AWS Partner Network (APN) Blog
Testing AWS GameDay with AWS Well-Architected Framework – Remediation
Editor’s note: This is the second in a two-part series about testing AWS GameDay. Read Part 1 >> Read Part 3 >>
By Ian Scofield, Juan Villa, and Mike Ruiz, Partner Solutions Architects at AWS
 This is the second post in our series documenting a project to fix issues with the GameDay architecture by using tenets of the AWS Well-Architected Framework. See Part 1 of the series for an overview of the process, a description of the initial review, and a list of the critical findings identified by the review team.
This is the second post in our series documenting a project to fix issues with the GameDay architecture by using tenets of the AWS Well-Architected Framework. See Part 1 of the series for an overview of the process, a description of the initial review, and a list of the critical findings identified by the review team.
In this post, we’ll cover the steps we took to fix the critical findings identified by the review team. In future posts, we will share our plans to refine our architecture through continuous improvement and collaboration with AWS solutions architects.
Learn more about AWS Gameday >>
Findings
As noted in Part 1 of the serires, the review team delivered a list of critical findings we needed to prioritize and fix immediately, as well as a list of non-critical ideas that we should consider addressing in our roadmap for the GameDay architecture.
Here were the critical items:
- The legacy administrative scripts for GameDay use AWS access keys and secret access keys that are stored in plain text in an Amazon DynamoDB table.
- The load generator is a single instance in a single Availability Zone (AZ) without any recovery options configured.
- The disaster recovery (DR) plan is not clearly defined, and the recovery point objectives (RPO) and recovery time objectives (RTO) are not set. Also, the disaster recovery plan isn’t periodically tested against the RPO and RTO objectives.
The review team noted they would welcome a chance to review plans for remediation before implementation, so we set to work analyzing the deficiencies, documenting our plans, and making a rough estimate of the level of effort required to implement the fixes before making any changes.
Here is the high-level remediation plan we came up with to address the critical findings, in order of priority:
- Implement the use of cross-account roles to eliminate the usage of access and secret keys.
A quick review of the code suggested that we should allocate one day to develop and test cross-account access, and another day to update the instructions and train staff on the new feature. Since this fix seemed relatively simple and provided both security and operational benefits, we decided to set it as the highest priority to be integrated into the new design.
- For the load generator, move from a single instance to a container model that would allow for a clustered deployment.
This change was a little more complicated than the previous access key fix. We needed to modify our application to store state in DynamoDB instead of writing locally, and we needed to package our various applications and binaries into Docker containers. We planned to create an Amazon EC2 Container Service (Amazon ECS) task definition and service for each of these components, which would take care of the scheduling and task placement for us. Switching to DynamoDB and containers would enable us to move our hard-coded configuration to an Auto Scaling group launch configuration, remove all hard-coded values in favor of variables set at launch, and use AWS CloudFormation templates for the deployment mechanism.These changes would net considerable improvements and have little impact on the overall flow of the game, although we did have to update the load management tool and game setup scripts to use DynamoDB and the Auto Scaling group rather than a static configuration file.We allocated two weeks to develop and test these new features, and one week to update our documentation and train staff on the new operation.
- Create a disaster recovery plan and validate it.
Automating our infrastructure deployment with Amazon ECS and Auto Scaling groups simplified our disaster recovery plan, but it wasn’t a complete solution. There were still gaps in our recovery process and furthermore, having a solution but not testing it, or, at a minimum, walking through various scenarios, would leave us vulnerable to process gaps when the time came to put the plan into action. We allocated an additional week to create the plan, and an additional day to verify that all contingencies were covered and rehearsed.
We shared our plans with the review team before starting this work, to ensure that we were on the right track to meet all the requirements. The review team gave us the thumbs up, and we began putting our plan into action.
Initial Analysis and Rearchitecture
Although the list seemed straightforward, we quickly realized that these items pointed to a common underlying problem: our architecture was very simplistic, dated, and did not make good use of the modern features provided by the AWS platform. When we initially built GameDay, we focused on functionality and built an environment based on previous experience. However, the architecture didn’t really embrace modern tools or techniques, like the notion of building for failure, and anticipating the need for better disaster recovery capabilities.
With this in mind, we realized that we should attack this core architectural issue, which would, in turn, solve a majority of the critical findings as well as a large number of the non-critical recommendations. To achieve this, we moved from a single instance load generator to Docker containers running in an Amazon ECS cluster (see diagram below). This immediately gave us the benefit of a Multi-AZ architecture and the ability to scale our infrastructure and handle the loss of components. We also modified additional services from the load generator to be run as AWS Lambda functions, which handle scaling and infrastructure management automatically.
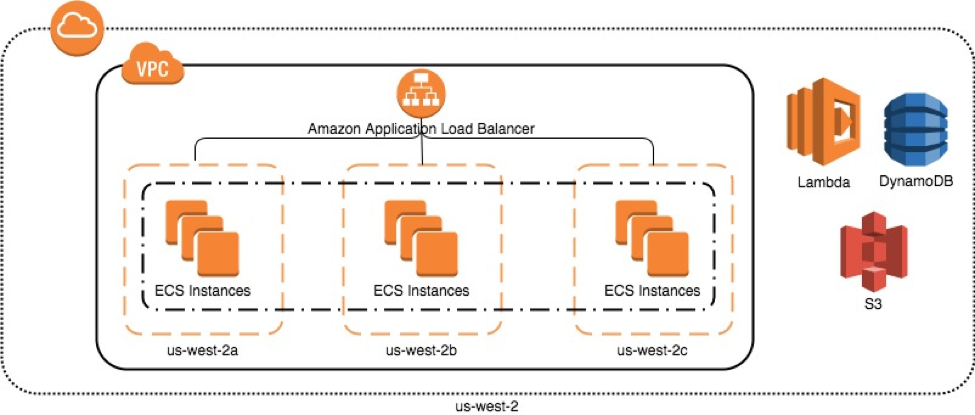
Updated Amazon ECS architecture
While pursuing this new architecture, we realized that our previous deployment process involved manual creation of resources and configuration. We took a hard stance from the start to treat our infrastructure as code and used AWS CloudFormation to define our environment. This allowed us to easily version our infrastructure as we progressed through the remediation phase, and also played a critical role in developing our new disaster recovery plan.
Remediation
Issue 1: AWS Access Keys
Surprisingly, this item turned out to be the easiest to address. AWS provides a feature to enable role-based access between accounts. Since we had already automated the configuration of both the admin and player accounts with AWS CloudFormation, it seemed simple to update the template to create a role rather than an access/secret key pair in the player account.
We initially thought it would be a massive undertaking to modify our entire code base to use sts:AssumeRole, but this turned out to be trivial. Because we used the AWS SDKs, and both access keys and IAM roles are part of the default credential provider chain and fully supported by the SDK, the only change we had to make was to remove the access keys and pass in the role ARN to assume.
Issue 2: Load Generator
We solved this issue by moving from a single EC2 instance to an Amazon ECS cluster. To do this, we had to modify the application to externally store team and player data. Since we were already using Amazon DynamoDB for other metadata, we chose it for this purpose as well. Moving the state to DynamoDB and polling for configuration was essential, as the load generator containers were now ephemeral, and we didn’t want to create a new service to track members, but just to push updates.
Amazon ECS enabled us to operate our load generator as a service within Amazon ECS, so we could scale the application throughout the game without having to manage a complex, distributed, configuration management tool. It also provided us with additional fault tolerance by scheduling and placing tasks across three Availability Zones, and replacing containers in the event of any errors or failures.
Issue 3: Disaster Recovery
Disaster recovery was by far the most difficult remediation we attempted. The issues were not solely technical in that we had developed plans to expand the use of tools and techniques to rapidly and reliably deploy the application. However, the harder to solve challenges we encountered were things like definitions (How do we define disaster?), expectations (What is a reasonable recovery time objective?), compliance (How often do we test DR? What can we automate? Is our testing framework robust enough to tell us that our DR plan is still valid after a new release?), and ownership (Who is responsible for declaring a disaster? Who is responsible for ensuring that the process is adequately maintained over time?).
Ultimately, we decided on a phased, incremental approach rather than tackling all of these issues at once. We allocated one day to strategize a response to a simulated disaster that focused on a simulated event—loss of control of a production account—and another day to write up our findings.
The simulated test involved members of the team sitting in a room with a moderator responsible for presenting a scenario, and then simulating the recovery process with whatever materials we had at hand. The moderator would keep us honest, challenge responses, and add details as the scenario progressed. The recovery team would keep careful notes, identify gaps, lucky breaks, and areas for improvement, and ultimately document our effective RTO and RPO.
Given the scenario—total loss of control of our production account—we quickly decided that the only safe response available to us was to abandon ship and simulate recovery in an entirely new account. We happened to have an unused, largely unconfigured account we could use for this purpose, but it was clear that account creation and initial setup would need to be accounted for in our RTO. The deployment of the game assets in the new account was significantly eased by the use of the new CloudFormation templates, which, luckily, were stored in an S3 bucket owned by another AWS account that was unaffected by the breach.
Much more problematic was the recovery of the game data stored in DynamoDB. Our current backup plan was manually operated and pushed backups to an S3 bucket in the same account and AWS Region as the source data. Obviously, an attacker that had control of our primary account would also have control of our only backups. Since the backups weren’t automated and were inaccessible in the event we lost control of our account, our RPO could never be clearly defined. Simply put, we could not assure a successful recovery in this scenario.
Despite these challenges, we deemed the DR simulation to be very successful. We were able to test recovery, identify what was working (decoupling data, automating deployment with AWS CloudFormation), what needed work (automated DynamoDB backups and audit logging to an S3 bucket in a different account), and what our current, achievable RTOs and RPOs were.
Ultimately, we added the recovery and audit work to our immediate roadmap, and agreed on a future cadence of quarterly DR simulations to continue to investigate our real response capability as changes were made and new disasters were contemplated.
Conclusion
We started this process with an architecture that, now looking back, was very fragile and left us vulnerable both from a security and a disaster recovery standpoint. It was uncomfortable to have our shortcomings identified, but by having knowledgeable AWS solutions architects walk through our architecture and point out areas for improvement, we were able to document and prioritize changes. This allowed us to take a step back and examine where we needed to focus our efforts in order to provide a better experience for our customers by mitigating potential problems down the road. We now are much more confident in our architecture and know that we are better prepared for failure.
However, our GameDay application is far from perfect, as we found out in our disaster recovery simulation. Additionally, we still have recommendations on our roadmap from the initial review. As AWS comes out with new features, and best practices are updated, we’ll continue to work with other solutions architects to ensure that we are incorporating these features and practices into our architecture.
In the next post, we’ll take a look at what happened six months after we implemented the changes discussed in this post, considering that AWS released new features during that time. We’ll walk through our evaluation process of these new features to see where they can be incorporated. Additionally, we’ll discuss how we continued to work with our review team on the non-critical items.