all, and they could begin loading their models into memory almost immediately. By using our own service rather than AWS Auto Scaling, we were free to use an SQS queue as the source of autoscaling triggers rather than a CloudWatch metric, which cut another of the delays. In the end, we also used DynamoDB to record ongoing requirements for FTA capacity, so our fast-response triggers came from SQS, and after a short cool down, DynamoDB could be used to tell when we were free to release the capacity again.
This approach eliminated most of the standing cost of running live FTA instances continuously, but didn’t come completely free. We determined that the optimal Amazon EBS disks, to trade off cost against burst speed (required for loading the models into memory quickly), would be gp2 disks with 171GB capacity. At that size, we would get the full 250MB/s read performance at the critical moment. The disks continue to be charged as long as they are provisioned, which meant that we still needed to be careful with the size of the pool, as each one extra would add to our standing costs. We had certainly accomplished one objective though, which was to keep the standing cost from being much larger than the short-term costs of running the EC2 instances in the cluster on demand.
The design of the autoscaling service had to be considered carefully. As usual, we found that building something yourself rather than relying on a tried and tested third party solution often spawns unforeseen complexities. We had to make sure, for example, that unhealthy instances were reported, terminated, and replaced. We had to guarantee that after a change in the Amazon CloudFormation template that defines the instances, any old instances would be replaced gracefully, and that if a bug were pushed to the development environment that prevented FTA from starting, we wouldn’t get into an expensive boot loop.
An interesting problem that we encountered relates to the fact that AWS does not guarantee the availability of EC2 instance types, whether launching from scratch, or starting a stopped instance. Initially we let EC2 choose the availability zone into which our instances were first launched in the hope that it would decrease the chance of them being unavailable. The consequence of this was that EC2 would usually put all the instances in the pool into a single Availability Zone (AZ), and when they might come to be started later, that AZ might be all out of capacity in our instance type (which happened to be a rare GPU machine) and we would be left with nothing. After that we made sure to tell EC2 exactly where we wanted our instances, and distribute them as evenly as possible across all AZs. With that in place, it would take EC2 to be out of capacity in all AZs for us to have an outage. This is perhaps not unimaginable, especially if everyone else is doing what we’re doing, but at least unlikely. We also introduced a few worst-case mitigations, including starting new instances of different instance types, and communicating to users that our system could take longer to produce reports than usual.
Looking to the Future
With our new autoscaling system in place, we were able to launch a full cluster of FTA instances in around 90 seconds, much less than other approaches offered, and a time which supports the performance we promise to our users. With Lambda Container Support, we hope to be able to do even better, by splitting FTA into as many smaller parts as possible and fitting them each into a 10GB docker container to run quickly in Lambda. That said, there will always be situations where we need a large amount of data on a newly-provisioned instance fast, and this autoscaling service offers us as much flexibility as we could hope for in delivering that.
AWS re:Invent 2020 also brought new EBS volume types, and we’re excited to try gp3, which could offer up to four times the performance of gp2 without being much more expensive. In fact, for the same cost as our current gp2 disks, we could get gp3 disks with twice the performance by cutting the size of the disk to the 20GB we actually use, rather than provisioning 171GB to get the maximum burst throughput of gp2.