Artificial Intelligence
Deploy fast and scalable AI with NVIDIA Triton Inference Server in Amazon SageMaker
Machine learning (ML) and deep learning (DL) are becoming effective tools for solving diverse computing problems, from image classification in medical diagnosis, conversational AI in chatbots, to recommender systems in ecommerce. However, ML models that have specific latency or high throughput requirements can become prohibitively expensive to run at scale on generic computing infrastructure. To achieve performance and deliver inference at the lowest cost, ML models require inference accelerators such as GPUs to meet the stringent throughput, scale, and latency requirements businesses and customers expect.
The deployment of trained models and accompanying code in the data center, public cloud, or at the edge is called inference serving. We are proud to announce the integration of NVIDIA Triton Inference Server in Amazon SageMaker. Triton Inference Server containers in SageMaker help deploy models from multiple frameworks on CPUs or GPUs with high performance.
In this post, we give an overview of the NVIDIA Triton Inference Server and SageMaker, the benefits of using Triton Inference Server containers, and showcase how easy it is to deploy your own ML models. If you’d like to work from a sample notebook that supports this blog post, download it here.
NVIDIA Triton Inference Server overview
The NVIDIA Triton Inference Server was developed specifically to enable scalable, rapid, and easy deployment of models in production. Triton is open-source inference serving software that simplifies the inference serving process and provides high inference performance. Triton is widely deployed in industries across all major verticals, ranging from FSI, telco, retail, manufacturing, public, healthcare, and more.
The following are some of the key features of Triton:
- Support for multiple frameworks – You can use Triton to deploy models from all major frameworks. Triton supports TensorFlow GraphDef and SavedModel, ONNX, PyTorch TorchScript, TensorRT, RAPIDS FIL for tree-based models, OpenVINO, and custom Python/C++ model formats.
- Model pipelines – The Triton model ensemble represents a pipeline of one or more models or pre- and postprocessing logic and the connection of input and output tensors between them. A single inference request to an ensemble triggers the entire pipeline.
- Concurrent model runs – Multiple models (support for concurrent runs of different models will be added soon) or multiple instances of the same model can run simultaneously on the same GPU or on multiple GPUs for different model management needs.
- Dynamic batching – For models that support batching, Triton has multiple built-in scheduling and batching algorithms that combine individual inference requests to improve inference throughput. These scheduling and batching decisions are transparent to the client requesting inference.
- Diverse CPU and GPU support – You can run the models on CPUs or GPUs for maximum flexibility and to support heterogeneous computing requirements.
The following diagram illustrates the NVIDIA Triton Inference Server architecture.
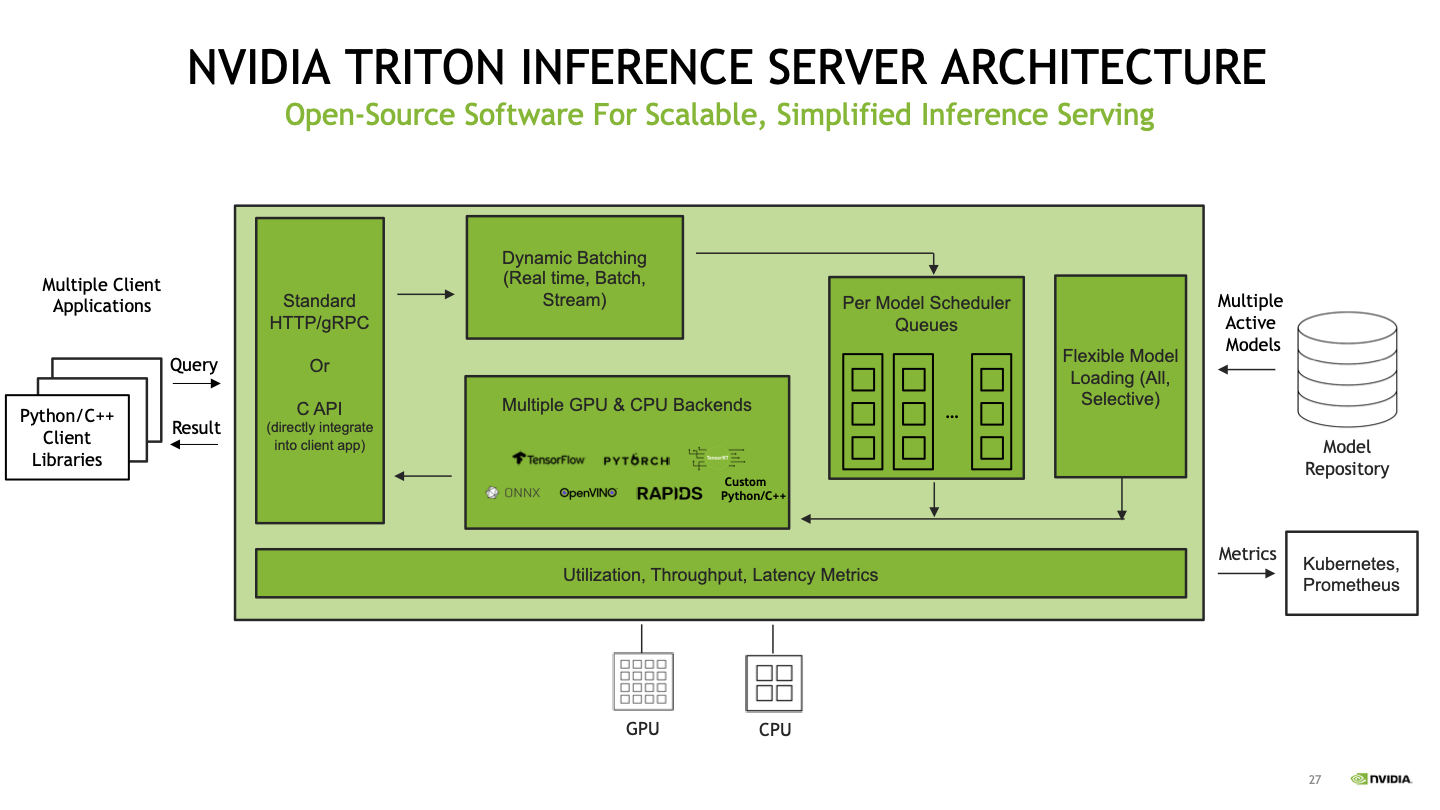
SageMaker is a fully managed service for data science and ML workflows. It helps data scientists and developers prepare, build, train, and deploy high-quality ML models quickly by bringing together a broad set of capabilities purpose-built for ML.
SageMaker has now integrated NVIDIA Triton Inference Server to serve models for inference in SageMaker. Thanks to the new Triton Inference Server containers, you can easily serve models and benefit from the performance optimizations, dynamic batching, and multi-framework support provided by Triton. Triton helps maximize the utilization of GPUs and CPUs, lowering the cost of inference.
This combination of SageMaker and NVIDIA Triton Inference Server enables developers across all industry verticals to rapidly deploy their models into production at scale.
In the following sections, we detail the steps needed to package your model, create a SageMaker endpoint, and benchmark performance. Note that the initial release of Triton Inference Server containers will only support one or more instances of a single model. Future releases will have multi-model support as well.
Prepare your model
To prepare your model for Triton deployment, you should arrange your Triton serving directory in the following format:
In this format, triton_serve is the directory containing all of your models, model is the model name, and 1 is the version number.
In addition to the default configuration like input and output definitions, we recommend using an optimal configuration based on the actual workload that users need for the config.pbtxt file.
For example, you only need four lines of code to enable the built-in server-side dynamic batching:
Here, the preferred_batch_size option means the preferred batch size that you want to combine your input requests into. The max_queue_delay_microseconds option is how long the NVIDIA Triton server waits when the preferred size can’t be created from the available requests.
For concurrent model runs, directly specifying the model concurrency per GPU by changing the count number in the instance_group allows you to easily run multiple copies of the same model to better utilize your compute resources:
For more information about the configuration files, see Model Configuration.
After you create the model directory, you may use the following command to compress it into a .tar file for your later Amazon Simple Storage Service (Amazon S3) bucket uploads.
Create a SageMaker endpoint
To create a SageMaker endpoint with the model repository just created, you have several different options, including using the SageMaker endpoint creation UI, the AWS Command Line Interface (AWS CLI), and the SageMaker Python SDK.
In this notebook example, we use the SageMaker Python SDK.
- Create the container definition with both the Triton server container and the uploaded model artifact on the S3 bucket:
- Create a SageMaker model definition with the container definition in the last step:
- Create an endpoint configuration by specifying the instance type and number of instances you want in the endpoint:
- Create the endpoint by running the following commands:
Conclusion
SageMaker helps developers and organizations across all industries easily adopt and deploy AI models in applications by providing an easy-to-use, fully managed development and deployment platform. With Triton Inference Server containers, organizations can further streamline their model deployment in SageMaker by having a single inference serving solution for multiple frameworks on GPUs and CPUs with high performance.
We invite you to try Triton Inference Server containers in SageMaker, and share your feedback and questions in the comments.
About the Authors
 Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.
Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Jiahong Liu is a Solution Architect on the NVIDIA Cloud Service Provider team. He assists clients in adopting machine learning and artificial intelligence solutions that leverage the powerfulness of NVIDIA’s GPUs to address training and inference challenges in business. In his leisure time, he enjoys Origami, DIY projects, and playing basketball.
Jiahong Liu is a Solution Architect on the NVIDIA Cloud Service Provider team. He assists clients in adopting machine learning and artificial intelligence solutions that leverage the powerfulness of NVIDIA’s GPUs to address training and inference challenges in business. In his leisure time, he enjoys Origami, DIY projects, and playing basketball.
 Eliuth Triana Isaza is a Developer Relations Manager on the NVIDIA-AWS team. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
Eliuth Triana Isaza is a Developer Relations Manager on the NVIDIA-AWS team. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
 Aaqib Ansari is a Software Development Engineer with the Amazon SageMaker Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys hiking, running, photography and sketching.
Aaqib Ansari is a Software Development Engineer with the Amazon SageMaker Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys hiking, running, photography and sketching.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.