AWS News Blog
Preview – AWS Backup Adds Support for Amazon S3

|
Starting today, you can preview AWS Backup for Amazon Simple Storage Service (Amazon S3).
AWS Backup is a fully managed, policy-based service that lets you to centralize and automate the backup and restore of your applications spanning across 12 AWS services: Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Block Store (Amazon EBS) volumes, Amazon Relational Database Service (Amazon RDS) databases (including Amazon Aurora clusters), Amazon DynamoDB tables, Amazon Neptune databases, Amazon DocumentDB (with MongoDB compatibility) databases, Amazon Elastic File System (Amazon EFS) file systems, Amazon FSx for Lustre file systems, Amazon FSx for Windows File Server file systems, AWS Storage Gateway volumes, and now Amazon S3 (in preview).
Modern workloads and systems are leveraging different storage options for different functionalities. In the 21st century, it is normal to build applications relying on non-relational and relational databases, shared file storage, and object storage, just to name of few. When operating and managing these applications, you told us that you wanted centralized protection and provable compliance for application data stored in S3 alongside other AWS services for storage, compute, and databases.
I can see three benefits when integrating Amazon Simple Storage Service (Amazon S3) with your data protection policies in AWS Backup.
First, it lets you centrally manage your applications backups: AWS Backup provides an automated solution to centrally configure backup policies, thereby helping you simplify backup lifecycle management. This also makes it easy to ensure that your application data across AWS services (including S3) is centrally backed up.
Second, it lets you easily restore your data: AWS Backup provides a single-click-restore experience for your S3 data. This lets you perform point-in-time restores of your S3 buckets and objects to a new or existing S3 bucket.
Finally, it improves backup compliance: AWS Backup provides built-in dashboards that let you to track backup and restore operations for S3.
AWS Backup for S3 (Preview) lets you create continuous point-in-time backups along with periodic backups of S3 buckets, including object data, object tags, access control lists (ACLs), and user-defined metadata. The first backup is a full snapshot, while subsequent backups are incremental. If there is a data disruption event, then you choose a backup from the backup vault, and restore an S3 bucket (or individual S3 objects) to a new or existing S3 bucket. AWS Backup is integrated with AWS Organizations, which let you use a single policy across AWS accounts (within your Organizations) to automate backup creation and backup access management.
Furthermore, you can turn on AWS Backup Vault Lock to enable delete protection of the data that you protect with AWS Backup, and thereby improving protection of your immutable backups from accidental deletion or malicious re-encryption.
How to Get Started
AWS Backup works with versioned S3 buckets. Before you get started, turn on S3 Versioning on your buckets to backup.
I must enable S3 in AWS Backup Settings when I use this feature for the first time. Using the AWS Management Console, I navigate to AWS Backup, then select Settings and Configure resources. I enable S3, and select Confirm. This is a one-time operation.
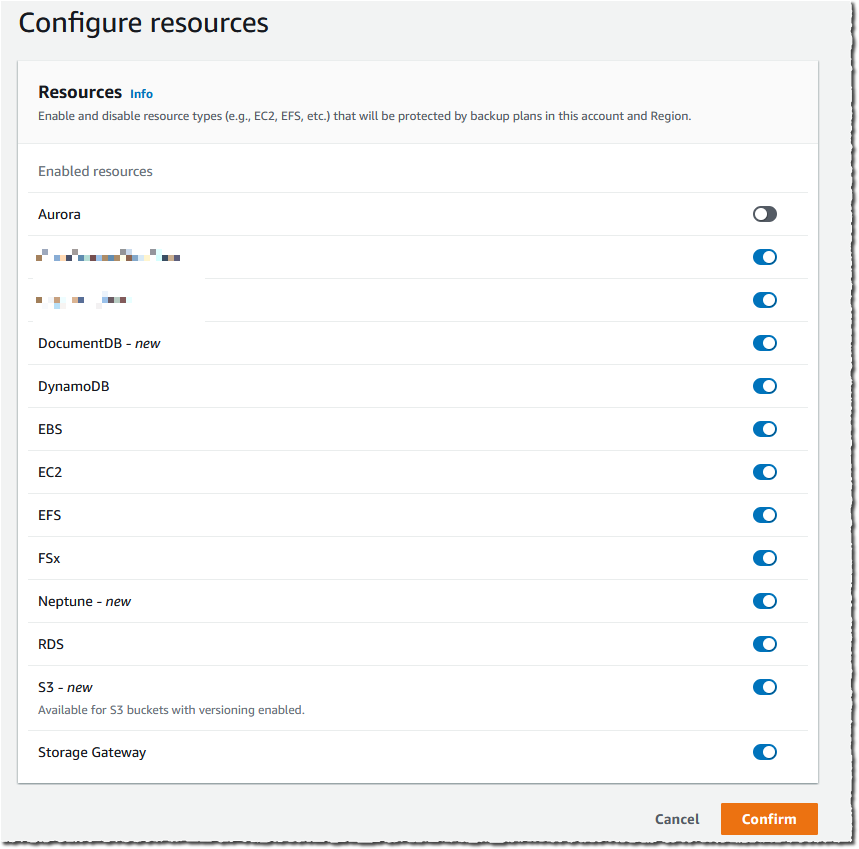
For this demo, I already have an existing backup plan, and I want to add an S3 bucket to this plan. If you want to create a new backup plan, then you can refer to AWS Backup‘s technical documentation.
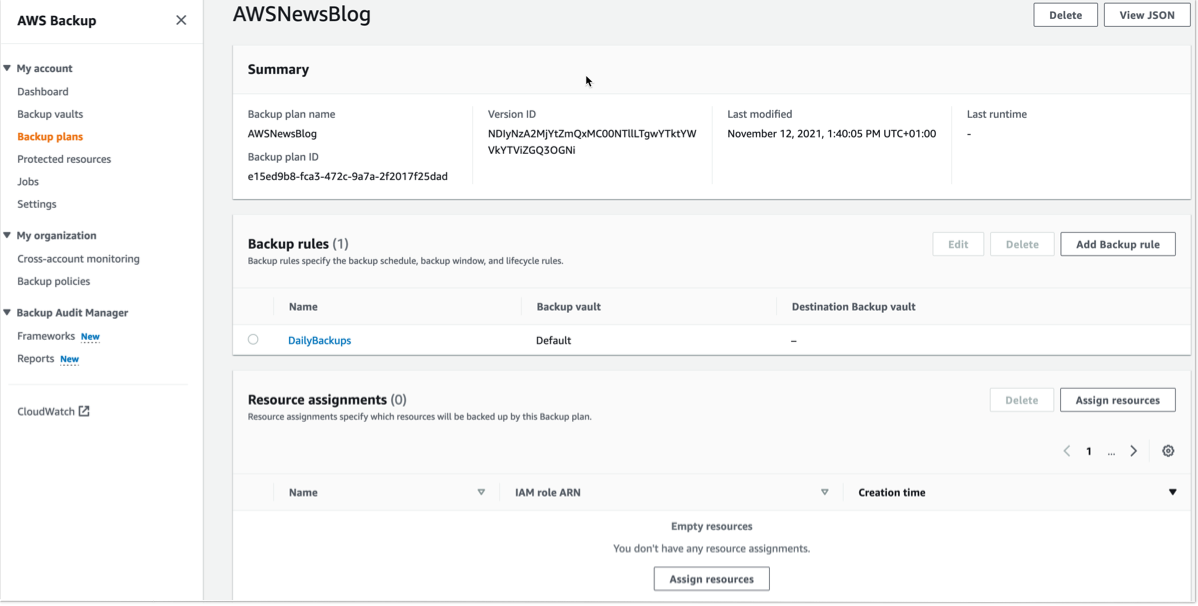
To start including my S3 objects in my backup plan, I open the AWS Management Console, navigate to Backup plans, and select Assign resources.
I give a name to my Resource assignment. I select Include specific resources types, then I select S3 as Resource type and one or several S3 Bucket names. When I am done, I select Assign resources.
Alternatively, I may use tags or resource IDs to assign S3 resources.
If you have thousands of S3 buckets, I recommend using tags to assign the S3 buckets to a backup plan. AWS Backup matches the tags in S3 buckets to the ones assigned to the backup plan, and it centrally backs up the S3 resources along with other AWS services that your application uses.
The other options are not different from what you know already.
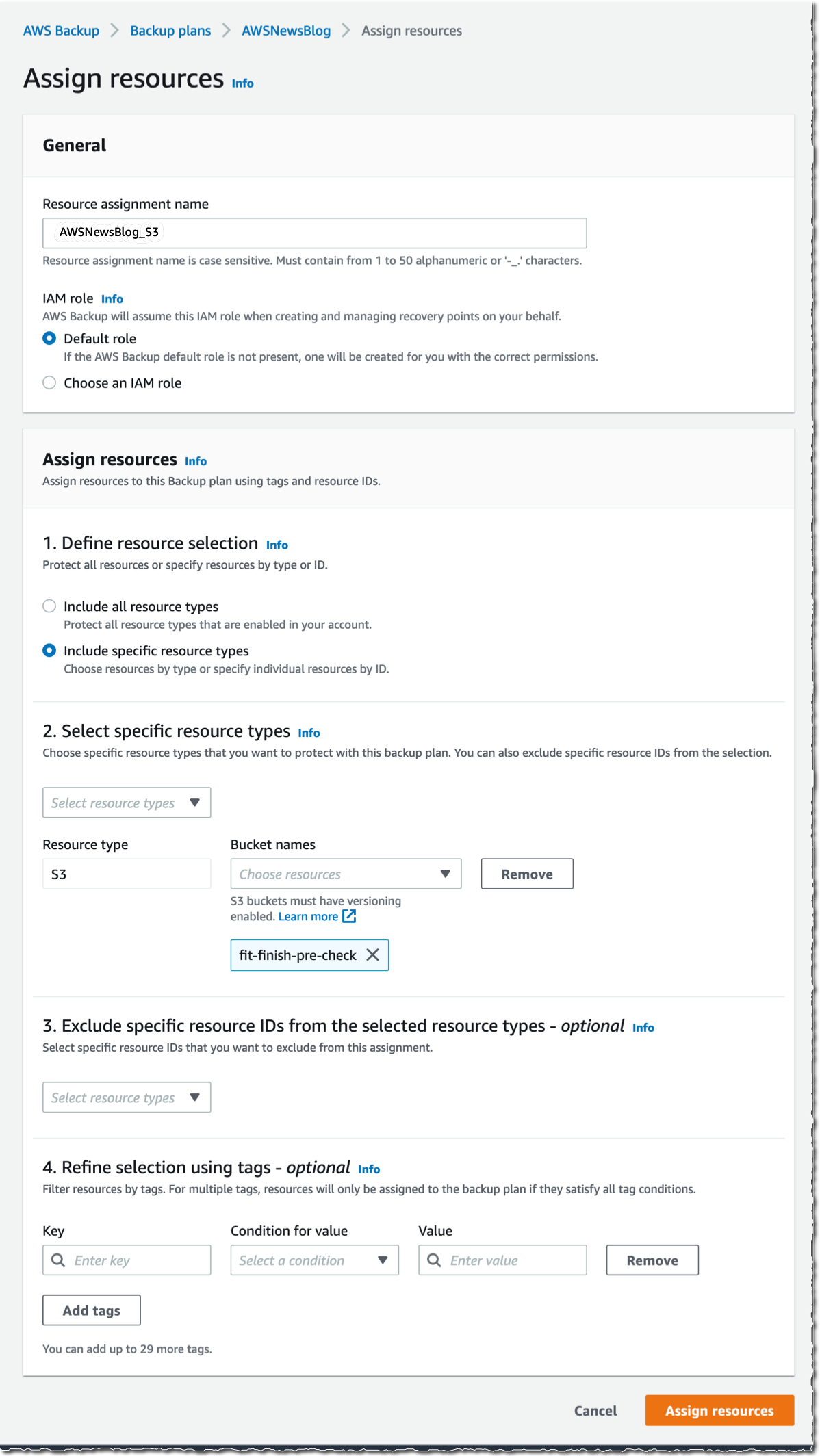
The Bucket names list in the previous screenshot only shows the S3 buckets in the same Region.
Alternatively, I may also create on-demand backups. I navigate to the Protected resources section, and select Create on-demand backup.
I select S3 as the Resource type, and select the Bucket name. As per usual, I choose a Backup Window, a Retention period, a Backup vault, and an IAM role. Then, I select Create on-demand backup.
 After a while, depending on the size of my bucket, the backup is ✅ Completed.
After a while, depending on the size of my bucket, the backup is ✅ Completed.
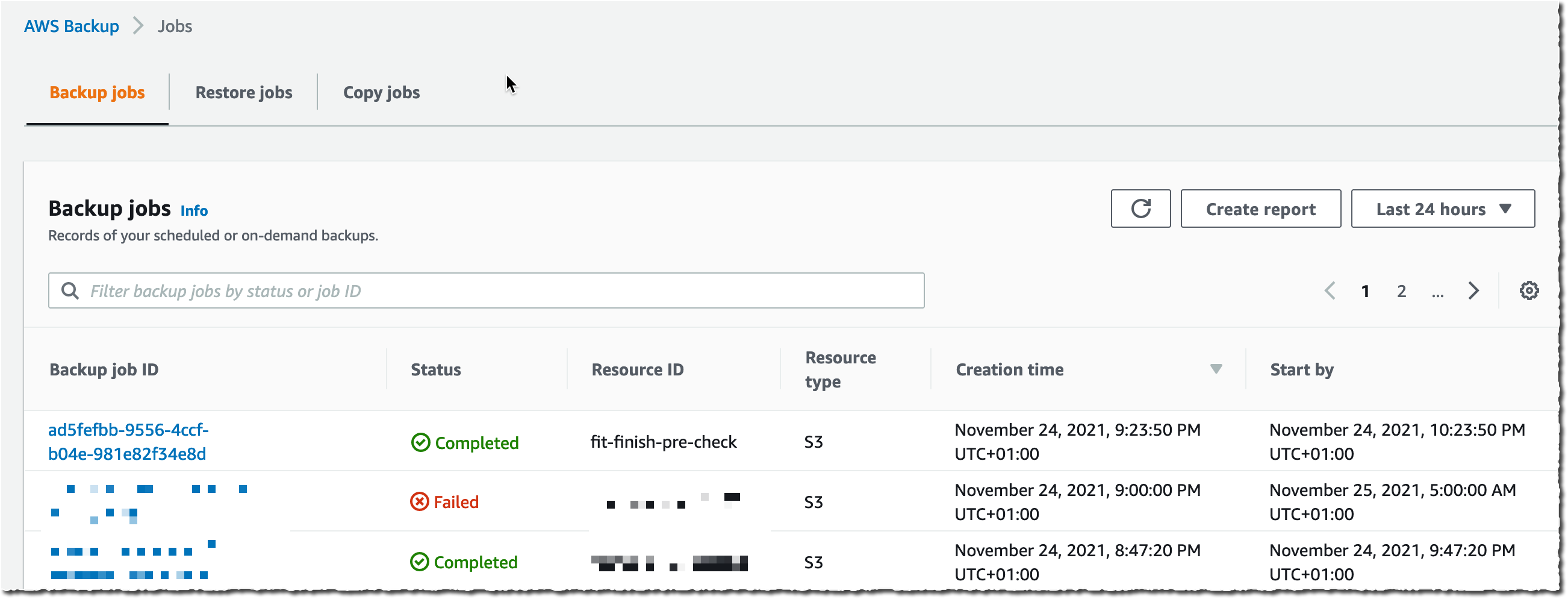
All of the backups are encrypted and stored securely in a backup vault that I selected in the backup plan.
A backup vault (or backup storage vault) is an encrypted logical construct in my AWS account that stores and organizes my backups (recovery points). I may create new backup vaults in every AWS Region where AWS Backup is available. I may enable AWS Backup Vault Lock (delete-protection capability) on the backup vault to avoid accidental deletions and prevent malicious actors from re-encrypting my data. AWS Backup stores my continuous backups and periodic snapshots in the backup vault of my preference, and it lets me browse and restore as per my requirements.
How to Restore Objects
Let’s try to restore this backup.
The restore operation is very flexible. I may restore entire S3 buckets or individual S3 objects. I may restore the backups to the source S3 bucket, or to another existing bucket. Furthermore, I may create a new S3 bucket during restore. The S3 buckets must have Versioning enabled. Also, I may change the encryption key during restore.
I navigate to Backup vaults to restore the S3 bucket I just backed up. In the Backups section, I select the Recovery point ID that I want to restore, and I select Restore from the Actions menu.

Before starting the restore, I may select a few options:
- The Restore time: I may restore my continuous backup to a point-in-time in the last 35 days, while I can restore my periodic backups to their original state.
- The Restore type: I may choose to restore the entire bucket or a subset of objects within it.
- The Restore destination: I may choose to restore on the same bucket, on another one, or create a new bucket during restore.
- The Restored object encryption: this lets me select the key I want to use to encrypt the restored objects in the bucket.
I select Restore backup to start the restore.
 I can monitor the progress in the Jobs section, under the Restore jobs tab.
I can monitor the progress in the Jobs section, under the Restore jobs tab.

When the status turns green to ✅ Completed, my objects are ready to use!
Generally, the most comprehensive data-protection strategies include regular testing and validation of your restore procedures before you need them. Testing your restores also helps to prepare and maintain recovery runbooks. In turn, that ensures operational readiness during a disaster recovery exercise, or an actual data loss scenario.
Availability and Pricing
The preview is available in the US West (Oregon) Region only.
During the preview, there are no charges for creating and storing backups. You will pay the AWS charges for underlying resources, such as S3 storage, API usage, and versioning.
Send us an email at s3-backup-preview@amazon.com including your AWS account ID to register for the preview.
Go ahead and apply to the preview program today.
— seb