AWS Storage Blog
Derive intelligent storage insights using S3 Metadata and Model Context Protocol (MCP)
Organizations face mounting challenges in managing and operationalizing their ever-growing data assets for machine learning and analytics workflows. When dealing with billions and trillions of objects, teams struggle to find what data they have and how to efficiently find specific datasets. Without proper data discovery and metadata management, teams spend valuable time searching for relevant datasets, leading to reduced productivity, missed opportunities, and difficulty in maintaining effective data governance practices.
Amazon S3 Metadata, combined with the MCP Server for Amazon S3 Tables, provides a comprehensive solution for automated data discovery and intelligent interaction with your data. This integration automatically captures and organizes metadata while enabling natural language interactions with your datasets, eliminating the need for specialized query language expertise. The solution leverages Amazon Q Developer for CLI as a conversational interface, making data exploration accessible to users across all technical skill levels.
This post will provide you step-by-step guidance on how to implement a conversational AI solution that transforms how you discover and interact with your data in Amazon S3. You’ll learn to set up S3 Metadata tables, configure the MCP Server for S3 Tables, and use Amazon Q Developer CLI to query your data using natural language. By following this guide, you’ll be able to create an intelligent data discovery experience that democratizes data access across your organization, improves data visibility, and enables faster, more informed decision-making through intuitive data exploration.
Use cases and solution overview
Follow along with this post to learn how to analyze metadata across S3 buckets to review storage distribution, observe lifecycle patterns, and analyze your security posture for auditing purposes, all using natural language queries. Storage admins and data engineers can gain insights into their Amazon S3 data through detailed analytics, such as tracking storage distribution to optimize costs, monitoring object patterns to improve lifecycle policies, enforcing encryption for security compliance, and analyzing metadata usage to enhance data organization. This information facilitates use cases such as building training datasets by querying on tags and user-defined metadata from specific time periods, identifying data for archival decisions, or generating real-time reports for compliance audits.
Prerequisites
The MCP Server for S3 Tables, by default, operates in the read-only mode. We recommend that you practice the principle of least privilege and grant only the permissions necessary for your AI assistant to function as per your requirements. This means that you should explicitly deny permissions to delete operations on your table buckets or tables using access control policies with AWS Identity and Access Management (IAM) or S3 Tables resource policies for roles that you want the AI assistants to assume. To perform create and append operations, you must explicitly configure the MCP Server with the necessary IAM permissions and AWS profile and use “–allow-write” on S3 Tables using the MCP Server.
Before getting started with the MCP Server for S3 Tables, you’ll need:
- An AWS account.
- Install AWS Command Line Interface (AWS CLI) and set up credentials.
- Configure S3 Metadata to create a journal and a live inventory table.
- Set up correct IAM permissions. To simulate and follow through the steps demonstrated in this demo, you can create a similar user and attach the following IAM policy to the IAM role that you use. This policy provides explicit permissions to create, update, and delete S3 Metadata configurations and query S3 Metadata tables.
Note: Whenever you use IAM policies, make sure that you follow IAM best practices. For more information, review Security best practices in IAM in the IAM User Guide. Remember to replace the S3 bucket name and account ID. - Install prerequisites and setup as per awslabs.s3-tables-mcp-server readme.
- Install and configure Amazon Q with AWS credentials.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PermissionsToWorkWithMetadataTables",
"Effect": "Allow",
"Action": [
"s3:CreateBucketMetadataTableConfiguration",
"s3:GetBucketMetadataTableConfiguration",
"s3:DeleteBucketMetadataTableConfiguration",
"s3:UpdateBucketMetadataJournalTableConfiguration",
"s3:UpdateBucketMetadataInventoryTableConfiguration",
"s3tables:*",
"kms:DescribeKey"
],
"Resource": [
"arn:aws:s3:::<s3 bucket(s) configured for S3 Metadata>",
"arn:aws:s3tables:us-east-1:<account id>:bucket/aws-s3",
"arn:aws:s3tables:us-east-1:<account id>:bucket/aws-s3/table/*"
]
}
]
}End-to-end demo workflow
In this section, we run natural language prompts to interact with S3 Metadata tables. When you’ve completed the prerequisites, to get started you need to type “q chat” in your favorite terminal program.
1. Initialize and load MCP Server for S3 Tables
With the Amazon Q chat prompt, Amazon Q initializes and loads the MCP Server for S3 Tables. This shows that the MCP server has loaded. To check if it has loaded on the next prompt provide/tools. This loads all of the tools available to you through s3-tables-mcp-server. The following image shows the Amazon Q initialization screen.
2. Find S3 Metadata tables
We can share with Amazon Q which buckets are of interest to us. All of your S3 Metadata tables are stored in an AWS managed table bucket called aws-s3 in each AWS Region. Therefore, we ask it to look in the AWS managed table bucket to find the live inventory tables for S3 Metadata, as shown in the following figure.

3. Start analyzing storage using Amazon Q and MCP Server for S3 Tables
Now that Amazon Q knows the buckets in the us-east-2 Region with S3 Metadata enabled, you can ask questions about these buckets. You can ask Amazon Q questions to assess the storage landscape and take storage management actions such as apply lifecycle policies objects that match specific criteria, delete specific objects, or tag objects different. The following is a list of suggestive storage management questions:
- Total storage used by objects across storage classes per bucket
- Largest files with their encryption status
- Buckets with highest object count in Standard storage class by age
- Objects created in the last 30 days with uploader identity
- Objects with specific tag key-value pairs
- Distribution of checksum algorithms across objects
In this example, we want to find out how much storage is being used by objects in each storage class so we can identify opportunities to move our storage to colder storage classes for cost optimization. We asked Amazon Q to analyze all of our buckets with metadata to find storage by storage class, as shown in the following figure.
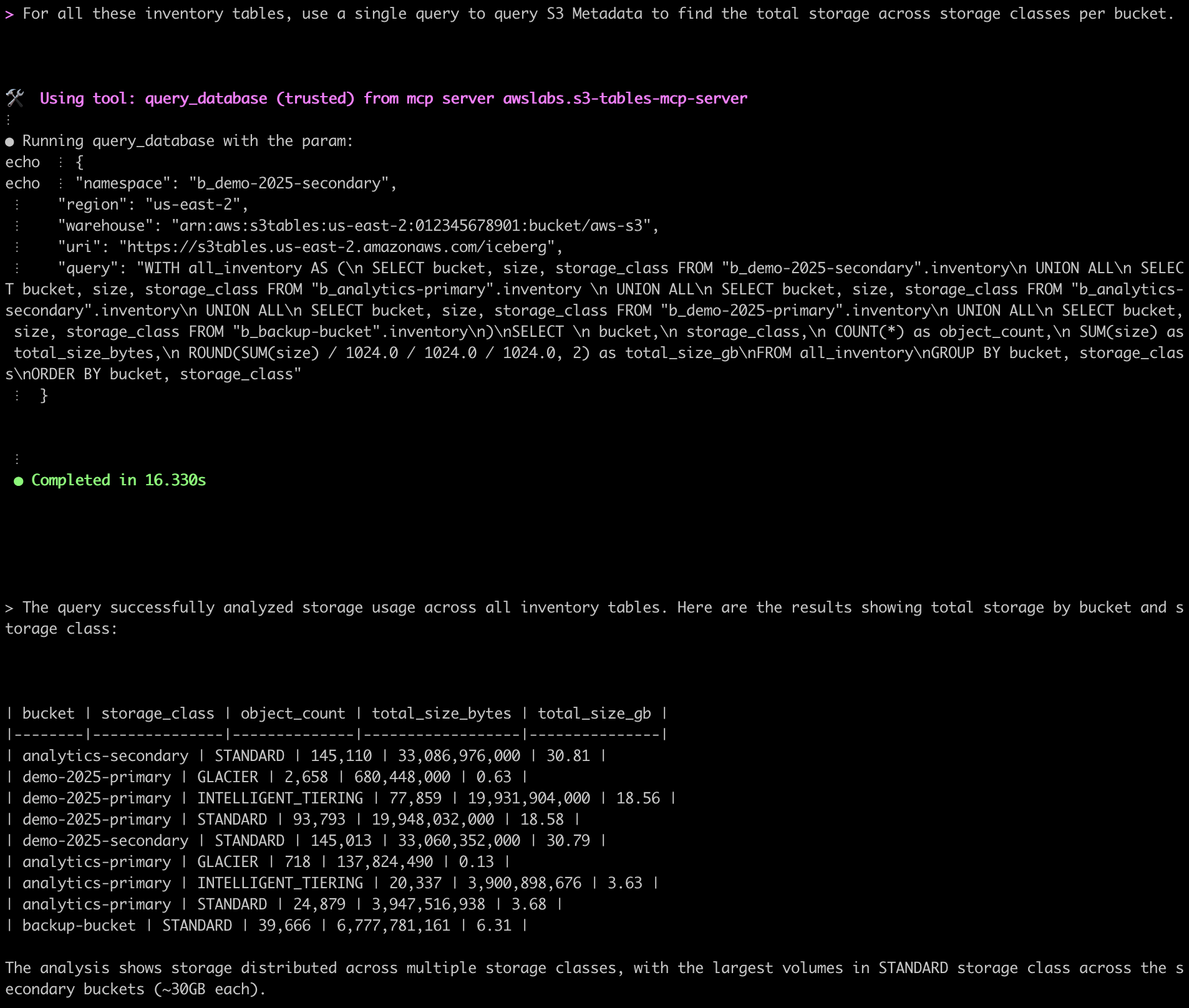
Based on these results, we have at least two buckets where data is not moving into colder storage classes. We can now choose to enable lifecycle actions on these buckets so that we can further optimize our costs.
4. Analyze objects for sensitive data
Next, let’s examine a security scenario where we want to identify objects containing personally identifiable information (PII) across your S3 buckets. This helps determine if the bucket’s access permissions need to be reviewed. We have previously tagged objects with sensitive content as “pii”. We’ll use Amazon Q to perform a comprehensive scan across our buckets to find the bucket that have sensitive objects. The following image shows results of a data discovery query across S3 Metadata inventory tables using tags.
![Screenshot of Q chat prompt: Look at these same inventory tables and run a single query to find objects that have the tag [‘pii’] = true’. Q responds With details about which buckets have objects with these tags with pii = true.](https://d2908q01vomqb2.cloudfront.net/e1822db470e60d090affd0956d743cb0e7cdf113/2025/10/06/Blog_Metadata_4.png)
Based on this information, we can now audit the tagged objects in the known prefixes to enforce the right access control policies.
As we’ve shown through our example, the unique metadata fields available in S3 Metadata—such as requester information, source IP addresses, detailed encryption status, and event tracking—combined with the MCP Server’s query capabilities, unlock insights that were previously difficult or time-consuming. This is a lot more that can be explored with Amazon Q and the MCP Server for S3 Tables. You can assess storage by tags, object keys, encryption types, user-defined metadata, and much more! Try some yourself.
Conclusion
In this post, we demonstrated how combining Amazon S3 Metadata with the MCP Server for S3 Tables creates a powerful solution for conversational data discovery. Organizations can use the comprehensive object tracking capabilities of S3 Metadata alongside the MCP Server’s natural language interface to interact with their datasets through conversations rather than complex SQL queries.
This integration addresses a fundamental challenge in modern data management. Although Amazon S3 provides virtually unlimited storage capacity for use cases such as archives, analytics, and data lakes, managing and discovering insights from billions or trillions of objects necessitates intelligent approaches. S3 Metadata automatically captures rich metadata about your objects—such as system properties, custom tags, user metadata, and event information—while the MCP Server for S3 Tables makes this wealth of information accessible through natural language interactions.
The solution enables organizations to achieve critical business objectives such as understanding usage patterns, verifying security posture, increasing operational efficiency, driving down costs, and making informed decisions about data migration or lifecycle management. Whether you’re a data engineer exploring data lineage, a business analyst investigating storage costs, or a security professional auditing access patterns, this conversational approach democratizes data discovery across technical skill levels.