AWS Storage Blog
Automate and centrally manage data protection for Amazon S3 with AWS Backup
Customers globally, especially in regulated industries, require centralized protection and demonstrable compliance for their application data. Centralized data protection and enhanced visibility across backup operations can reduce the risks of costly disasters and accidents, improve business continuity, and simplify the auditing process. With AWS Backup for Amazon S3 now being generally available, you can centralize data protection for your application data stored in Amazon S3 alongside other AWS services for storage, compute, and databases and meet your business continuity goals.
You can create periodic and continuous backups of your S3 bucket contents, including object data, object tags, access control lists (ACLs), and other user-defined metadata. For both backup types, the first backup is a full backup, while subsequent backups are incremental backups. AWS Backup’s continuous backup capability uses an event-driven mechanism to continuously capture incremental changes in your S3 data, and it allows you to restore your S3 buckets or objects to any specified point-in-time in the past 35 days. Continuous backups are useful for undoing accidental deletions, while periodic backups help you meet your long-term data retention needs. You can restore both continuous and periodic backups of an S3 bucket, a prefix, or an S3 object to a new or existing S3 bucket.
Using AWS Backup Vault Lock and the seamless integration with AWS Organizations, you can create independent, immutable, and encrypted backups across multiple AWS accounts. AWS Backup allows you to centrally manage backups and restores of S3 bucket contents across all of your AWS accounts.
Using AWS Backup for Amazon S3
Read the previous preview launch blog post on how to use AWS Backup for Amazon S3. In this blog post, we highlight three scenarios where you can benefit from AWS Backup for Amazon S3. Figure 1 describes how AWS Backup works.
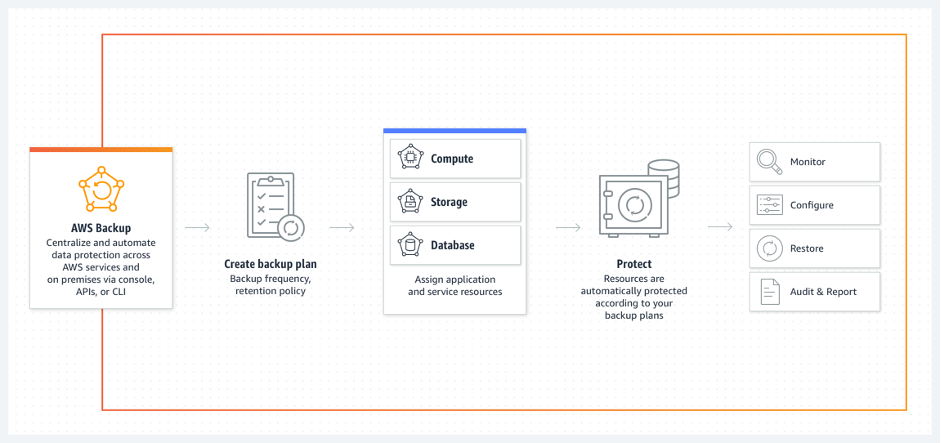
Figure 1: AWS Backup How-it-works diagram
Scenario 1: Amazon S3 bucket used in an application that needs point-in-time recovery of individual objects
You have an app that generates and deletes lots of data from an S3 bucket across a 14-day application cycle period. Your support team needs to quickly get access to a few S3 objects from a particular point in time in the last 14 days to complete their operational or troubleshooting task.
Retrieving individual objects to a point-in-time can be a cumbersome task. However, AWS Backup for Amazon S3 makes it easy to recover individual objects, without having to restore the entire S3 bucket. With a few simple clicks in the AWS Backup management console or with a single API call, you can restore your continuous backups to any specific point-in-time in the past 35 days and recover the S3 objects you want.
Scenario 2: Restore contents of an Amazon S3 bucket based on an accidental deletion event
You have an application that uses the same S3 bucket for multiple test or development environments and contains static data assets (for example, dev and test). One of the development teams accidentally deletes thousands of these static data assets, and they don’t know which files they deleted. They need an easy solution to recover a copy of the S3 bucket that contains all their static data assets, so that they can continue with their work.
AWS Backup for Amazon S3 lets you easily restore entire contents of an S3 bucket into an existing or new bucket in a simple and automated manner. It removes the complexity of searching for each individual object and performing separate restores.
Scenario 3: Recovery solution for enterprise data lakes
Amazon S3 is the largest and most performant object storage service for structured and unstructured data, and the storage service of choice to build a data lake. You need to protect your data lakes against data disruption events like malicious or accidental deletion.
Using AWS Backup for Amazon S3 and its Backup Vault Lock feature, you can define data protection policies to create independent immutable backup copies of your data stored in an S3 data lake. This will help provide a mechanism to protect data in your data lake against accidental deletions and malicious re-encryption.
Added benefits
Now that you can configure Amazon S3 backups using AWS Backup, let’s go through a few dimensions and the benefits AWS Backup can provide for data stored in your Amazon S3 Buckets.
Performance
The event-driven incremental backups and continuous protection capabilities of AWS Backup for Amazon S3 provides significant improvements over a traditional catalog-based tracking mechanism. The always incremental nature of the backup ensure that only object changes are captured across backups reducing storage costs.
Security
You can set up multiple layers of data protection in AWS Backup, separate resource access policies, and long-term data retention. Using AWS Backup Vault Lock, you can prevent any user from deleting your backups or changing your specified retention periods, and have an additional layer of data protection to protect backups from inadvertent or malicious actions. Implement these safeguards to ensure you are storing your backups using a Write-Once-Read-Many (WORM) model. Note that AWS Backup Vault Lock has not yet been assessed for compliance with the Securities and Exchange Commission (SEC) rule 17a-4(f) and the Commodity Futures Trading Commission (CFTC) in regulation 17 C.F.R. 1.31(b)-(c).
Reporting and observability
You can enable real-time alerts, notifications, and raw reporting data that your team can act on quickly if needed using Amazon CloudWatch and AWS CloudTrail events. Additionally, customer can use the backup observer tool for AWS Backup that we created. The tool enables customers to automatically obtain daily aggregated cross-account multi-region–based AWS Backup reports and rich visualization dashboards.
Recovery orchestration
A well-documented backup and recovery strategy for data includes regular testing and is becoming more of a focus for the modern enterprise. AWS Backup also provides native APIs that can be used to help automate backups, recovery drills, and orchestrate recovery of S3 data as part of your compliance plan.
In the data lake scenario, imagine you had to restore some files from your Amazon S3 based data lake (for example, for bi-yearly restore testing or a recovery requirement). You would use AWS Backup for Amazon S3 to restore your selected S3 objects from a particular recovery point to a target S3 bucket location with a few clicks. AWS Backup restore activities are recorded in a restore report, stored in your selected Amazon S3 bucket, ready to be provided to anyone who needs it.
Availability and pricing
AWS Backup for Amazon S3 is now generally available in all commercial AWS Regions where AWS Backup is available. For more information, see the AWS Regional Services List.
For more information on the detailed pricing, consult the AWS Backup pricing page.
Conclusion
AWS Backup for Amazon S3 provides a single pane of control to automate the backup and recovery of your S3 buckets based on your organization’s data protections requirements.
Learn more about this new feature on the AWS Backup documentation page. Let us know how you plan to use AWS Backup for Amazon S3 in the comments section.