亚马逊AWS官方博客
Amazon S3 注释:将丰富的可查询上下文直接附加到您的对象
今天,我们宣布为 Amazon Simple Storage Service(Amazon S3)推出一项名为“注释”的全新元数据功能,该功能让您可以直接为对象挂载海量、丰富的业务上下文。您最多可以为单个对象存储 1000 个命名注释,单条注释的大小上限为 1MB,单对象注释的总大小最高为 1GB,支持 JSON、XML、YAML、纯文本等多种灵活格式。您可以随时修改、删除注释,无需重写对象,从而轻松实时更新对象上下文。
目前,组织正在构建人工智能代理和自主工作流,这些工作流需要在没有人为干预的情况下查找、理解和处理数据。为了支持这些代理工作流,您需要元数据能够与数据一起演变,扩展到千兆字节的对象,并且无需进行费用高昂的检索即可进行查询。
使用 S3 注释,您可以将上下文(例如 AI 生成的脚本、内容分级或技术规范)直接存储在对象旁边。在复制、复制和跨区域传输期间,您的上下文会自动随对象移动;当您删除对象时,S3 会将其移除。启用 S3 Metadata 后,注释会自动流入完全托管的注释表,您可以使用 Amazon Athena 和其他分析引擎进行查询。
常见使用案例
注解可以解决各行各业的复杂元数据挑战:
- 媒体和娱乐:将转录文本、内容审核结果、字幕文件和许可元数据作为视频资产上的单独注释进行跟踪,无需在多个媒体资产管理系统之间同步元数据。
- 金融服务:将人工智能生成的投资摘要和情绪分析附加到研究文件中,使自主研究机构能够通过自然语言查询发现相关数据集,而无需维护单独的元数据数据库。
- 生命科学:使用监管状态、患者群组详细信息和批准链对临床试验数据进行注释,从而加快合规性审计,同时保持 Amazon S3 Glacier 存储类别中存档数据的完整上下文可访问,不会产生检索费用。
注释如何应对元数据挑战
Amazon S3 已经支持多种描述对象的方法。系统定义的元数据可捕获大小和存储类别等属性。对象标签支持访问控制和生命周期管理等操作任务。用户定义的元数据允许您在上传时添加少量的自定义信息。
尽管这些功能可以很好地实现其预期用途,但当您需要在不构建和维护单独的元数据系统的情况下附加更丰富的上下文时,它们存在局限性。注释通过提供可扩展性和灵活性截然不同的元数据功能来满足这些需求,可为每个对象提供可变的、可查询的上下文,而非 10 个不可变标签或 2 KB 标头。
| 功能 | 大小上限 | 可变? | 适用场景 |
| 系统定义的元数据 | 固定大小 | 否 | 对象属性(大小、存储类别、创建时间) |
| 用户定义的元数据 | 2 KB | 否(上传时设置) | 小型自定义键值对 |
| 对象标签 | 10 个标签,每个键/值 128/256 个字符 | 是 | 访问控制、生命周期规则、成本分配 |
| 注释 | 1 GB(1000 × 1 MB) | 是 | 丰富的业务上下文(JSON、XML、YAML、纯文本) |
如今,描述 S3 对象的元数据通常存在于单独的数据库或 sidecar 文件中,需要复杂的同步工作流程,这些工作流程的费用可能会超过数据存储成本。当您启用 S3 Metadata 注释表时,该上下文将变为可通过 Amazon Athena 大规模查询的内容。人工智能代理可以通过 S3 表类数据存储服务 MCP 服务器以自然语言发现您的数据,该服务器为人工智能模型提供用于查询注释的标准化接口。您可以查询任何存储类别的对象的注释,而无需恢复对象或支付检索费用。
注释入门
要开始使用注解,请确保您的 AWS Identity and Access Management(IAM)策略或存储桶策略授予 s3:PutObjectAnnotation 和 s3:GetObjectAnnotation 操作的权限。然后,您可以使用 PutObjectAnnotation API 向任何现有或新的 S3 对象添加注释。
例如,媒体公司可以使用 AWS 命令行界面(AWS CLI)将技术规范和 AI 制作的摘要附加到视频资产:
# Create a JSON file with technical metadata
cat > mediainfo.json << 'EOF'
{"codec":"H.265","resolution":"3840x2160","audio_tracks":8,"frame_rate":29.97}
EOF
# Attach it as an annotation
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
--annotation-payload ./mediainfo.json
# Attach a plain-text AI-generated summary as a separate annotation
echo "A 90-minute nature documentary covering wildlife migration patterns across three continents, featuring aerial footage and underwater sequences.Languages: English, Spanish, Portuguese." > ai_summary.txt
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name ai_summary \
--annotation-payload ./ai_summary.txt
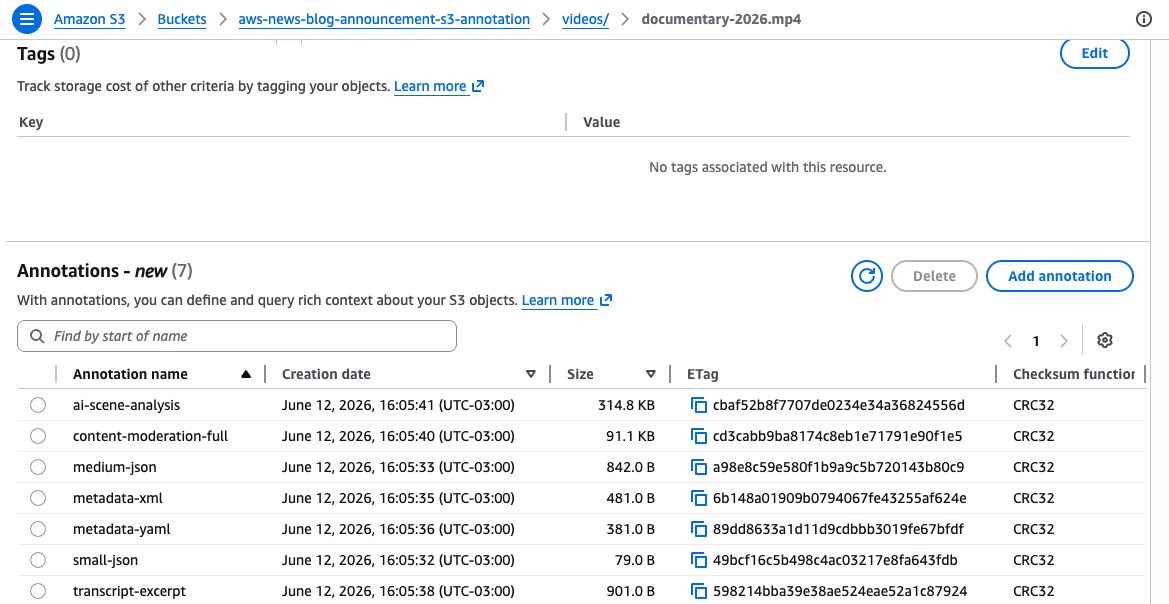
这些命令将两个单独的注释附加到同一个视频对象。mediainfo 注释以 JSON 格式存储结构化技术规范,ai_summary 注释则存储文本描述。每个注释都由一个唯一的名称标识,您可以单独阅读和修改每个注释。每个注释具有唯一的名称,您可以使用不同的注释来支持多个并发的丰富工作流程,例如,一个团队添加技术元数据,另一个团队添加内容分类,互不干扰。
使用 GetObjectAnnotation API 检索特定注释:
aws s3api get-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
./mediainfo-output.json
要查看附加到对象的所有注释,请使用 ListObjectAnnotations API:
aws s3api list-object-annotations \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4
当您不再需要某个特定注释时,使用 DeleteObjectAnnotation API 将其移除:
aws s3api delete-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo
您可以随时通过使用同一注释名称再次调用 PutObjectAnnotation 来更新现有注释。对于分段上传的大型对象,请在完成分段上传后使用 PutObjectAnnotation API 附加注释。
使用 S3 Metadata 表大规模查询注释
为单个存储对象附加注释固然实用,但该功能的核心价值在于可大规模查询所有注释。当您在存储桶上启用 S3 Metadata 注释表时,S3 会自动将您的注释索引到一个完全托管的 Apache Iceberg 表(称为注释表)中。您可以使用 Amazon Athena 或任何与 Iceberg 兼容的引擎来查询注释表。
要启用注释表,请使用 S3 控制台或 CreateBucketMetadataConfiguration API。以下示例创建了一个新的元数据配置,该配置启用了注释表,同时保留了日记表以进行变更跟踪并禁用了实时清单表:
{
"JournalTableConfiguration": {
"RecordExpiration": { "Expiration": "DISABLED" }
},
"InventoryTableConfiguration": { "ConfigurationState": "DISABLED" },
"AnnotationTableConfiguration": {
"ConfigurationState": "ENABLED",
"Role": "arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"
}
}
此配置指示 S3 在可查询表中自动捕获您的所有注释。应用该配置后,您附加到该存储桶中对象的任何注释都将在大约一小时内显示在表中。
如果存储桶已经有元数据配置,请使用 UpdateBucketMetadataAnnotationTableConfiguration API:
aws s3api update-bucket-metadata-annotation-table-configuration \
--bucket my-media-bucket \
--annotation-table-configuration '{"ConfigurationState":"ENABLED","Role":"arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"}'
启用后,您的注释将自动流入注释表。日记表几乎实时更新,而注释表在一小时内刷新。与需要预定义架构的传统元数据表不同,注释表会自动适应您编写的任何 JSON、XML 或 YAML 结构。每个注释占据表中的一行,其内容存储在 text_value 列中,让您无需进行架构迁移即可查询所有注释。
如果您在已有注释对象的存储桶上启用注释表,S3 会自动将现有注释回填到表中。回填过程在后台运行,可能需要几个小时到几天,具体取决于对象的数量。
例如,要使用 Amazon Athena 查找整个存储桶中包含超过 8 个音轨的所有视频资产:
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE name = 'mediainfo'
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8
此查询会扫描注解表中所有名为 mediainfo 的注释,从 JSON 内容中提取 audio_tracks 字段,并返回计数超过 8 的对象。
或者,通过日记表查找过去 24 小时内收到新注释的所有对象:
SELECT bucket, key, version_id, record_timestamp, annotation.name
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."journal"
WHERE record_timestamp >= (current_date - interval '1' day)
AND annotation.name IS NOT NULL
AND record_type IN ('CREATE_ANNOTATION', 'DELETE_ANNOTATION')
此查询使用日记表来近乎实时地跟踪注释更改,这非常适合构建响应新注释或已删除注释的事件驱动型工作流。
您还可以在 Amazon SageMaker 融通式合作开发工作室或任何带有 S3 表类数据存储服务 MCP 服务器的 IDE 中使用代理,以自然语言通过注释搜索对象。例如,询问“找出 2023 年所有带西班牙语字幕的 PG 级电影”将在几秒中内返回结果,而需要花费几个小时查询多个断开连接的系统。
立即开始
您可以立即开始在所有 AWS 区域(包括 AWS 中国区域)使用 Amazon S3 注释。注释表适用于 S3 Metadata 可用的所有 AWS 区域。
无论是构建需要自主发现数据的人工智能代理,使用复杂的元数据管理千兆字节的媒体资产,还是跟踪存档数据集的合规性上下文,注释都能让您灵活地将丰富的元数据直接附加到对象,而无需管理单独的系统。
注释存储始终按 S3 Standard 费率计费,即使父对象在 S3 Glacier 或其他存储类别中也是如此。有关完整的定价详情,请访问 Amazon S3 定价页面。
要了解更多信息并开始使用,请访问 Amazon S3 Metadata 概述页面和 Amazon S3 文档。请将反馈发送至 AWS re:Post for S3 或通过您常用的 AWS Support 联系方式发送反馈。
Daniel Abib