AWS Partner Network (APN) Blog
Scale AI application in production: Build a fault-tolerant AI gateway with SnapSoft
By: Gergely Szlobodnyik, Head of AI & ML – SnapSoft
By: Lu Zou, Sr. WW Partner Solutions Architect – AWS
 |
| SnapSoft |
 |
Production AI applications face unique scaling challenges. When you build generative AI applications, you integrate multiple AI models from various providers. Each provider sets model-specific quotas and regional endpoints. Under unpredictable workloads, your architecture must handle thousands of concurrent requests without service disruptions.This post introduces an AI gateway solution. The AI gateway creates a resilient, fault-tolerant architecture by routing requests across multiple providers, accounts, and AWS Regions. You can scale confidently without hitting quota limits or experiencing provider outages.
You’ll learn the architecture at multiple layers:
-
- Logical architecture – Understand how the gateway routes requests to AI endpoints
- Amazon Web Services (AWS) solution architecture – Configure auto scaling, load balancing, health checks, and dynamic failover
- Real-world implementation – Learn how one company migrated to production successfully
Common Challenges in Scaling AI Applications in Production
Single-provider architectures create critical risks. Most organizations start with one AI provider and endpoint. This approach works for prototypes but fails at scale. Consider these common challenges:
-
-
- Provider dependency – A single endpoint can’t guarantee service when workloads scale unpredictably. Provider outages leave your entire application unavailable. You have no fallback when your primary provider experiences issues.
- Quota limitations – Each provider sets account-level or subscription-level quotas. When you reach these limits, the provider throttles or rejects requests. This causes immediate service outages. Many providers offer soft limits that you can request to increase. However, quota increases require manual approval and can take days or weeks. You can’t increase quotas automatically when traffic spikes.
- Noisy neighbor problem – When multiple applications share the same AI endpoint, they compete for resources. One application’s traffic spike affects all other applications. You can’t isolate workloads or guarantee capacity for critical applications.
- Manual failover – When endpoints fail or quotas are exceeded, you must manually switch to backup providers. This requires operator intervention and causes extended downtime. You can’t respond quickly to production incidents.
- Regional limitations – Providers offer models in specific regions. Regional outages or high latency affect your application performance. You can’t automatically route to the best-performing endpoint.
-
These challenges require a new architectural approach. The AI gateway addresses each challenge through multi-provider routing, automatic failover, and distributed quota management.
SnapSoft’s AI Gateway Logical Architecture
The AI gateway uses a multistep routing mechanism. The gateway selects the best model provider, AI model, account, and regional endpoint for each request. This dynamic routing means your requests reach available endpoints, even when quotas are exceeded or endpoints fail.
Figure 1 shows the routing mechanism. The gateway routes requests through four selection steps:
-
-
- Provider selection – You can integrate multiple model providers, including cloud and on-premises solutions. The provider selector automatically routes requests to providers with available endpoints.
- Model selection – After you choose a provider, you configure which model to use. The gateway routes requests to that model’s endpoint instances. You can reconfigure models in real time. The provider selector skips providers without available endpoints for your configured model.
- Account selection – The account selector tracks quota usage and consumption for each model. When an account reaches its quota limit, the selector fails over to other accounts with equivalent endpoints. This provides high availability. For example, an AWS account tracks quota status, including request count and tokens. In Amazon Bedrock, model quotas apply per account across all geographic AWS Regions where the model is available.
- Regional endpoint selection – The Region selector routes requests to specific endpoint instances. You can choose Regional endpoints with the best latency and throughput characteristics.
-

SnapSoft’s AI Gateway AWS Solution Architecture
The AI gateway uses a hub-and-spoke architecture. Each hub connects to a specific model provider: Amazon Bedrock, third-party APIs, or on-premises models. All hubs share a single entry point and DNS routing mechanism.
Amazon API Gateway serves as the single entry point. You can configure authentication, authorization, and rate limits through usage plans. An AWS Lambda function acts as the gateway proxy and routes requests. The function uses provisioned concurrency for high availability and connects to a virtual private cloud (VPC) for secure network access. The function can also filter content before forwarding requests.
A private hosted zone in Amazon Route 53 enables dynamic routing. The zone contains weighted alias records that point to Network Load Balancer endpoints for each provider hub. The Lambda function queries Amazon Route 53 resolver for available endpoints. The resolver returns only healthy Network Load Balancer IP addresses. Health checks run every 10 seconds to provide fast failover. The weighted alias records distribute requests uniformly across all healthy hubs with low time to live (TTL) (10 seconds) for fast DNS convergence.
Each provider has a dedicated hub-and-spoke module. The hub performs load balancing, health checking, and automatic failover. Spokes represent independent AWS accounts with separate quota limits. Each hub uses a Network Load Balancer that routes traffic to spoke accounts through AWS Transit Gateway. The Network Load Balancer performs health checks on spoke endpoints using the /healthz endpoint.
Each spoke contains a Network Load Balancer with static IP addresses and an AWS Fargate service. The Fargate service hosts the containerized application that forwards requests to AI endpoints. The service auto scales based on incoming request volume. The application provides two endpoints: /healthz for health checks and /inference for forwarding requests. The application includes backoff strategies, Regional failover, and model failover capabilities.
The architecture supports three provider types:
-
-
- Amazon Bedrock (recommended) – Amazon Bedrock provides more than 100 on-demand models from Anthropic, Meta, Cohere, Mistral AI, and others. Bedrock uses the AWS backbone network for low latency and offers cross-Region inference for automatic Regional failover. The hub-and-spoke architecture distributes load across multiple AWS accounts to overcome account-level quota limits. We recommend Amazon Bedrock as your primary provider for production workloads.
- Third-party APIs – You can integrate third-party providers such as OpenAI, Anthropic, and DeepSeek. Store API keys in AWS Secrets Manager for secure access. Third-party integration requires internet connectivity and might have higher latency compared to Amazon Bedrock. Use third-party APIs to supplement Amazon Bedrock when you need access to specific models.
- On-premises models – You can connect self-hosted models in your data center through VPN connections with SSL/TLS encryption. Transit Gateway serves as the AWS VPN endpoint. On-premises integration enables cost-efficient hosting of smaller, high-performing models. This option works well when you have existing infrastructure or need full control over model deployment.
-
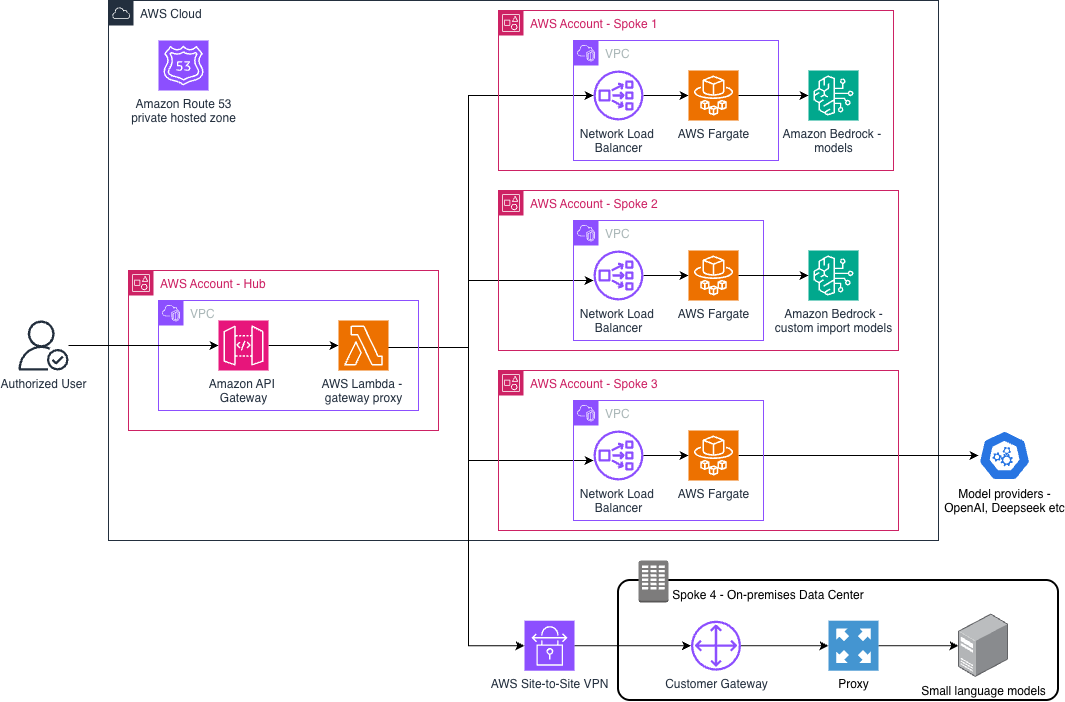
Although this diagram focuses on core components, a production deployment should include additional security controls. Implement authentication using Amazon Cognito at the API gateway, enforce TLS encryption across all communications, and apply rate limiting with AWS WAF to prevent abuse. Store third-party API keys in AWS Secrets Manager. For AI-specific security controls such as content filtering and prompt injection prevention, implement Amazon Bedrock Guardrails. Finally, enable Amazon CloudWatch and AWS CloudTrail for monitoring and incident detection.
Case Study
GDE-MIT builds an EdTech platform that helps thousands of students learn through AI-powered chat. To use the platform, schools upload documents to create knowledge bases and students ask questions about subjects, lectures, and books. The platform ran on Microsoft Azure with a single OpenAI endpoint. This architecture created critical risks. When OpenAI experienced outages, the entire service went down. The single endpoint couldn’t handle production-scale traffic, and quota limits caused frequent throttling. GDE-MIT needed a resilient, scalable solution before expanding to more schools.
SnapSoft assessed the architecture and identified critical gaps by mapping GDE-MIT’s IT landscape and analyzing the data and AI architecture. The assessment identified inefficiencies in business continuity, fault tolerance, latency, and cost. SnapSoft recommended migrating to AWS and implementing the AI gateway solution to address these gaps.
The AI gateway eliminated single points of failure. The gateway routes requests across Amazon Bedrock, third-party APIs, and on-premises models. When one provider fails or reaches quota limits, traffic automatically fails over to available endpoints. The solution distributes load across multiple AWS accounts with independent quotas. The platform now achieves:
- High availability – Significantly reduces service interruptions from provider outages
- Substantial cost reduction – Amazon Nova models offer substantial cost savings compared to GPT-4.5
- Significant throughput improvement – Load balancing across multiple endpoints can increase aggregate tokens per minute
- Improved latency – AWS backbone network reduces time to first token compared to internet-facing communication
- Enhanced security – Reduced attack surface through private AWS network instead of public internet
- Production scale – Handles hundreds of thousands of requests per day
The AI gateway allows GDE-MIT to scale confidently while maintaining continual availability and controlling costs.
Conclusion
The AI gateway solves the critical challenges of production AI applications. The multi-provider architecture eliminates single points of failure by routing requests across providers, accounts, and Regions. When quota limits are reached or endpoints fail, automatic failover occurs in seconds. Health checks run continually to detect and route around unhealthy endpoints. You can combine the Amazon Bedrock low-latency backbone network with third-party APIs and cost-efficient on-premises models.
Key benefits:
- Automatic failover – Routes to healthy endpoints when quota limits are reached or providers fail
- Multi-provider support – Integrates Amazon Bedrock, third-party APIs, and on-premises models
- Fast recovery – Detects and routes around unhealthy endpoints in seconds
- Quota management – Distributes load across multiple accounts to prevent exhaustion
- Noisy neighbor prevention – Isolates applications through account-level separation
- Cost optimization – Balances expensive third-party APIs with cost-efficient on-premises models
- Minimize manual intervention – Scales automatically without operator involvement
You can scale to serve millions of users without manual quota management or service disruptions. The architecture delivers the high availability and resilience your production applications require. To learn more about implementing the AI gateway architecture described in this post, contact the SnapSoft team. Their experts can help you assess your current AI architecture and design a fault-tolerant gateway tailored to your production requirements.
New to AWS? Become an AWS Partner to build, market, grow and scale your business.
.

.
SnapSoft – AWS Partner Spotlight
SnapSoft is an AWS Premier Tier and AWS Competency Partner that excels in cloud migrations, GenAI, DevOps, and application development, enabling startups, SMBs, and enterprises to seamlessly deploy AI, transition to AWS, and improve DevOps speed while driving innovation, reducing costs, and enhancing security.