Artificial Intelligence
Multi-GPU distributed deep learning training at scale with Ubuntu18 DLAMI, EFA on P3dn instances, and Amazon FSx for Lustre
AWS Deep Learning AMI (Ubuntu 18.04) is optimized for deep learning on EC2 Accelerated Computing Instance types, allowing you to scale out to multiple nodes for distributed workloads more efficiently and easily. It has a prebuilt Elastic Fabric Adapter (EFA), Nvidia GPU stack, and many deep learning frameworks (TensorFlow, MXNet, PyTorch, Chainer, Keras) for distributed deep learning training. You don’t need to spend time installing deep learning software and drivers or building machine learning (ML) infrastructure. Instead, you can focus on training jobs at scale in a shorter amount of time and iterating on your ML models faster.
This post demonstrates the ease of running large-scale high-performance, network-sensitive, low-latency, highly coupled, ML distributed training on AWS High Performance Computing (HPC) architecture that includes Ubuntu 18 DLAMI, Elastic Fabric Adapter (EFA) on P3dn instances and Amazon FSx for Lustre. This post walks you through how to run a Bidirectional Encoder Representations from Transformers (BERT) model with PyTorch framework on a multi-node GPU cluster. In addition, the post provides guidance for automating deep learning cluster deployment and management through AWS ParallelCluster.
Introduction to BERT
BERT is a method of pretraining language representations that obtains state-of-the-art results on a wide array of natural language processing (NLP) tasks. You can train a general-purpose language understanding model on a large text corpus (like Wikipedia), and use that model for downstream NLP tasks (like answering questions). BERT is the first unsupervised deeply bidirectional system for pre-training NLP.
Unsupervised means that BERT was trained using only a plaintext corpus, which is important because an enormous amount of plaintext data is publicly available on the web in many languages. The following table summarizes the configuration this post uses for the BERT procedure, which overlaps the backward pass and communication with a tuned bucket size of 200 MB.
| Model | Hidden Layers | Hidden Unit Size | Attention Heads | Feedforward Filter Size | Max Sequence Length | Parameters |
| BERTLARGE | 24 encoder | 1024 | 16 | 4 x 1024 | 512 | 350 M |
Overview of HPC on AWS for BERT training
The BERT procedure is conducted on AWS HPC Architecture services that includes Ubuntu18 DLAMI, EFA on P3dn instances and FSx for Lustre for Ubuntu18.
AWS Deep Learning AMI (Ubuntu 18.04)
This DLAMI uses the Anaconda Platform with both Python2 and Python3 to easily switch between frameworks. The AWS Deep Learning AMIs are prebuilt with Nvidia CUDA 9, 9.2, 10, and 10.1, and several deep learning frameworks, which includes Apache MXNet, PyTorch, and TensorFlow. This post uses the following DLAMI features:
- PyTorch framework – PyTorch is a Python package that provides two high-level features: tensor computation (like NumPy) with strong GPU acceleration, and deep neural networks built on a tape-based autograd system. The PyTorch branch and tag used is v1.2. To activate the
pytorchenvironment, runsource activate pytorch_p36. - NVIDIA stack – NVIDIA driver 418.87.01, CUDA 10.1 / cuDNN 7.6.2 / NCCL 2.4.8.
The master node is configured on c5n.18xlarge, and workers or training nodes are configured on P3dn instances.
Elastic Fabric Adapter
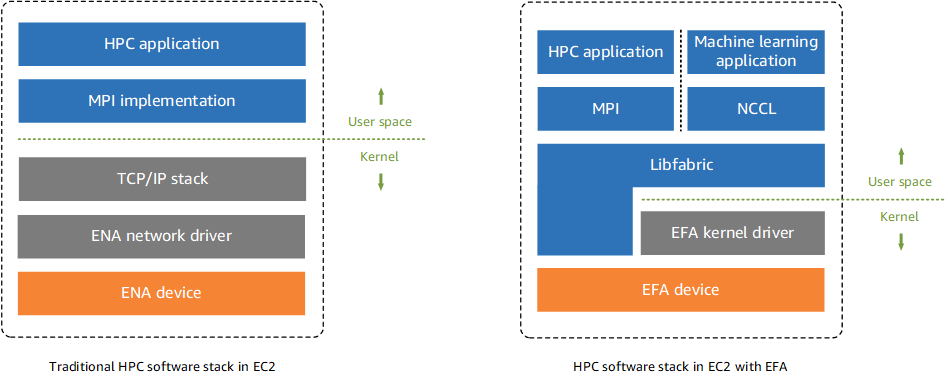
EFA is a network device that you can attach to an Amazon EC2 instance to accelerate HPC for ML applications. EFA provides lower and more consistent latency and higher throughput than the TCP transport, traditionally used in cloud-based HPC systems. It enhances the performance of inter-node communication that is critical for scaling HPC for ML applications. EFA integrates with Libfabric 1.8.1, supports Open MPI 4.0.2 and Intel MPI 2019 Update 6 for HPC applications, and supports Nvidia Collective Communications Library (NCCL) for ML applications. The OS-bypass capability of EFA is an access model that allows HPC and ML applications to communicate directly with the network interface hardware to provide a low-latency and reliable transport functionality. The following diagram illustrates the EFA device on P3dn instances for this use case.
Amazon FSx for Lustre
Lustre is an open-source parallel file system designed for high-performance workloads. These workloads include HPC, ML, analytics, and media processing. A parallel file system provides high throughput for processing large amounts of data and performs operations with consistently low latency. It does so by storing data across multiple networked servers that thousands of compute instances can interact with concurrently. The Lustre file system provides a POSIX-compliant file system interface. Amazon FSx for Lustre provides a fully managed, high-performance Lustre file system that allows file-based applications to access data with hundreds of gigabytes per second of data, millions of IOPS, and sub-millisecond latencies. Amazon FSx works natively with Amazon Simple Storage Service (Amazon S3); you can access Amazon S3 objects as files on Amazon FSx and can write results back to Amazon S3. This post uses Lustre version 2.10.8.
P3dn instances
Amazon EC2 P3dn.24xlarge GPU instances are optimized for distributed ML and HPC applications. A P3dn.24xlarge instance has 100 Gbps network bandwidth, and the new EFA network interface allows for highly scalable internode communication. EFA is available for both Amazon Linux and Ubuntu operating system and integrated with LibFabric. AWS worked with NVIDIA for EFA to support NCCL, which optimizes multi-GPU and multi-node communication primitives and helps achieve high throughput over NVLink interconnects. With these enhanced features, you can scale ML training to use thousands of GPUs, which provides faster training results. The EFA operating system bypasses networking mechanisms and the underlying Scalable Reliable Protocol that is built in to the Nitro controllers. The Nitro controllers enable a low-latency, low-jitter channel for inter-instance communication. The following table shows the features of the P3dn.24xlarge instances used in this post.
| Feature | Value |
| GPUs | 8x 32 GB NVIDIA Tesla V100 |
| GPU Interconnect | NVLink – 300 GB/s |
| GPU Memory | 256 GB |
| Processor | Intel Skylake 8175 (w/ AVX 512) |
| vCPUs | 96 |
| RAM | 768 GB |
| Network Bandwidth | 100 Gbps + EFA |
AWS ParallelCluster
You can automate HPC cluster deployment and management with AWS ParallelCluster, an AWS-supported, open-source cluster management tool. You can provision resources in a safe, repeatable manner, allowing you to build and rebuild HPC infrastructure without the need for manual actions or custom scripts. AWS ParallelCluster uses a simple text file to model and dynamically provision all the resources needed for your HPC applications in an automated and secure manner. It supports AWS Batch, SGE, Torque, and Slurm job schedulers for easy job submissions.
Setting up your distributed BERT training environment
To set up your distributed BERT training environment, complete the following steps:
- Build a VPC with one public subnet, one private subnet, and one cluster placement group. EFA also requires a security group that allows all inbound and outbound traffic to and from the security group itself.
- On the Inbound and Outbound tabs of the security group, complete the following:
- Choose Edit.
- For Type, choose All traffic.
- For Source, choose Custom.
- Enter the security group ID that you copied into the field.
- Choose Save.
- Launch an EFA-enabled P3dn.24xlarge instance with Ubuntu18 DLAMI. You can launch the P3dn instance on the AWS Management Console, AWS Command Line Interface (AWS CLI), or SDK toolkit. All P3dn instances of the ML cluster should be in the same Availability Zone, subnet, and placement group to run the BERT training.
- To check the currently installed EFA installer version, enter the following code:
- To verify your instance has access to the EFA device, enter the following code:
The EFA device is sometimes missing because the ib_uverbs driver gets unloaded on instances. To verify this and retry looking for the EFA device, see the following code:
- Set up a passwordless SSH. To enable your applications to run across all of the instances in your cluster, you must enable passwordless SSH access from the Master node to the member nodes. The Master node is the instance from which you run your applications. After you set up a passwordless SSH, disable the password authentication for SSH. Open the SSH configuration file
/etc/ssh/sshd_config, search for the following directives and modify as it follows:Once you are done save the file and restart the SSH service. On Ubuntu or Debian servers, run the following command:
- Set up FSx for Lustre; Ubuntu 18.04 needs a specific 2.10 Lustre branch with patches to support.
- To install the FSx for Lustre client for Ubuntu18, enter the following code:
- To mount FSx for Lustre Filesystem, enter the following code:
- Upload BERT training data to Lustre Filesystem. For instructions on generating BERT training data on EC2 instances, see Getting the data on GitHub.
- Configure the training output log file directory on Lustre Filesystem.
- Configure the checkpoint directory on Lustre Filesystem.
- Install FairSEQ.Fairseq(-py) is a sequence modeling toolkit that allows you to train custom models for translation, summarization, language modeling, and other text-generation tasks. The prerequisites of the Fairsq installation are configured in Ubuntu18 DLAMI. See the following code:
To install fairseq from the source and develop locally, enter the following code:
- Create an image for this P3dn instance from the console and record the AMI ID.
- Launch the master node (c5n instance) for BERT training.
- Launch an 8 node P3dn.24xlarge instance cluster using the BERT training AMI. All P3dn instances should be in the same Availability Zone, subnet, and placement cluster group.
- Test that all P3dn instances have EFA enabled.
- Install and configure AWS ParallelCluster.This post uses the AWS ParallelCluster version 2.6.0. For more information, see the GitHub repo. The key steps to launching AWS ParrallelCluster are as follows:
- Install AWS ParallelCluster with the following code:
- Configure AWS ParallelCluster with the following code:
Download the configuration file template from GitHub. You can choose Slurm Scheduler for this use case.
- Launch the HPC cluster with the following code:
If you are new to AWS ParallelCluster, follow the steps 1–10 to ensure that your cluster has the correct configuration to launch a multi-node deep learning training job. After you successfully complete your multi-node training, you can start using AWS ParallelCluster for automation and faster deployment of your HPC cluster. While you are using AWS ParallelCluster, you don’t need to manually perform these steps, those configurations are part of the AWS ParallelCluster configuration file. It’s recommended that you create a BERT training AMI to standardize your software stack for consistent performance.
Running your BERT training
You can use BERT with the PyTorch library to quickly and efficiently train a model to get near-state-of-the-art performance in sentence translation on AWS HPC infrastructure. Fairseq provides several command-line tools for training and evaluating models. This post uses the fairseq-train tool to train a new model on one or multiple GPUs and roberta_large architecture. RoBERTa iterates on BERT’s pretraining procedure and performs the following actions:
- Trains the model longer and with bigger batches over more data
- Removes the next sentence prediction objective
- Trains on longer sequences
- Changes the masking pattern applied to the training data dynamically
After you complete the BERT training setup, launch the BERT training script from the master node, which runs the training job in all GPU instances. During the training process, you can run the nvidia-smi command to check the performance of each GPU in the BERT cluster. This post uses the following training scripts to explain the practical application of transfer learning in NLP to create high-performance models with minimal effort on a range of NLP tasks:
The BERT training result is captured in the BERT training log in the FSx for Lustre file system. With an increase in the number of GPUs, there is linear improvement in training performance. With the same dataset, the words per second (wps) count increased linearly with the increase in number of GPUs in the training.
Cleaning up
To prevent any additional charges, shut down the master node, worker node, and FSX cluster after the training is completed. Delete all the model artifacts saved in Amazon S3.
Conclusion
Setting up ML infrastructure for deep learning training can be a considerable effort and you often have to depend on the infrastructure team to set up the environment, thereby losing productive time. Also, deep learning technical libraries and packages are changing at a fast pace and you will need to test the interoperability of all of these packages. With Ubuntu18 DLAMI, you don’t need to worry about setting up infrastructure and installing software. This DLAMI has pre-built the necessary deep learning libraries and packages for all the major ML frameworks, so you can focus on model training, tuning, and inference.
About the Author
 Purna Sanyal is a Senior Solution Architect at AWS Strategic Accounts. He provides technical thought leadership, architecture guidance and conduct POC for customers to meet their both Strategic needs and larger adoption of AWS services. His core areas of focus are Cloud Migration, HPC, Analytics and Machine learning.
Purna Sanyal is a Senior Solution Architect at AWS Strategic Accounts. He provides technical thought leadership, architecture guidance and conduct POC for customers to meet their both Strategic needs and larger adoption of AWS services. His core areas of focus are Cloud Migration, HPC, Analytics and Machine learning.