AWS Big Data Blog
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.
If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Amazon Redshift as your data warehouse, you may want to integrate the two for a lake house approach. Lake House is the ability to integrate Data Lake and Data warehouse seamlessly. When you need to query your data lake from your Amazon Redshift Data warehouse, you can use Amazon Redshift Spectrum, which works great in unifying your data lake and data warehouse. However, when you use Athena in the data lake and need to access data in Amazon Redshift for the following two scenarios which are commonly seen, there is no easy approach:
- Team A has a data lake in Amazon S3 and uses Athena. They need access to the data in an Amazon Redshift cluster owned by Team B.
- Analysts using Athena to query their data lake for analytics need agility and flexibility to access data in an Amazon Redshift data warehouse without moving the data to Amazon S3 Data Lake.
In these scenarios, Athena federation with Amazon Redshift allows you to seamlessly access the data in your Amazon Redshift data warehouse without having to wait to unload the data to the Amazon S3 data lake, which removes the overhead in managing such jobs.
In this post, you walk through a step-by-step configuration to set up Athena federation using Lambda to access data in Amazon Redshift. You also see a performance benchmark analysis of interactive and ad hoc TPC-DS queries, and learn some key performance considerations and best practices when using federation.
Solution overview
Data federation is the capability to integrate data in another data store using a single interface. The following diagram depicts how Athena federation works by using Lambda to integrate with a federated data source.
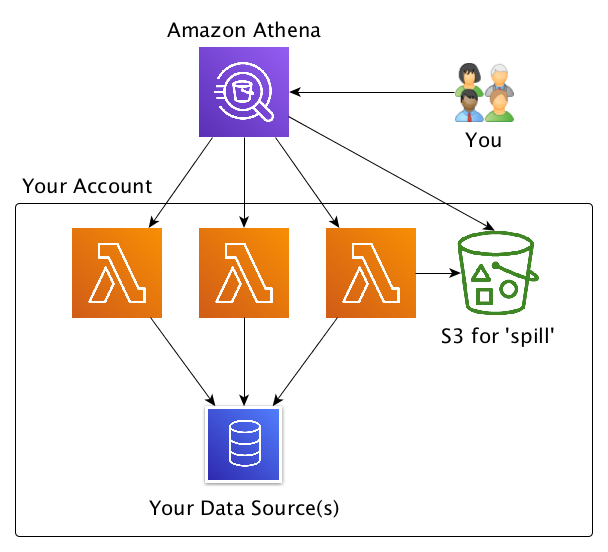
Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Simply point to your data in Amazon S3, define the schema, and start querying using standard SQL.
Lambda lets you run code without provisioning or managing servers. You can run code for virtually any type of application with zero administration and only pay for when the code is running.
Amazon Redshift is a petabyte-scale data warehouse designed from the ground up, natively for the cloud. Amazon Redshift is the most popular and fastest cloud data warehouse. It’s integrated with your data lake, offers performance up to three times faster than any other data warehouse, and costs up to 75% less than any other cloud data warehouse.
The following diagram depicts all the data source connectors available as of this writing in the AWS Serverless Application Repository.

The AWS Serverless Application Repository is a managed repository for serverless applications. It enables you to store and share reusable applications, and easily assemble and deploy serverless architectures in powerful new ways.
You can also create a custom connector for sources that aren’t in the AWS Serverless Application Repository.
Prerequisites
Before you get started, create a secret for the Amazon Redshift login ID and password using AWS Secrets Manager.
- On the Secrets Manager console, choose Secrets.
- Choose Store a new secret.
- Choose credentials for your Amazon Redshift cluster, and set your user name and password.
- Choose the cluster you want to use.
- For Secret name, enter a name for your secret. Use the prefix
AthenaJDBCFederationso it’s easy to find. - Leave the remaining fields at their defaults and choose Next.
- Complete your secret creation.
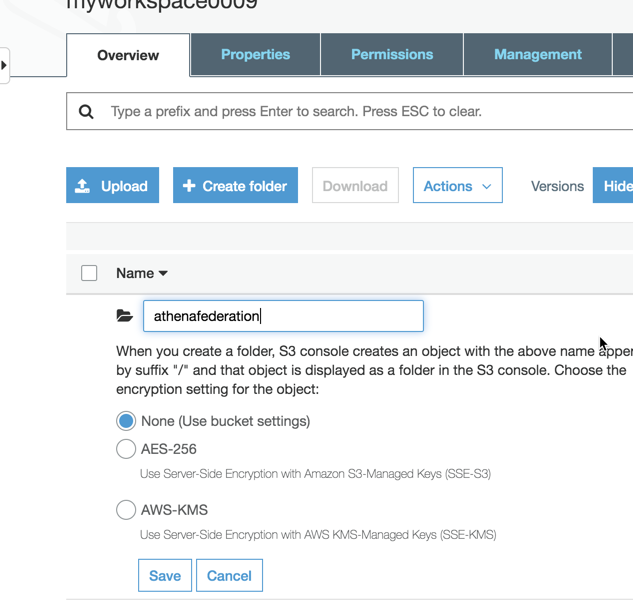
Setting up your S3 bucket
On the Amazon S3 console, create a new S3 bucket and subfolder for Lambda to use. For this post, use the name myworkspace0009/athenafederation.

Configuring Athena federation with Amazon Redshift
To configure Athena federation with Amazon Redshift, complete the following steps:
- On the AWS Serverless Application Repository, choose Available applications.
- In the search field, enter
athena federation.

- Choose
- In the Application settings section, provide the following details:
- Application name –
AthenaRedshiftConnector - SecretNamePrefix –
AthenaJdbcFederation - SpillBucket –
myworkspace0009/athenafederation - JDBCConnectorConfig –
Redshift://jdbc:Redshift://<YourAmazon Redshift1Hostname>:5439/<DBName>?user=sample2&password=sample2 - DisableSpillEncyption – False
- LambdaFunctionName –
rstpcds30 - SecurityGroupID – Security group ID where Amazon Redshift is deployed
- SpillPrefix – Leave default
- Subnetids – Use the subnets where Amazon Redshift is running with comma separation
- Select the I acknowledge check box.
- Choose Deploy.
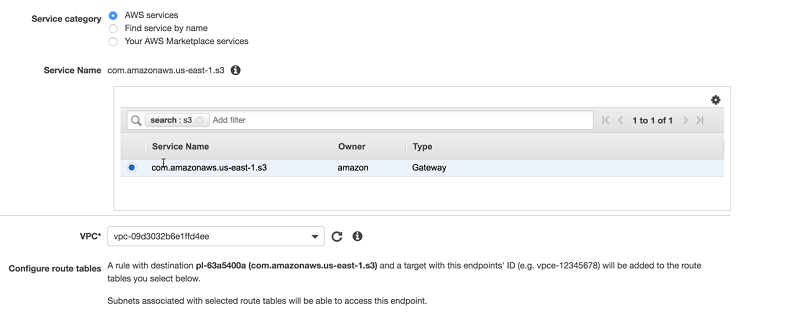
In the next steps, you configure an Amazon Virtual Private Cloud (Amazon VPC) endpoint for Amazon S3 to allow Lambda to write federated query results to Amazon S3.
- On the Amazon VPC console, choose Endpoints.
- Choose Create endpoint.
- Choose the VPC for your endpoint.
- Make any necessary security changes as per your security requirements.
- Choose Create endpoint.
Running federated queries with Athena
To start running federated queries, complete the following steps:
- On the Athena console, choose Workgroups.
- If you don’t see a workgroup called
AmazonAthenaPreviewFunctionality, create one.
When this feature becomes generally available, you won’t need to use this workgroup name.
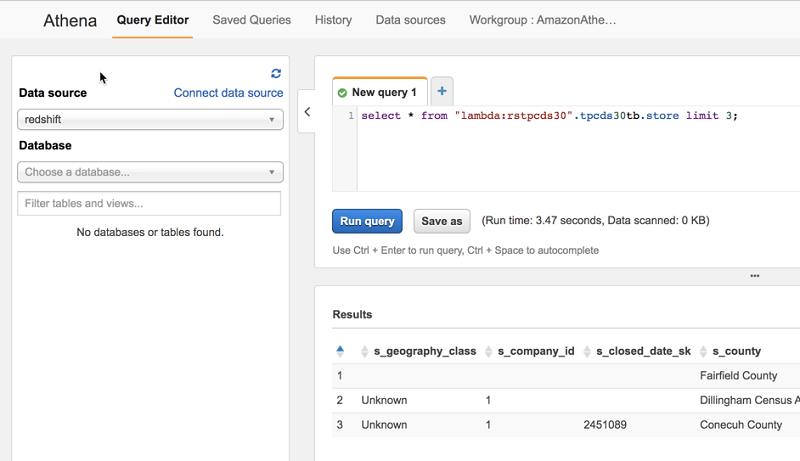
- Run your queries, using
lambda:rstpcds30to run against tables in Amazon Redshift.
Athena query performance comparison
Several customers have asked us for performance insights and prescriptive guidance on how queries in Athena compare against federated queries and how to use them. In this section, we use a TPC-DS 3 TB standard dataset and a select few queries that fall in the category of ad hoc and interactive. The comparison of their performance should give you an idea of what to expect when running federated queries against Amazon Redshift.
For the following tests, we used a 3 TB TPC-DS dataset in Amazon S3 data lake with Parquet compressed, partitioned and served by Athena, and the same 3 TB TPC-DS dataset on Amazon Redshift cluster running four RA3.4XL nodes.
The following table summarizes the dataset sizes:
| Dataset | Table Size (Records) |
store_sales |
8.6 billion |
customer |
30 million |
customer_address |
15 million |
customer_demographics |
1.92 million |
item |
360,000 |
date_dim |
73,000 |
store |
1,350 |
We ran the following four tests:
- T1 – Queries ran in Athena without federation. All table data is in Amazon S3.
- T2 – Queries ran in Athena with federation to Amazon Redshift. All table data is in Amazon S3, except the
store_salesfact table in Amazon Redshift. - T3 – Queries ran in Athena with federation to Amazon Redshift. All tables and data are in Redshift.
- T4 – Queries ran in Amazon Redshift without federation. All tables and data are in Redshift.
The following graph represents the performance of some of the ad hoc and interactive TPC-DS queries.
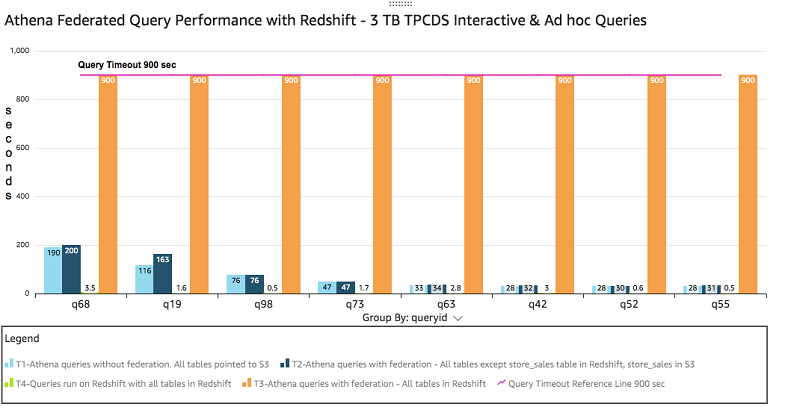
In the preceding graph, all T3 queries timed out at 900 seconds, depicted by the pink reference line, due to the Lambda 900-second timeout limit. This is due to overhead from store_sales fact data that needed to be transferred back to Athena.
The following graph removes T3 from the visualization, which gives better visibility when comparing the other tests.
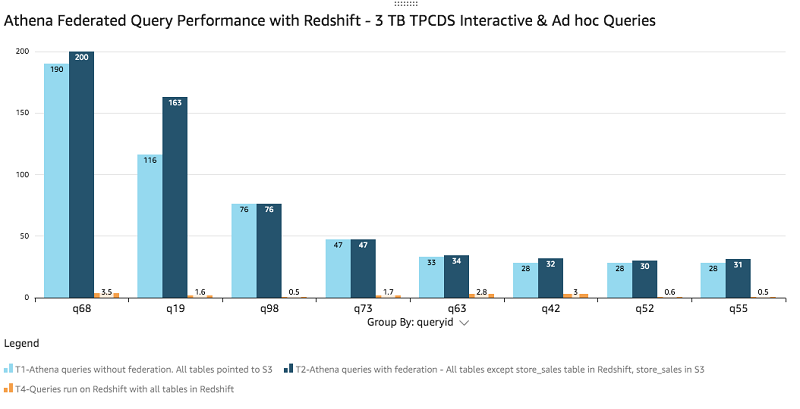
Notice the query performance between T1 and T2 that completed in almost the same time while T4 queries ran significantly faster.
Amazon Redshift beats the performance of Athena in providing extremely low latency and should be the tool of choice if you’re looking for very low SLAs for analytics queries that Athena can’t achieve.
The following graph shows the data scanned in Amazon S3 for T1 and T2, which outlines why there isn’t much difference in query performance when compared to federated queries.
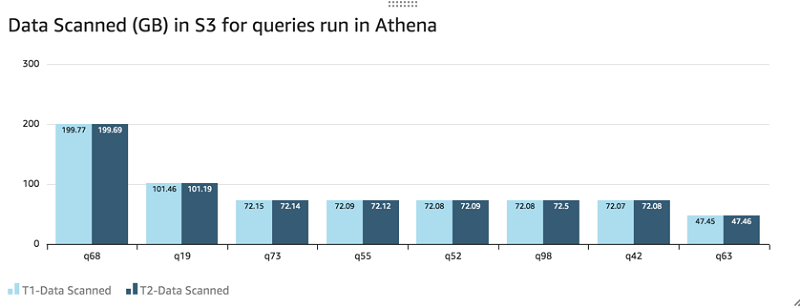
For the T2 federated queries, a small amount of dimension data is filtered in Amazon Redshift and brought back to Athena, instead of scanning the entire dimension tables. This is a typical nature for several ad hoc and interactive queries.
The performance of these TPC-DS queries between T1 and T2 is comparable because very little data is transferred back to Athena. You can see a similar behavior in several ad hoc and interactive query use cases because they use limited dimensions and scan a small subset of dimension data. Due to the 900-second timeout for the Lambda instances that connect to Amazon Redshift, it’s advised to minimize the amount of data the query brings back. Although Athena uses multiple Lambda instances in parallel to run your federated query, it’s also important to make sure the Amazon Redshift WLM queue has enough slots to process it, thereby not leading to queue wait time. For example, in some of the preceding queries, 20 Lambda executions were connecting to Amazon Redshift concurrently.
Key performance best practice considerations
When considering Athena federation with Amazon Redshift, you could take into account the following best practices:
- Athena federation works great for queries with predicate filtering because the predicates are pushed down to Amazon Redshift. Use filter and limited-range scans in your queries to avoid full table scans.
- If your SQL query requires returning a large volume of data from Amazon Redshift to Athena (which could lead to query timeouts or slow performance), unload the large tables in your query from Redshift to your Amazon S3 data lake.
- Star schema is a commonly used data model in Amazon Redshift. In the star schema model, unload your large fact tables into your data lake and leave the dimension tables in Amazon Redshift. If large dimension tables are contributing to slow performance or query timeouts, unload those tables to your data lake.
- When you run federated queries, Athena spins up multiple Lambda functions, which causes a spike in database connections. It’s important to monitor the Amazon Redshift WLM queue slots to ensure there is no queuing. Additionally, you can use concurrency scaling on your Amazon Redshift cluster to benefit from concurrent connections to queue up.
Conclusion
In this post, you learned how to configure and use Athena federation with Amazon Redshift using Lambda. Now you don’t need to wait for all the data in your Amazon Redshift data warehouse to be unloaded to Amazon S3 and maintained on a day-to-day basis to run your queries. You can use the best practice considerations outlined in the post to minimize the data transferred from Amazon Redshift for better performance. When queries are well written for federation, the performance penalties are negligible, as observed in the TPC-DS benchmark queries in this post. Happy query federating!
About the Author
 Harsha Tadiparthi is a Specialist Sr. Solutions Architect, AWS Analytics. He enjoys solving complex customer problems in Databases and Analytics and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.
Harsha Tadiparthi is a Specialist Sr. Solutions Architect, AWS Analytics. He enjoys solving complex customer problems in Databases and Analytics and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.