Blog de Amazon Web Services (AWS)
Migrar datos de estilo relacional desde NoSQL a Amazon Aurora DSQL
Este artículo fue escrito por Ramesh Raghupathy y Fernando Ibanez, Arquitectos de Soluciones Sr. en AWS. La traducción estuvo a cargo de Marcelo Ahuerma, Arquitecto de Soluciones Sr. en AWS.
Las organizaciones que utilizan bases de datos NoSQL se han beneficiado durante mucho tiempo de su flexibilidad y escalabilidad. Muchas de estas organizaciones almacenan datos relacionales en estructuras desnormalizadas, utilizando consultas de subcadena e índices para mantener y consultar relaciones. Para las empresas que gestionan dichos datos, Amazon Aurora DSQL presenta una oportunidad convincente para realizar la transición a una base de datos relacional diseñada específicamente que es una base de datos SQL distribuida, serverless y rápida.
Aurora DSQL combina la familiaridad de SQL—una piedra angular de la tecnología de bases de datos desde la década de 1970—con capacidades modernas como la compatibilidad con ACID y operaciones activo/activo en múltiples regiones. Su organización puede beneficiarse de la experiencia en SQL de sus equipos y la madurez de los sistemas relacionales mientras mantiene la flexibilidad y escalabilidad de las bases de datos NoSQL. Debido a que es serverless y está optimizada para cargas de trabajo transaccionales, es ideal para arquitecturas de microservicios, serverless y orientadas en eventos.
En esta publicación, demostramos cómo migrar eficientemente datos de estilo relacional desde NoSQL a Aurora DSQL, utilizando Kiro CLI como nuestra herramienta de IA generativa para optimizar el diseño del esquema y agilizar el proceso de migración.
Descripción general de la solución
Demostramos la migración de datos desde una base de datos NoSQL MongoDB, donde las entidades relacionadas se almacenan en una única colección, a un esquema relacional normalizado en Aurora DSQL.
Utilizamos el conjunto de datos movie_collection de una colección MongoDB, donde múltiples entidades relacionadas se almacenan en un formato desnormalizado, a tablas relacionales normalizadas en Aurora DSQL. El proceso de extracción, transformación y carga (ETL) se realizará utilizando Apache Spark ejecutándose como un paso en un clúster de Amazon EMR.
El siguiente diagrama muestra la arquitectura utilizada para la demostración.
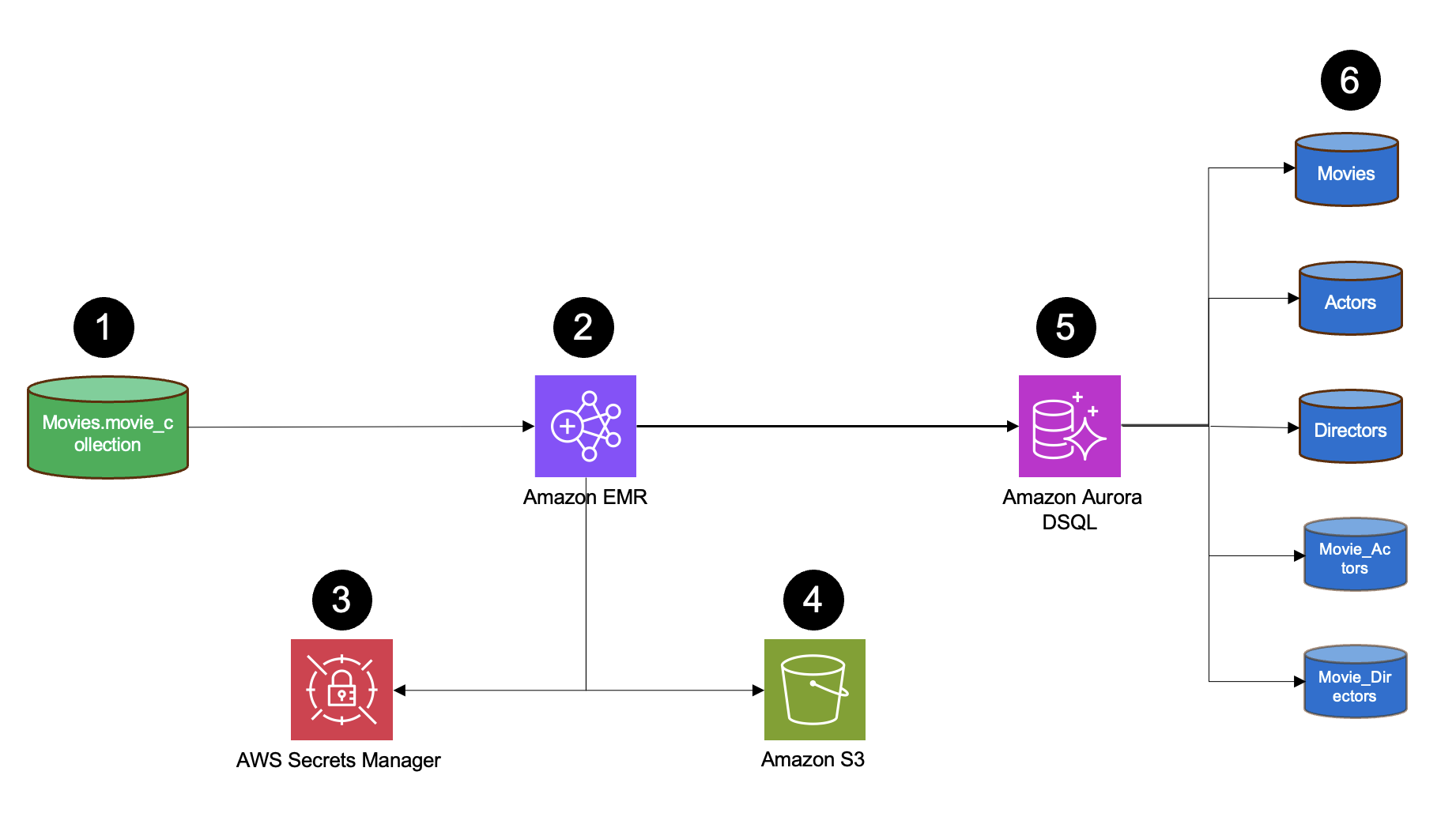
La solución consta de los siguientes componentes:
- La base de datos MongoDB de origen contiene una colección de películas con documentos asociados a películas. Estos documentos representan diferentes entidades, como película, actor, director, actor de película y director de película.
- Amazon EMR con Spark realiza el procesamiento ETL leyendo datos de MongoDB utilizando el MongoDB Spark Connector con credenciales de AWS Secrets Manager, transformando estructuras de documentos a un modelo relacional utilizando Spark DataFrames, y escribiendo los datos transformados en Aurora DSQL utilizando el conector Spark PostgreSQL JDBC.
- AWS Secrets Manager almacena las credenciales de MongoDB.
- Amazon Simple Storage Service (Amazon S3) sirve como capa de almacenamiento para los datos y el controlador JDBC.
- La base de datos relacional Aurora DSQL de destino almacena datos transformados en tablas estructuradas, admite capacidades de consulta SQL y mantiene la integridad referencial entre tablas.
- La estructura de datos de destino consta de cinco tablas principales (Movies, Actors, Directors, Movie_Actors, Movie_Directors), cada una almacenando datos de entidades específicas y mapeos de relaciones en un formato relacional normalizado.
Para esta publicación, utilizamos los siguientes pasos para realizar una migración fluida:
- Identificar entidades y relaciones en sus documentos NoSQL.
- Construir tablas normalizadas con claves y restricciones apropiadas.
- Escribir un script Spark para extraer, transformar y cargar datos.
- Ejecutar el proceso ETL para transferir datos.
- Verificar la integridad y completitud de los datos.
Requisitos previos
Siga las instrucciones de esta sección para implementar los recursos de requisitos previos en su cuenta de AWS.
Implementar la infraestructura
Complete los siguientes pasos para implementar la infraestructura utilizando una plantilla de AWS CloudFormation:
- Abra AWS CloudShell.
- Ejecute el siguiente comando para clonar el repositorio de GitHub:
- Ingrese al directorio
mongodb-dsql-migration-stacky haga ejecutabledeploy.sh: - Ejecute el script de implementación para implementar la infraestructura:
La pila de CloudFormation tarda aproximadamente 10-15 minutos en completarse. Crea los siguientes recursos:
- Recursos de Amazon Virtual Private Cloud (Amazon VPC), incluida VPC con subred pública y puerta de enlace de Internet
- Instancia de Amazon Elastic Compute Cloud (Amazon EC2) con base de datos MongoDB preconfigurada
- Clúster EMR para ejecutar trabajos ETL de Spark
- Clúster Aurora DSQL de una sola región
- Secreto de Secrets Manager para credenciales de MongoDB
- Roles de AWS Identity and Access Management (IAM) y grupos de seguridad con permisos apropiados
- Datos de muestra cargados en MongoDB
El costo será de aproximadamente $1 por hora para la infraestructura implementada.
- Ejecute el siguiente comando para encontrar el archivo
dataset.jsonque contiene los datos exportados de MongoDB: - Descargue
dataset.jsona su carpeta local.
Instalar Kiro CLI
Utilizamos Kiro CLI en esta publicación para demostrar el proceso de generación de código. Consulte los pasos de instalación de Kiro CLI para instalarlo en su máquina local.
Identificar entidades y relaciones
Al migrar desde una base de datos NoSQL a una base de datos SQL, el primer paso es la identificación de entidades. Esto implica analizar el conjunto de datos existente para crear las declaraciones DDL correspondientes que definirán las tablas en Aurora DSQL. El proceso requiere extraer el esquema y analizar estructuras de documentos para identificar objetos embebidos, matrices y candidatos de entidades potenciales. Un aspecto importante es normalizar adecuadamente las relaciones de muchos a muchos que se encuentran comúnmente en colecciones NoSQL mediante la creación de tablas de unión apropiadas. Aunque esto puede llevar mucho tiempo cuando se hace manualmente, las herramientas modernas de IA generativa como Kiro CLI pueden agilizar significativamente el análisis y el proceso de creación de DDL.
Para generar declaraciones SQL DDL de manera eficiente, es importante proporcionar a Kiro CLI una muestra de datos representativa. Extraiga un subconjunto completo de su base de datos, que abarque todos los tipos de entidades y relaciones, ya sea a través de un volcado completo o consultas dirigidas. Puede encontrar el prompt de muestra que utilizamos en el código en el repositorio de GitHub, en la carpeta prompts_and_outputs. El nombre del archivo es mongodb_dsql_migration_prompt.md.
Crear tablas relacionales
Al desarrollar con DSQL, es importante tener en cuenta que no admite algunas características de PostgreSQL, tales como:
- Sin claves foráneas – Aplique la integridad referencial en el código de su aplicación
- Sin triggers – Implemente la lógica de negocio y la validación de datos en su capa de aplicación
- Sin procedimientos almacenados o funciones – Mueva toda la lógica procedimental a su aplicación
- Sin secuencias – Use UUID u otros identificadores generados en lugar de IDs autoincrementales
- Restricciones en claves primarias – Limitadas a ocho columnas con un tamaño combinado de 1 KiB
- Tamaños de lote – Transacciones limitadas a 3,000 modificaciones de filas y 10 MiB de tamaño total
Proceso de análisis de datos
Analizaremos el archivo dataset.json utilizando Kiro CLI. Puede revisar el prompt de muestra utilizado para extraer las entidades y las restricciones bajo las cuales estamos trabajando.
Primero le pedimos a Kiro CLI que revise el archivo e identifique todas las entidades. Luego le pedimos a Kiro CLI que cree el SQL DDL para crear todas las tablas.
Este prompt proporciona instrucciones completas para analizar un conjunto de datos de MongoDB y generar DDL compatible con Amazon DSQL que preserve las relaciones de lista de adyacencia a través de patrones de clave primaria compuesta y clave secundaria mientras respeta las restricciones específicas de DSQL (sin claves foráneas, triggers o secuencias, claves primarias UUID, índices asíncronos, etc.).
El prompt está estructurado en cuatro secciones principales:
- Requisitos de migración – Establece restricciones técnicas
- Lo que necesito que hagas – Desglosa el proceso de análisis y generación de 4 pasos
- Mi fuente de datos MongoDB – Hace referencia al archivo de entrada
- Formato de salida esperado – Especifica los entregables, incluida la descripción general de la migración, scripts DDL, mapeo de relaciones y estrategia de migración
Para analizar dataset.json utilizando Kiro CLI, complete los siguientes pasos:
- Abra su aplicación de terminal.
- Navegue al directorio que contiene dataset.json.
- Inicie una sesión de Kiro CLI:
- Copie el prompt del repositorio de GitHub proporcionado e ingréselo en el prompt de terminal.
Kiro CLI generará un archivo ddl.sql en su directorio de trabajo.
El siguiente bloque de código muestra parte de la salida generada por Kiro CLI con el DDL que puede ejecutar en Aurora DSQL para crear las tablas:
Implementar tablas en Aurora DSQL
Puede usar el archivo ddl.sql generado para crear tablas en Aurora DSQL. Complete los siguientes pasos:
- En la consola de Aurora DSQL, elija Clusters en el panel de navegación.
- Seleccione su clúster de Aurora DSQL.
- En Connect with Query Editor, elija Connect with AWS CloudShell.
- Elija Connect as admin, luego elija Launch CloudShell.
- Después de conectarse a CloudShell, elija Actions para cargar el archivo ddl.sql.
- Ejecute las declaraciones DDL ejecutando el siguiente comando en el prompt de postgres:
Crear script ETL
Para nuestra implementación de migración, creamos un script ETL para procesar y migrar eficientemente los datos a Aurora DSQL. Para este paso, recomendamos usar AWS Glue o Amazon EMR. AWS Glue es un servicio ETL completamente administrado que simplifica las tareas de preparación y carga de datos. Amazon EMR administra clústeres Hadoop para el procesamiento de big data y cargas de trabajo de análisis.
Para agilizar el proceso de desarrollo, nuevamente utilizamos Kiro CLI como nuestro asistente de codificación impulsado por IA. Ayuda a acelerar la generación de código tanto para los componentes de extracción como de carga de su pipeline ETL. Al proporcionar a Kiro CLI declaraciones DDL del archivo ddl.sql, puede obtener fragmentos de código generados por IA adaptados para extraer cada entidad y sus relaciones asociadas.
Puede revisar un prompt de muestra llamado pyspark_migration_prompt.md que se encuentra en la carpeta prompts_and_outputs. Cuando escriba su prompt para su migración, puede modificar el prompt de muestra para que coincida con su caso de uso y datos. Kiro CLI seguirá las instrucciones en este archivo y creará el script PySpark que ejecutará. El archivo generado se llama mongodb_to_dsql_migration.py y se puede encontrar un archivo de muestra generado en el repositorio de código en la carpeta prompts_and_outputs.
Aunque Kiro CLI puede automatizar gran parte de las tareas de codificación repetitivas, la supervisión humana sigue siendo crucial, especialmente cuando se trata de estructuras de datos complejas o sistemas de misión crítica. Como mejor práctica, revise y valide minuciosamente el código generado para garantizar la precisión en la captura de todas las relaciones de datos y el cumplimiento de su lógica de negocio específica y los requisitos de transformación de datos.
Ejecutar script ETL
Complete los siguientes pasos para ejecutar el script ETL:
- Localice el nombre de su bucket de S3 donde está almacenando el script EMR. El nombre del bucket sigue el formato
emr-scripts-dsql-XXXXXXXXXXXX. - Cargue el script ETL (
mongodb_to_dsql_migration.py) a su bucket de S3. - Agregue un trabajo Spark como un paso a su clúster EMR:
- Elija Add Step.
- Para Type, seleccione Custom JAR.
- Para Name, ingrese un nombre descriptivo (por ejemplo, MongoDB Migration).
- Para JAR location, ingrese
command-runner.jar. - Para Arguments, ingrese el siguiente código, actualizando el nombre de la carpeta S3 de su script EMR:
- Para Action if step fails, seleccione Continue.
- Elija Add.
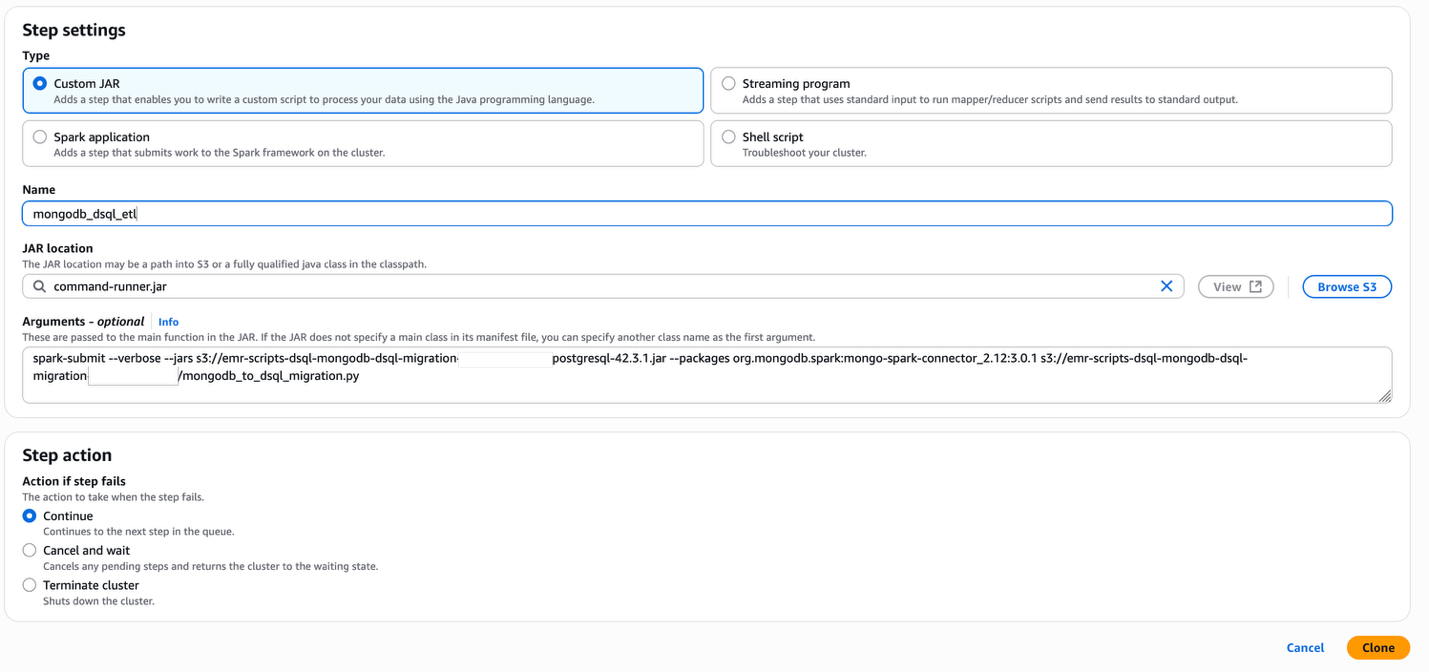
- Para verificar la finalización exitosa, revise los registros stdout. Si el paso falla, revise los registros stderr para mensajes de error.
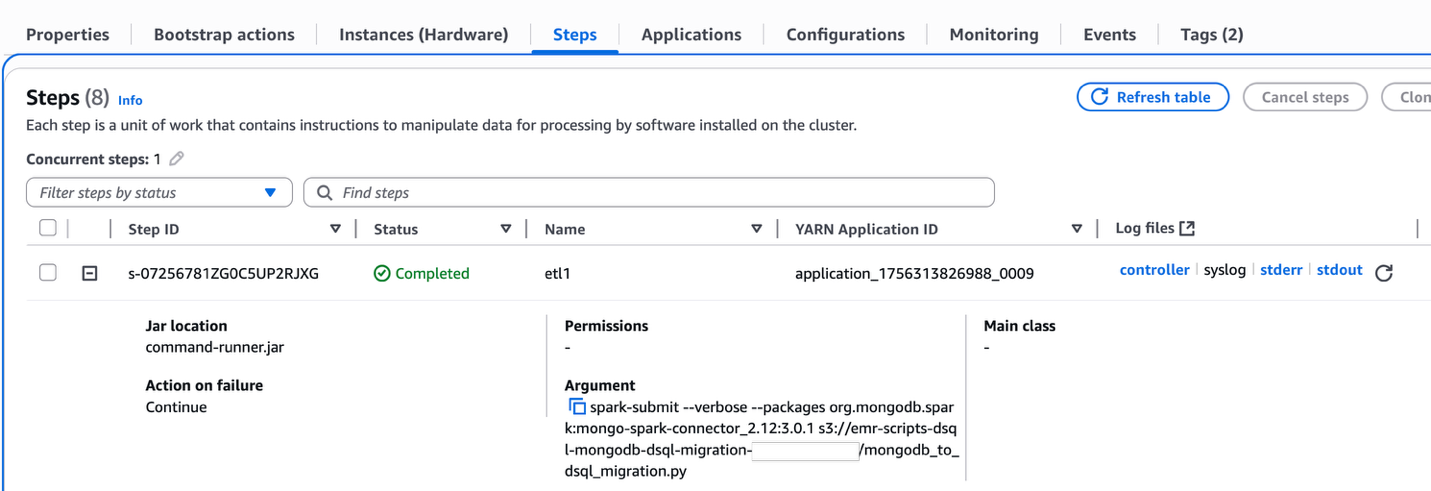
Esto extrae todas las entidades de MongoDB y las inserta en Aurora DSQL.
Validar la migración
La fase final del proceso de migración implica validar la integridad y precisión de los datos transferidos. Considere las siguientes verificaciones:
- Validación básica del recuento de entidades – Comience con consultas de recuento simples para cada entidad, comparando resultados entre la base de datos de origen y Aurora DSQL. Esto proporciona una verificación rápida de alto nivel de la completitud de los datos.
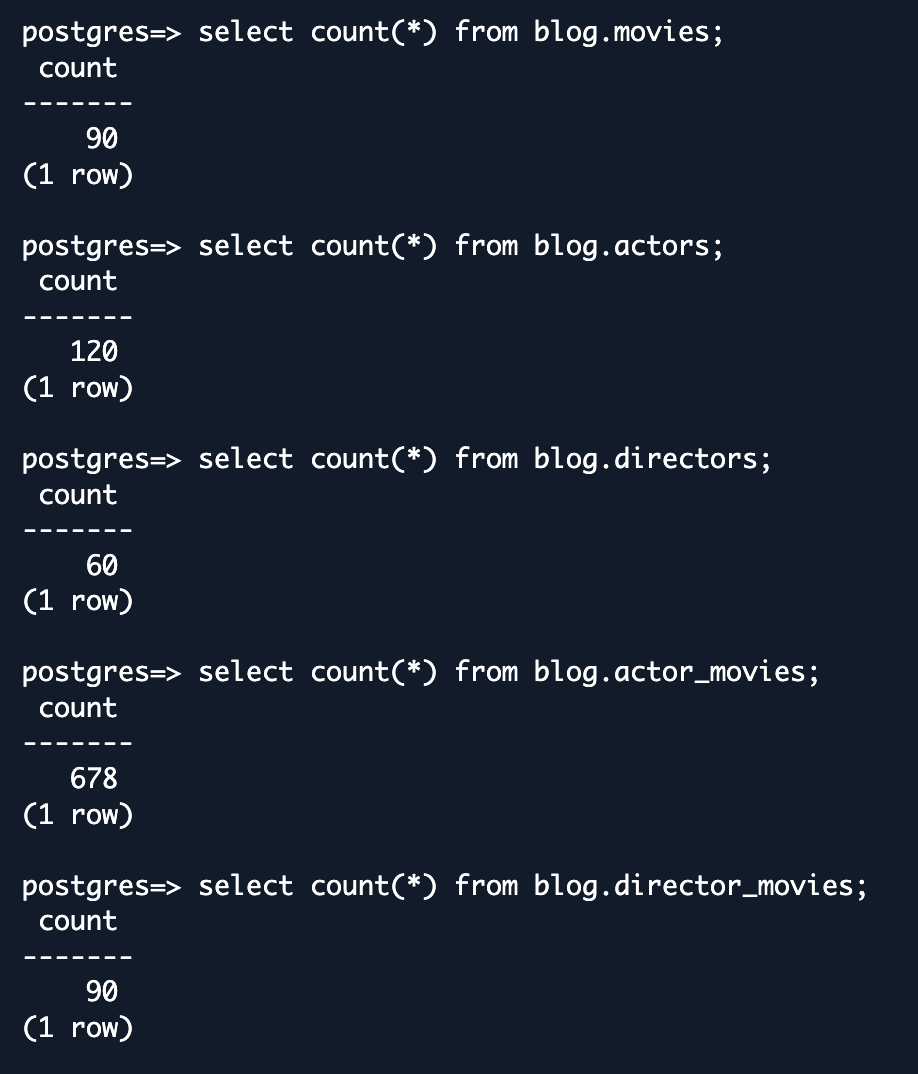
- Validación de filas – Revise algunas filas de muestra entre MongoDB y DSQL. Deberá identificar filas de muestra con la misma clave primaria para las cuales pueda comparar todos los valores de columna entre MongoDB y Aurora DSQL.
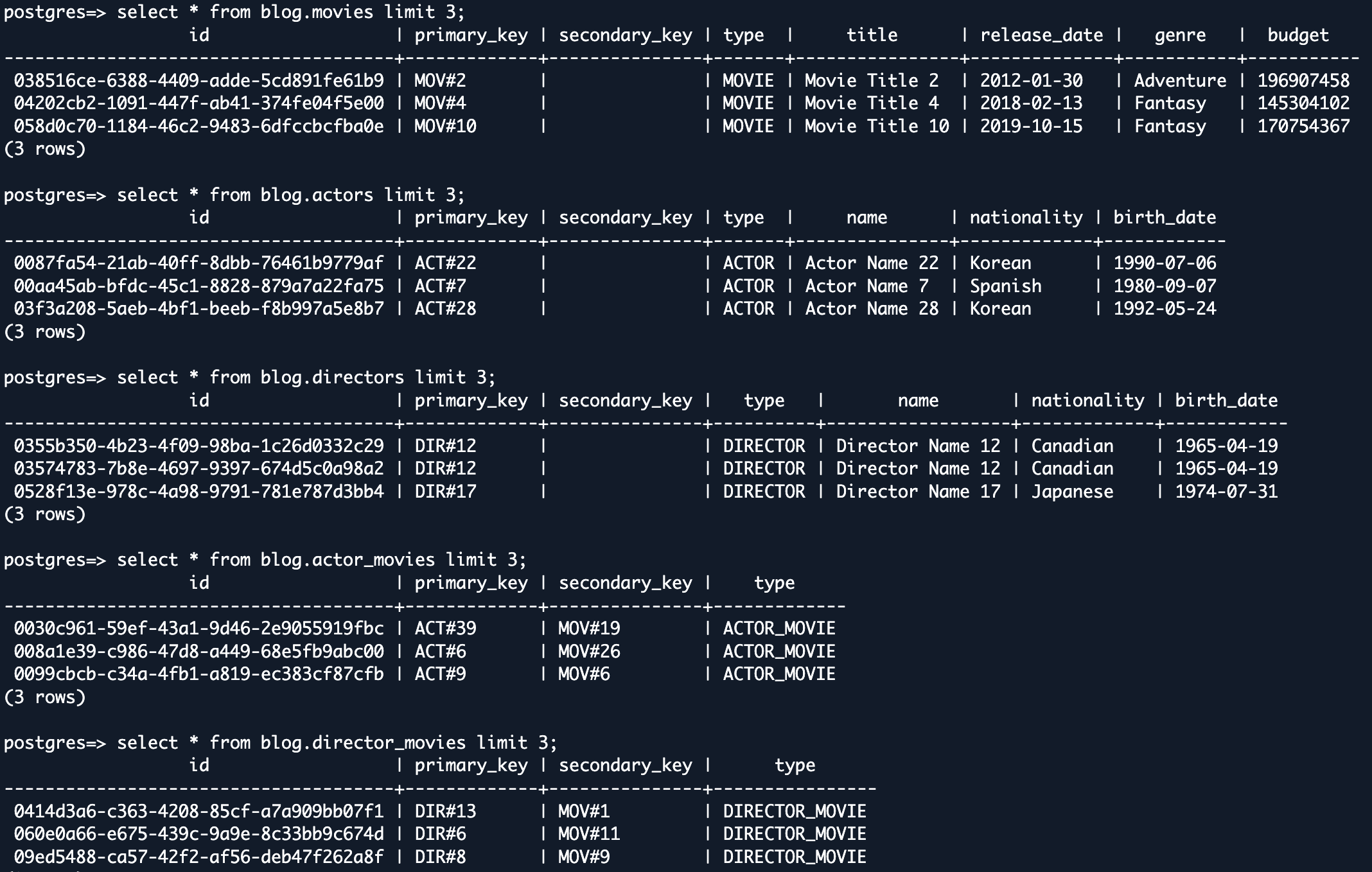
También puede implementar metodologías de validación de datos más rigurosas según lo desee. Al implementar una estrategia de validación integral, puede tener confianza en el éxito de su proyecto de migración de datos y mantener la integridad de sus operaciones comerciales después de la migración.
Limpieza
Para ayudar a prevenir cargos no deseados en su cuenta de AWS, elimine los recursos de AWS que utilizó para este tutorial:
- En la consola de Amazon S3, vacíe y elimine los siguientes buckets:
- En la consola de CloudFormation, elimine la pila mongodb-dsql-migration.
Esto eliminará automáticamente los recursos creados por la plantilla, incluidos:
- Clúster Aurora DSQL
- Clúster EMR
- Instancia EC2 de MongoDB
- Buckets de S3
- Componentes de VPC y redes
- Roles de IAM y grupos de seguridad
- Secreto de Secrets Manager
Conclusión
En esta publicación, demostramos la migración desde un diseño de estilo relacional NoSQL al modelo relacional de Aurora DSQL, demostrando cómo las organizaciones pueden obtener lo mejor de ambos mundos: la escalabilidad y flexibilidad que inicialmente las atrajo a NoSQL, combinadas con la robusta compatibilidad con ACID, las capacidades de consulta SQL y la integridad relacional de un sistema de base de datos tradicional. A través de nuestra migración de una base de datos de colección de películas de MongoDB a Aurora DSQL, ilustramos el proceso end-to-end, desde la identificación de entidades y el diseño del esquema hasta la ejecución y validación de ETL.
Al realizar la transición a Aurora DSQL, las organizaciones obtienen acceso a consultas SQL compatibles con PostgreSQL. Esta flexibilidad se vuelve cada vez más valiosa a medida que las aplicaciones evolucionan y surgen nuevos requisitos de consulta. Además, la arquitectura serverless de Aurora DSQL, con su SLA de 99.99% de disponibilidad en una sola región y 99.999% en múltiples regiones, proporciona la confiabilidad y escala que demandan las aplicaciones empresariales sin la sobrecarga operativa de administrar la infraestructura de la base de datos. La integración de herramientas de IA generativa como Kiro CLI a lo largo del proceso de migración, desde la generación de DDL hasta la creación de scripts ETL y el desarrollo de consultas de validación, demuestra cómo la asistencia de IA generativa puede reducir significativamente el tiempo y la complejidad tradicionalmente asociados con las migraciones de bases de datos.
Aurora DSQL combina capacidades SQL distribuidas con escalabilidad NoSQL, lo que la hace ideal para aplicaciones modernas. Este enfoque proporciona una plantilla práctica para las organizaciones que buscan maximizar sus capacidades de datos relacionales mientras mantienen la eficiencia operativa que requieren las aplicaciones modernas. Pruebe la solución para su propio caso de uso y comparta sus comentarios en los comentarios.
Acerca de los autores
 |
Fernando IbanezFernando es un Arquitecto de Soluciones con sede en Carolina del Norte en el equipo de Educación Superior. Fernando disfruta ayudando a los clientes a diseñar e implementar soluciones de automatización para simplificar el uso de su nube. En su tiempo libre, Fernando disfruta ir al teatro, probar nuevas cocinas y pasar tiempo con su familia. |
 |
Ramesh RaghupathyRamesh es un Arquitecto de Soluciones Senior en AWS, apoyando a clientes de Tecnología Educativa en su viaje de transformación en la nube. Como experto en Datos e IA, aporta una amplia experiencia en la construcción de soluciones en este espacio. Fuera del trabajo, Ramesh disfruta viajar, practicar yoga y pasar tiempo con su familia. |
Este contenido ha sido traducido de la publicación original del blog, que se puede encontrar aquí.
Acerca del traductor
Marcelo Ahuerma es Arquitecto de Soluciones Sr. en el sector público de AWS, con más de 20 años de experiencia en seguridad informática y arquitectura tecnológica en México y Estados Unidos. Su enfoque principal es el sector de Tecnologías para la Educación (EdTech), donde ayuda a sus clientes a optimizar sus cargas de trabajo en la nube.